
Oversikt over AWS RedShift
AWS gir mange funksjoner som gjør ting enklere for oss. I dette emnet skal vi lære om Hva er AWS Redshift og noen av teknologiene til AWS Redshift som er gitt nedenfor: -
- Amazon EC2
- Amazon RDS
- Amazon S3
- Amazon CloudFront
- Amazon Auto Scaling
- Amazon Lambda
- Amazon Redshift
En av de viktigste tjenestene levert av AWS og vi skal takle er Amazon RedShift. Så hva er denne RedShift, hva brukes den til, dette er de grunnleggende spørsmålene som kommer over tankene våre når vi leser dette. så la oss sjekke detaljert hva rødforskyvning er og hva den brukes til. RedShift er en virksomhetsnivå, petabyte-skala og fullstendig administrert datalagringstjeneste.
Så, hva er et datavarehus? Svaret for bor på egenhånd hvis vi vet hva et lager er generelle vilkår, generelt er et lager et sted hvor råvarer eller produserte varer kan lagres før de distribueres for salg, det samme gjelder for Data også datavarehus er et sted for å samle inn, lagre og administrere data fra forskjellige kilder og gi relevant og meningsfull forretningsinnsikt. Så Amazon tilbyr et lagerverktøy på bedriftsnivå der vi kan behandle og administrere data med REDSHIFT. Omfanget for disse datasettene varierer fra 100s gigabyte til en petabyte.
Årsaker til å bruke AWS RedShift
Så vi støter ofte på et generelt spørsmål om at hvor dette lageret var, hvor gjorde vi dette lageret, hvor gjorde vi all denne databehandlingen, lagringen og produksjonen. Tidligere da datalasten var ganske normal, pleide vi å ha fysiske servere, databaser som ble brukt og holdt oversikt over data og prosessering der, men ettersom det var en eksponentiell økning i størrelsen på dataforespørsel og håndtering av data, ble det en tøff oppgave. spørsmål begynte å ta lang tid som forventet.
Så her kom vi over behovet for amazon redshift som var mye raskere med veldig høy ytelse og skalerbarhet for lagring og produksjon av data. Den kom med massiv lagringskapasitet og gjennomsiktig priser og sikret mot forskjellige datainnbrudd. Støtter SQL-grensesnitt og forskjellige driver-ODBC / JDBC er det ganske enkelt å bruke og godt slått sammen med andre Amazon-tjenester.
Arbeid med AWS RedShift
La oss se arkitekturdiagrammet til Redshift og prøve å forstå hvordan RedShift faktisk fungerer -
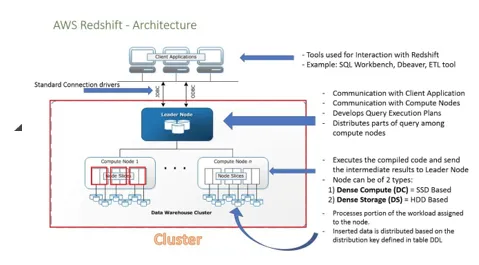
- Følgende diagram illustrerer bruken av Amazon RedShift. La oss sjekke det over detaljene: -
- For tilkobling med klientapplikasjonen har vi flere drivere som kobler til Redshift.
- Innenfor Redshift kan vi lage mer enn en klynge, og hver klynge kan være vert for flere databaser.
- Knutepunktene er delt inn i skiver hver skive har data.
- Fra tilgjengelige noder hvis vi har mer enn en node, er valgt som leder som vil være den viktigste kilden for klienten å kommunisere for. Klientapplikasjonen vil kun snakke med ledernoden, ledernoden er ansvarlig for å motta spørsmål og kommando fra klientprogrammet.
- Når ledernoden begynner å få spørsmålene utført av klienten, begynner den å analysere spørringen og bygge en plan for å få den til å kjøre på andre beregne noder. Når prosessen er distribuert til de aktuelle nodene, venter den på det endelige resultatet fra nodene før den returneres til klienten.
- Vi kan legge til antall noder og også øke minnet etter hvert som en belastning med data øker.
- Beregnede noder har et eget nettverk som klienten ikke har tilgang, noe som gjør det sikkert også.
- Det er to typer noder: Tett lagringsnode og Tette Compute Nodes, lagringskapasiteten kan variere fra 160 GB til 16 TB
Så her så vi den grunnleggende arkitekturen for hvordan REDSHIFT fungerer. La oss nå gå til hvordan du bruker for Aws Redshift.
Bruke AWS RedShift -
For å jobbe med AWS Redshift, må vi utføre noen grunnleggende trinn som er nevnt nedenfor: -
1) Logg på AWS og lag en konto der borte. (Hvis ikke)
2) Gå til Amazon Redshift-konsollen fra følgende lenke: -
https://console.aws.amazon.com/redshift/
3) Nå må vi opprette en jeg AM-rolle vi trenger for å navigere til lenken nedenfor: -
https://console.aws.amazon.com/iam/
- Gå til roller
- Velg å opprette roller.
- Velg Redshift i AWS-tjenesten
- Velg Redshift - Tilpassbar og deretter Neste: Tillatelser under velg din brukssak.
- Sett tillatelsesgrense
- Skriv inn et navn for din rolle
- Gå gjennom og opprett rolle.
4) Nå må vi lage en klynge ved å velge en regionmeny der i konsollen.
- Velg regionen der klyngen opprettes.
- Klikk på Start.
- Vi må fylle ut flere detaljer som databasenavn, passord og sjekke fortsett-knappen
- Når klyngen er synlig, sjekk det i listen og se gjennom statusinformasjonen.
- Når vi har samlet klyngen, er det neste vi må gjøre å stille inn sikkerhetsgruppen. Her må vi angi inngående regler for protokollkilde og -område.
- Sjekk den nødvendige konfigurasjonen og koble til Redshift Cluster.
5) Når vi er ferdig med alle klyngerelaterte konfigurasjoner, må vi koble til Redshift nå. Vi kan koble til denne Redshift direkte eller via SSL. For å koble den direkte må vi ha JDBC / ODBC-drivere som vi må sette den over konfigurasjonssiden for klyngen.
Når disse flere konfigurasjonene er utført pent, er vi klare til å bruke Redshift.
Fordeler med AWS RedShift -
Så hvorfor vil noen bruke AWS Redshift, det må være en fordel i forhold til andre tjenester som gjør dette spesielt. Så la oss nå sjekke noen av fordelene ved å bruke Redshift.
- Høy hastighet : - Behandlingstiden for spørringen er relativt raskere enn de andre databehandlingsverktøyene, og datavisualisering har et mye tydelig bilde.
- Masse databehandling : - Vær større, datastørrelsen redshift har muligheten til å behandle enorme datamengder på god tid.
- Minimal datatap : - Siden data distribueres over klyngen og behandles parallelt over nettverket, er det en minimumssjanse for tap av data, og nøyaktighetsgraden for de behandlede dataene er bedre.
- Kostnadseffektivt : - Å være kostnadseffektivt er det billigere enn andre tilgjengelige alternativer som gjør det sterkt over bransjebruken. Siden prisene er mindre, kan vi få plass til store datamengder og kan behandle dem innenfor budsjettet.
- SQL-grensesnitt : - Spørsmotoren basert på Redshift er den samme som for Postgres SQL som gjør det enklere for SQL-utviklere å leke med den.
- Sikkerhet : - Dataene i Redshift er kryptert som er tilgjengelige flere steder i RedShift. Vi kan også definere inngående og utgående regel som gjør dataene mye sikre.
Det er mye flere fordeler med å ha rødskift som et bedre valg for datavarehuset.
AWS RedShift Prising -
RedShift kommer med en fantastisk prisnotering som tiltrekker utviklere eller markedet mot det. Siden det kommer med en prisfunksjon på forespørsel, kan vi bruke den litt over en times basis og antall noder i klyngen vår. Spektrumprising hjelper oss å kjøre SQL Queries direkte mot alle dataene våre.
Vi kan lage store datavarehus som bruker HDD til en veldig lav pris. For mer informasjon om de nøyaktige prisopplysningene, kan du se dokumentet nedenfor av Amazon: -
https://aws.amazon.com/redshift/pricing/
Dokumentet over har alle detaljer om de forskjellige prisene for AWS REDSHIFT.
Konklusjon
Fra artikkelen ovenfor som vi så for Redshift, må vi nå ha en god ide om hva faktisk rødforskyvning er og bruken av den. RedShift er så veldig skalerbar og enkel å bruke, blir mest brukt av industrien med støtte fra forskjellige andre teknologier fra Amazon som gjør den mer kraftfull. Så i verden full av data kommer Redshift med en veldig god pakke med datavarehus og prosessering.
Anbefalte artikler
Dette er en guide til Hva er AWS RedShift. Her diskuterer vi arbeid, bruk og fordeler ved AWS RedShift. Du kan også se på følgende artikkel for å lære mer -
- AWS Arkitektur
- Hva er AWS?
- Hva er Azure?
- Hva er AWS Lambda?
- AWS Storage Services