

Introduksjon til datavitenskapsteknikker
I dagens verden der data er det nye gullet, er det forskjellige typer analyser tilgjengelig for en bedrift å gjøre. Resultatet av et datavitenskapelig prosjekt varierer veldig med typen tilgjengelig data, og følgelig er effekten også en variabel. Siden det er mye en annen type analyse tilgjengelig, blir det avgjørende å forstå hva noen få grunnleggende teknikker må velges. Det essensielle målet med datavitenskapsteknikker er ikke bare å søke etter relevant informasjon, men også oppdage svake koblinger som har en tendens til å gjøre at modellen kan fungere dårlig.
Hva er datavitenskap?
Datavitenskap er et felt som sprer seg over flere fagområder. Den inneholder vitenskapelige metoder, prosesser, algoritmer og systemer for å samle kunnskap og arbeide med det samme. Dette feltet inkluderer en rekke sjangre og er en vanlig plattform for forening av begreper statistikk, dataanalyse og maskinlæring. I dette arbeider teoretisk kunnskap om statistikk sammen med sanntidsdata og teknikker i maskinlæring hånd i hånd for å få fruktbare resultater for virksomheten. Ved å bruke forskjellige teknikker brukt i datavitenskap, kan vi i dagens verden antyde bedre beslutninger som ellers kan gå glipp av menneskets øye og sinn. Husk at maskinen aldri glemmer! For å maksimere fortjenesten i en datadrevet verden, er magien med Data Science et nødvendig verktøy å ha.
Ulike typer datavitenskapsteknikk
I de følgende paragrafene vil vi se på vanlige datavitenskapsteknikker som brukes i alle andre prosjekt. Selv om datavitenskapsteknikken noen ganger kan være forretningsproblemspesifikk, og kanskje ikke faller i kategoriene nedenfor, er det helt greit å betegne dem som diverse typer. På et høyt nivå deler vi teknikkene i Supervised (vi vet målpåvirkning) og Unsupervised (Vi vet ikke om målvariabelen vi prøver å oppnå). I neste nivå kan teknikkene deles mht
- Produksjonen vi ville fått eller hva er hensikten med forretningsproblemet
- Type data brukt.
La oss først se på segregering basert på intensjon.
1. Uovervåket læring
- Anomali Deteksjon
I denne typen teknikk identifiserer vi enhver uventet forekomst i hele datasettet. Siden atferden skiller seg fra den faktiske hendelsen av data, er de underliggende antagelsene:
- Forekomsten av disse tilfellene er svært liten i antall.
- Forskjellen i atferd er betydelig.
Anomali algoritmer blir forklart, for eksempel Isolasjonsskogen, som gir en poengsum for hver post i et datasett. Denne algoritmen er en trebasert modell. Ved hjelp av denne typen deteksjonsteknikk og dens popularitet blir de brukt i forskjellige forretningssaker, for eksempel websidevisninger, Churn Rate, Inntekter per klikk, etc. I grafen nedenfor kan vi forklare hvordan anomali ser ut.
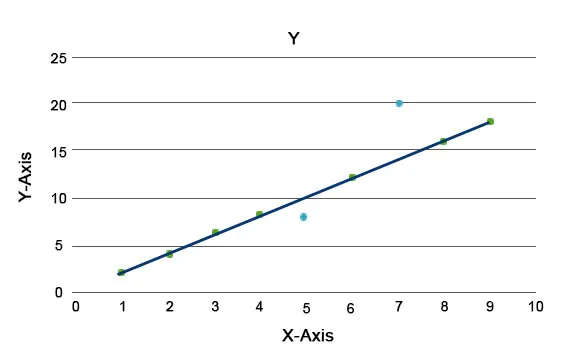
Her representerer de i blått en anomali i datasettet. De varierer fra den vanlige trendlinjen og forekommer mindre.
- Clustering Analyse
Gjennom denne analysen er hovedoppgaven å skille ut hele datasettet i grupper slik at trenden eller trekkene i ett gruppedatapunkt er ganske like hverandre. I datavitenskapets terminologi kaller vi disse som klyngen. For eksempel i detaljhandelen er det en plan for å skalere virksomheten, og det blir viktig å vite hvordan de nye kundene ville oppføre seg i en ny region basert på tidligere data vi har. Det blir umulig å utforme en strategi for hver enkelt person i en befolkning, men det vil være nyttig å skaffe befolkningen i klynger slik at strategien skal være effektiv i en gruppe og er skalerbar.
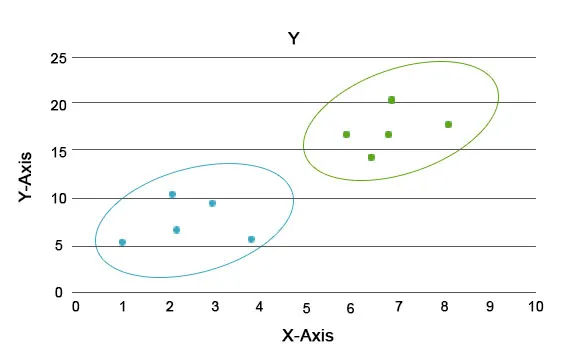
Her er de blå og oransje fargene forskjellige klynger med unike egenskaper i seg selv.
- Foreningsanalyse
Denne analysen hjelper oss med å bygge interessante forhold mellom elementer i et datasett. Denne analysen avdekker skjulte forhold og hjelper til med å representere datasettelementer i form av tilknytningsregler eller sett med hyppige elementer. Associeringsregelen er delt opp i to trinn:
- Generering av hyppig varesett: I dette genereres et sett der ofte forekommende elementer settes opp sammen.
- Regelgenerering: Settet som er bygget over føres gjennom forskjellige lag med regeldannelse for å bygge et skjult forhold mellom seg selv. For eksempel kan settet falle i enten konseptuelle eller implementeringsproblemer eller applikasjonsproblemer. Disse blir deretter forgrenet i respektive trær for å bygge foreningsreglene.
For eksempel er APRIORI en tilknytningsregelbyggingsalgoritme.
2. Veiledet læring
- Regresjonsanalyse
I regresjonsanalyse definerer vi den avhengige / målvariabelen og de gjenværende variablene som uavhengige variabler og antar til slutt hvordan en / flere uavhengige variabler påvirker målvariabelen. Regresjonen med en uavhengig variabel kalles univariat og med mer enn en er kjent som multivariat. La oss forstå å bruke univariate og deretter skalere for multivariate.
For eksempel er y målvariabelen og x 1 er den uavhengige variabelen. Så fra kunnskapen om den rette linjen, kan vi skrive ligningen som y = mx 1 + c. Her bestemmer “m” hvor sterkt y påvirkes av x 1 . Hvis “m” er veldig nær null, betyr det at med en endring i x 1, påvirkes y ikke sterkt. Med et tall større enn 1, blir virkningen sterkere og liten endring i x 1 fører til stor variasjon i y. I likhet med univariate, i multivariate kan skrives som y = m 1 x 1 + m 2 x 2 + m 3 x 3 ………., Her bestemmes virkningen av hver uavhengige variabel av den tilsvarende “m”.
- Klassifiseringsanalyse
I likhet med grupperingsanalyser er klassifiseringsalgoritmer bygget med målvariabelen i form av klasser. Forskjellen mellom gruppering og klassifisering ligger i det faktum at vi i klynger ikke vet hvilken gruppe datapunktene faller i, mens vi i klassifiseringen vet hvilken gruppe det tilhører. Og det skiller seg fra regresjon fra perspektivet at antall grupper skal være et fast antall i motsetning til regresjon, det er kontinuerlig. Det er en rekke algoritmer i klassifiseringsanalyse, for eksempel støttevektormaskiner, logistisk regresjon, beslutnings-trær, etc.
Konklusjon
Avslutningsvis forstår vi at hver type analyse er enorm i seg selv, men her kan vi gi en liten smak til forskjellige teknikker. I de neste notatene ville vi ta hver av dem hver for seg og gå inn på detaljer om forskjellige underteknikker som brukes i hver overordnede teknikk.
Anbefalt artikkel
Dette er en guide til datavitenskapsteknikker. Her diskuterer vi introduksjonen og forskjellige typer teknikker innen datavitenskap. Du kan også gå gjennom andre foreslåtte artikler for å lære mer -
- Data Science Tools | Topp 12 verktøy
- Data Science algoritmer med typer
- Introduksjon til Data Science Karriere
- Data Science vs Data Visualization
- Eksempler på multivariat regresjon
- Lag beslutnings tre med fordeler
- Kort oversikt over Data Science Lifecycle