

Hva er Hive-funksjon?
Som vi vet i dag, er Hadoop en av de allsidige teknologiene innen big data. Hadoop har muligheten til å takle store datasett, men ettersom dataveksten er proporsjonalt, blir kartreduserende programmer vanskelig. For å utføre SQL-spørsmål ble presentert i HDFS en slik teknologi introdusert av Hadoop kalt apache Hive startet av Facebook. Hive er sterkt brukt av dataanalytikeren. De er distribuert for tre funksjonaliteter, nemlig: Datasammendrag, dataanalyse på distribuert fil og dataforespørsel. Hive gir SQL-lignende spørsmål kalt HQL - språk med høyt spørring støtter DML, brukerdefinerte funksjoner. Hive-kompilator konverterer internt denne spørringen til kartreduserende jobber som forenkler arbeidet til Hadoop i å skrive komplekse programmer. Vi kan finne en bikube i applikasjoner som datavarehus, datavisualisering og ad-hoc-analyse, google analytics. Den viktigste fordelen er at de benytter seg av SQL-kunnskap, som er en grunnleggende ferdighet implementert på tvers av dataforskere og programvare fagfolk.
Ulike Hive-funksjoner i detalj
Hive støtter forskjellige datatyper som ikke finnes i andre databasesystemer. det inkluderer et kart, matrise og struktur. Hive har noen innebygde funksjoner for å utføre flere matematiske og aritmetiske funksjoner for et spesielt formål. Funksjoner i bikube kan kategoriseres i følgende typer. De er innebygde funksjoner og brukerdefinerte funksjoner.
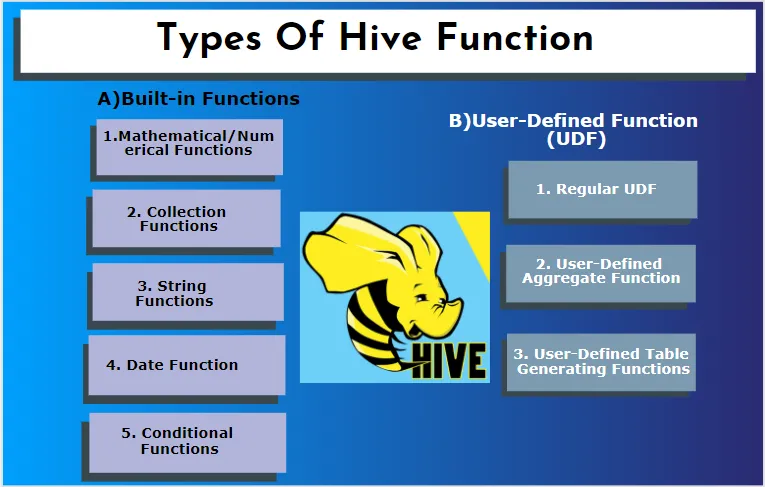
A) Innebygde funksjoner
Disse funksjonene trekker ut data fra bikubetabellene og behandler beregningene. Noen av de innebygde funksjonene er:
1. Matematiske / numeriske funksjoner
Disse funksjonene brukes hovedsakelig til matematiske beregninger. Disse funksjonene brukes i SQL-spørringer.
| Funksjonsnavn | Eksempel | Beskrivelse |
| ABS (dobbel x) | Hive> velg ABS (-200) fra tmp; | Det vil returnere den absolutte verdien av et tall. |
| CEIL (dobbelt x) | Hive> velg CEIL (8.5) fra tmp; | Det vil hente minste heltall større enn eller lik verdien x. |
| Rand (), rand (int seed) | Hive> velg Rand () fra tmp;
Rand (0-9) | Det returnerer et tilfeldig tall, avhenger av frøverdi de tilfeldige tallene som genereres ville være deterministiske. |
| Pow (dobbel x, dobbel y) | Hive> velg Pow (5, 2) fra tmp; | Den returnerer x-verdien hevet til y-effekten. |
| GULV (dobbelt y) | Hive> velg FLOOR (11.8) fra tmp; | Det returnerer et maksimalt heltall mindre enn eller lik å gi verdi y. |
| EXP (dobbelt a) | Hive> velg Exp (30) fra tmp; | Den vil returnere eksponentverdien på 30. de naturlige algoritmeverdiene. |
| PMOD (int a, int b) | Hive> velg PMOD (2, 4) fra tmp; | Det gir den positive modulen til tallet. |
2. Samlingsfunksjoner
Å dumpe alle elementene sammen og returnere enkeltelementer avhenger av datatypen som er inkludert.
| Funksjonsnavn | Eksempel | Beskrivelse |
| Map_values (Kart) | Hive> velg kartverdier ('hei', 45) | Den henter uordnede matriseelementer. |
| Størrelse (kart) | Hive> velg størrelse (kart) | Returnerer antall elementer i datatypekartet. |
| Array_contains (Array b) | Hive> velg array_concepts (a (10)) | Returnerer SANN hvis matrisen inneholder verdien. |
| Sort_array (Array a) | Hive> velg sort_array ((10, 3, 6, 1, 7)) | Sorterer inngangsarrayen i stigende rekkefølge i henhold til den naturlige rekkefølgen av arrayelementene og returnerer verdien. |
3. Strengefunksjoner
Bruke strengfunksjoner utføres dataanalyse utmerket.
| Del (streng s, streng pat) | Hive> velg split ('educba ~ hive ~ Hadoop, ' ~ ') utgang: ("educba", "hive", "Hadoop") | Den deler streng rundt klapputtrykk og returnerer en matrise. |
| last (streng s, int Len, strengpute) | Hive> velg last ('EDUCBA', 6, 'H') | Den returnerer strenger med riktig polstring med lengden på strengen. (bokstavkarakter). |
| Lengde (streng str) | Hive> velg lengde ('educba') | Denne funksjonen returnerer lengden på strengen. |
| Rtrim (streng a) | Hive> velg rtrim ('TOPIC');
Utgang: 'Emne' | Det returnerer resultatet ved å trimme mellomrom fra høyre ende. |
| Concat (streng m, streng n) | Hive> velg concat ('data', 'ware') Resultat: Dataware | Det resulterer i strengen ved å gjøre sammenkoble av to strenger, dette kan ta et hvilket som helst antall innganger. |
| Omvendt (streng) | Hive> velg revers ('Mobil') | Returnerer resultatet av en reversert streng. |
4. Datofunksjon
Det er nødvendig å ha dataformat i bikuben for å forhindre null feil i utgangen. Det er nødvendig å ha datokompatibilitet for å gå med introduserte datafunksjoner fra bikube.
| Unix_timestamp ( strengdato, strengmønster ) | Hive> velg Unix_ timestamp ('2019-06-08', 'åååå-mm-dd'); Resultat: 124576 400 tiden tatt: 0.146 sekunder | Denne funksjonen returnerer dato til det spesifikke formatet og returnerer sekunder mellom dato og Unix-tider. |
| Unix_timestamp ( strengdato ) | Hive> velg Unix_ timestamp ('2019-06-08 09:20:10', 'åååå-mm-dd'); | Den returnerer datoen i 'åååå-MM-dd HH: mm: ss' format til Unix tidsstempel. |
| Time (strengdato) | Hive> velg time ('2019-06-08 09:20:10'); Resultat: 09 timer | Den returnerer tidsstempletiden |
5. Betingede funksjoner
| If (Boolean test, T value true, t false) | Hive> velg IF (1 = 1, 'TRUE', 'FALSE') som IF_CONDITION_TEST; | Den kontrollerer med betingelsen om verdien er sann returnerer 1 og falsk returnerer 0. |
| Er ikke null (b) | Hive> Select er ikke null (null); | Dette henter ikke nulluttalelser. hvis null returnerer falsk. |
| Koalesce (verdi1, verdi2) | Eksempel: bikube> velg coalesce (null, null, 4, null, 6). den returnerer 4. | Den henter først ikke nullverdier fra listen over verdier. |
B) Brukerdefinert funksjon (UDF)
Hive bruker brukerspesifikke funksjoner i henhold til klientkrav det er skrevet i java-programmering. Det implementeres av to grensesnitt, nemlig enkel API og kompleks API. De blir påkalt fra bikubesøket. Tre typer UDF-er:
1. Vanlig UDF
Den fungerer på et bord med en enkelt rad. Det opprettes ved å opprette en java-klasse, og deretter pakke dem inn i en .jar-fil, neste trinn er å bekrefte med en bikube-sti. for deretter å utføre dem til slutt i en bikube-spørring.
2. Brukerdefinert aggregatfunksjon
De bruker aggregerte funksjoner som avg / mean ved å implementere fem metoder init (), iterate (), partial (), merge (), terminate ().
3. Brukerdefinert tabellgenereringsfunksjoner
Det fungerer med en enkelt rad i en tabell og resulterer i flere rader.
Konklusjon
Avslutningsvis har vi lært hvordan vi kan jobbe i bikupeplattformen med innebygde funksjoner og brukerdefinerte funksjoner i detalj gjennom denne artikkelen. De fleste organisasjoner har programmerer og SQL-utvikler for å jobbe med prosessen på serversiden, men en apache-bikube er et kraftig verktøy som hjelper dem å bruke Hadoop-rammeverket uten forkunnskaper om programmer og kart-redusere. Hive hjelper nye brukere å starte og utforske dataanalyse uten noen hindringer.
Anbefalte artikler
Dette er en guide til Hive-funksjonen. Her diskuterer vi konseptet, to forskjellige typer funksjoner og underfunksjoner i Hive. Du kan også gå gjennom andre foreslåtte artikler for å lære mer -
- Topp strengfunksjoner i bikube
- Spørsmål om Hive-intervju
- Hva er RMAN Oracle?
- Hva er Fossemodell?
- Introduksjon til Hive Architecture
- Hive Bestill av