
Introduksjon til maskinlæringsmodeller
En oversikt over ulike maskinlæringsmodeller brukt i praksis. Etter definisjonen er en maskinlæringsmodell en matematisk konfigurasjon oppnådd etter anvendelse av spesifikke maskinlæringsmetoder. Ved å bruke det store utvalget av API-er er det ganske mye å bygge en maskinlæringsmodell nå for tiden med færre linjer med koder. Men den virkelige ferdigheten til en anvendt datavitenskapsmann ligger i å velge riktig modell basert på problemstillingen og kryssvalidering i stedet for å kaste data til fancy algoritmer tilfeldig. I denne artikkelen vil vi diskutere ulike maskinlæringsmodeller og hvordan du kan bruke dem effektivt basert på typen problemer de løser.
Typer av maskinlæringsmodeller
Basert på type oppgaver kan vi klassifisere maskinlæringsmodeller i følgende typer:
- Klassifiseringsmodeller
- Regresjonsmodeller
- Gruppering
- Dimensjonsreduksjon
- Dyp læring m.m.
1) Klassifisering
Når det gjelder maskinlæring, er klassifisering oppgaven med å forutsi typen eller klassen til et objekt innenfor et begrenset antall alternativer. Utgangsvariabelen for klassifisering er alltid en kategorisk variabel. For eksempel er det en standard binær klassifiseringsoppgave å forutsi en e-post som spam eller ikke. La oss nå notere noen viktige modeller for klassifiseringsproblemer.
- K-Nærmeste naboer algoritme - enkel, men beregningsfullt.
- Naive Bayes - Basert på Bayes teorem.
- Logistic Regression - Lineær modell for binær klassifisering.
- SVM - kan brukes til binære / multiklass klassifiseringer.
- Decision Tree - " Hvis annet " -basert klassifiserer, mer robust mot outliers.
- Ensembler - Kombinasjon av flere maskinlæringsmodeller klubbet sammen for å få bedre resultater.
2) Regresjon
I maskinen er læringsregresjon et sett med problemer der utgangsvariabelen kan ta kontinuerlige verdier. For eksempel kan det å forutsi flyprisen betraktes som en standard regresjonsoppgave. La oss notere noen viktige regresjonsmodeller som brukes i praksis.
- Lineær regresjon - Enkleste basismodell for regresjonsoppgave, fungerer bra bare når data kan skilles lineært og veldig mindre eller ingen multikollinearitet er til stede.
- Lasso-regresjon - Lineær regresjon med L2-regularisering.
- Ridge Regression - Lineær regresjon med L1-regularisering.
- SVM-regresjon
- Decision Tree Regression etc.
3) Clustering
I enkle ord er gruppering oppgaven med å gruppere lignende objekter sammen. Læringsmodeller for maskiner hjelper til med å identifisere lignende objekter automatisk uten manuell inngripen. Vi kan ikke bygge effektive overvåkede maskinlæringsmodeller (modeller som må trenes med manuelt kuraterte eller merkede data) uten homogene data. Clustering hjelper oss å oppnå dette på en smartere måte. Følgende er noen av de mye brukte klyngemodellene:
- K betyr - Enkelt, men lider av høy varians.
- K betyr ++ - Endret versjon av K betyr.
- K medoider.
- Agglomerative clustering - En hierarkisk klyngemodell.
- DBSCAN - Tetthetsbasert gruppering algoritme etc.
4) Dimensjonsreduksjon
Dimensjonalitet er antall prediktorvariabler som brukes til å forutsi den uavhengige variabelen eller målet. I datamaterialets virkelige datasett er antallet variabler for høyt. For mange variabler bringer også forbannelsen av å overpasse til modellene. I praksis blant disse store antall variabler, er det ikke alle variabler som bidrar like til målet, og i et stort antall tilfeller kan vi faktisk bevare avvik med et mindre antall variabler. La oss liste opp noen ofte brukte modeller for reduksjon av dimensjonalitet.
- PCA - Det skaper færre antall nye variabler ut av et stort antall prediktorer. De nye variablene er uavhengige av hverandre, men mindre tolkbare.
- TSNE - Tilbyr innebygde nedre dimensjoner av høyere dimensjonale datapunkter.
- SVD - Nedbrytning av singulær verdi brukes til å dekomponere matrisen i mindre deler for effektiv beregning.
5) Deep Learning
Dyp læring er en undergruppe av maskinlæring som omhandler nevrale nettverk. Basert på arkitekturen i nevrale nettverk, la oss liste ned viktige modeller for dyp læring:
- Flerlags perceptron
- Convolution nevrale nettverk
- Gjentagende nevrale nettverk
- Boltzmann-maskin
- Autokodere m.m.
Hvilken modell er best?
Over tok vi ideer om mange modeller for maskinlæring. Nå kommer et opplagt spørsmål til oss "Hvilken er den beste modellen blant dem?" Det avhenger av det aktuelle problemet og andre tilknyttede attributter som utleggere, volumet av tilgjengelige data, kvalitet på data, funksjonsteknikk osv. I praksis er det alltid å foretrekke å starte med den enkleste modellen som gjelder problemet og øke kompleksiteten. gradvis ved riktig parameterinnstilling og kryssvalidering. Det er et ordtak i datavitenskapens verden - 'Kryssvalidering er mer pålitelig enn domenekunnskap'.
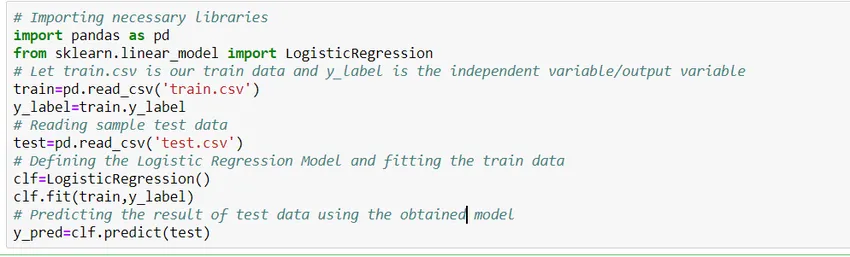
Hvordan bygge en modell?
La oss se hvordan du bygger en enkel logistisk regresjonsmodell ved hjelp av Scikit Learn-biblioteket med python. For enkelhets skyld antar vi at problemet er en standard klassifiseringsmodell og 'train.csv' er toget og 'test.csv' er henholdsvis tog- og testdata.
Konklusjon
I denne artikkelen diskuterte vi de viktige maskinlæringsmodellene som ble brukt til praktiske formål og hvordan man bygger en enkel maskinlæringsmodell i python. Å velge en riktig modell for en spesiell brukssak er veldig viktig for å oppnå riktig resultat av en maskinlæringsoppgave. For å sammenligne ytelsen mellom ulike modeller defineres evalueringsmålinger eller KPIer for spesielle forretningsproblemer, og den beste modellen er valgt for produksjon etter anvendelse av statistisk resultatkontroll.
Anbefalte artikler
Dette er en guide til maskinlæringsmodeller. Her diskuterer vi Topp 5 typer maskinlæringsmodeller med definisjonen. Du kan også gå gjennom andre foreslåtte artikler for å lære mer -
- Læringsmetoder for maskiner
- Typer maskinlæring
- Maskinlæringsalgoritmer
- Hva er maskinlæring?
- Hyperparameter maskinlæring
- KPI i Power BI
- Hierarkisk Clustering Algorithm
- Hierarkisk klynging | Agglomerative & Divisive Clustering