

Introduksjon til Python Regex
Python er buzzword i teknologibransjen i dag. Det er et språk som får stadig større popularitet. Det er et veldig dynamisk språk og kan brukes til å bygge webapplikasjoner til maskinlæringsalgoritmer. I denne artikkelen skal vi lære om hvordan Regex brukes i Python. En regex er en kort form for Regular Expression, og det er i utgangspunktet en sekvens med tegn som kan brukes som et mønster. Det fine er at Python har sin egen innebygde Regex-pakke kjent som re.
syntaks:
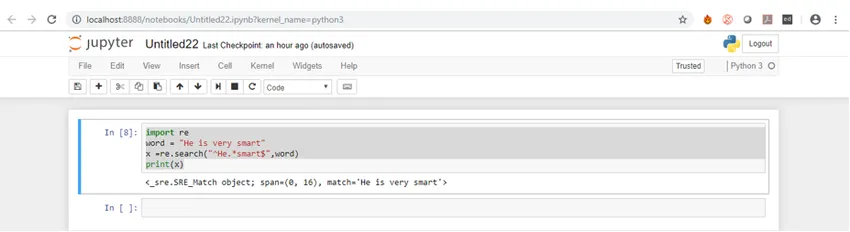
Vi kommer til å forstå syntaksen med et eksempel. Eksemplet på dette kan vi søke i en streng for å se om det begynner med “Han” og slutter med “smart”.
import reword = "He is very smart"
x =re.search("^He.*smart$", word)
print(x)
Hvis du ser på syntaks er det veldig enkelt, du må bare importere regex-pakken som er ny, og deretter bruke noen av funksjonene til den importerte pakken i henhold til kravet ditt. Hvis vi kjører ovennevnte eksempelskode i Jupyter, får vi resultatet nedenfor.
Regex-funksjoner i Python
Det er mange regex-funksjoner som hjelper oss å søke i en streng for en kamp. Før det lærer vi først karakterene vi vanligvis ser i en regex-funksjon.
|
() | Det representerer et sett med tegn. |
|
. | Det representerer alle tegn bortsett fra en ny linje. |
|
* | Det representerer null eller flere forekomster. |
|
+ | Det representerer en eller flere forekomster. |
|
^ | Det representerer startkarakteren |
|
$ | Det representerer sluttkarakteren. |
|
| |
Det representerer enten-eller. |
|
() |
Det representerer fangst og gruppe. |
| \ |
Det brukes vanligvis til å unnslippe spesialtegn |
Regex har også noen spesielle sekvenser som vil være nyttige å vite for eksempel:
|
\ w | Det viser en kamp hvis strengen har noen sett med ordtegn fra (0-9), AZ eller az og understrek. |
|
\ W | Det returnerer en kamp hvis strengen ikke har noen ordtegn til stede. |
|
\ d | Disse returene stemmer overens når det er sifre i strengen. |
|
\ D | Det er motsatt av det forrige da det returnerer samsvar hvis det ikke er siffer i strengen. |
|
\ s | Den brukes til å se etter tegn på hvite mellomrom i en streng. Det returnerer samsvar hvis det er hvite mellomromstegn. |
|
\ S | Det returnerer samsvar når det ikke er hvite mellomrom i strengen. |
Funksjoner brukt for Regex Operations
La oss se forskjellige funksjoner i re-modulen som kan brukes til regex-operasjoner i python.
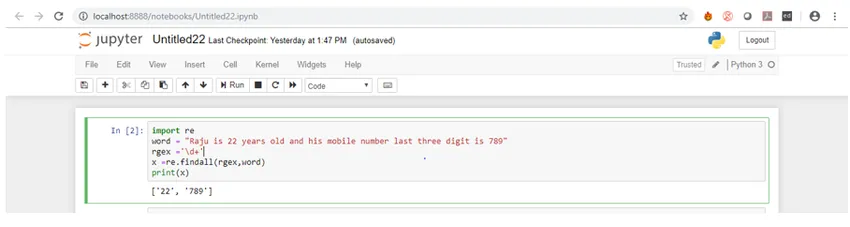
1. findall () -funksjon: Denne funksjonen er til stede i re-modulen. Den returnerer en liste over alle kamper som er til stede i strengen. Den itererer fra venstre til høyre på tvers av strengen. Kampene blir også returnert i nøyaktig samme rekkefølge. Vi vil gå gjennom et eksempel på dette. Anta at vi ønsker å finne alle sifrene som er til stede i en streng. For dette vil vi bruke findall () -funksjonen der vi finner alle sifrene som er til stede i strengen. La oss se koden for dette nå:
Kode:
import re
word = "Raju is 22 years old and his mobile number last three-digit is 789"
rgex ='\d+'
x =re.findall(rgex, word)
print(x)
Hvis vi går gjennom koden, blir vi i utgangspunktet tildelt det variable ordet med en streng som inneholder sifre, og deretter passerer det riktige regex-symbolet for sifre sammen med det variable ordet som argumenter i funksjonen findall ()
La oss se resultatet.
Som du ser får vi en liste over tall som resultat.
2. search () -funksjon: Søkefunksjonen brukes til å søke i mønstre i en streng, og hvis en match blir funnet returnerer den objektet. En ting vi må huske her er at hvis det er mer enn en kamp, returnerer den bare den første forekomsten. Hvis ingen kamp blir funnet, returnerer den ingen. Vi vil se et eksempel på dette hvis vi vil finne strengen som starter med et bestemt ord. Vi vil teste både positive og negative samsvarstilfeller. La oss se koden for den samme.
Kode:
import re
word = "Raju is 22 years old"
rgex ='^Raju'
x =re.search(rgex, word)
print(x)
regex1= '^Mohan'
x1 = re.search(regex1, word)
print(x1)
Her brukes variabel 'regex' i et positivt scenario og variabelen 'regex1' for et negativt scenario. Nå kan du se utdataene.
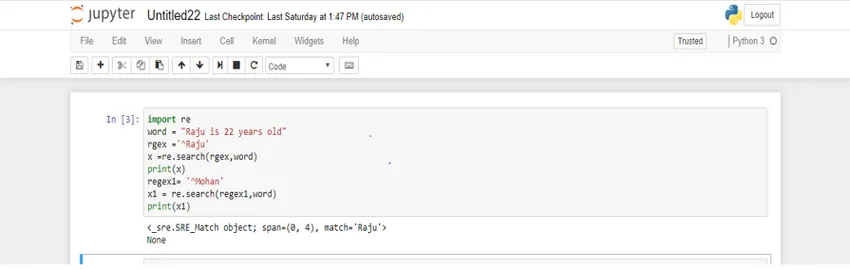
I det første tilfellet får vi matchobjektet returnert mens vi i det andre tilfellet får 'Ingen' tilbake.
3. Split () -funksjon: Denne funksjonen deler strengen etter hver kamp, noe som betyr at så snart det er et fyrstikk i strengen, splitter denne funksjonen strengen derfra. Så hvis det er tre kamper, vil det være tre splitter. Vi får se et eksempel. Anta at vi vil dele en streng etter hvert mellomrom. Så vi kan bruke denne delte funksjonen til god bruk i den situasjonen.
Kode:
import re
word = "Raju is 22 years old"
rgex ='\s'
x =re.split(rgex, word)
print(x)
Her representerer mønstrene hvit romkarakter. La oss nå se resultatet.
Som du kan se i utdelingen blir strengen delt etter hvert mellomrom.
4. sub () -funksjon: Denne funksjonen erstatter fyrstikkene med strengen eller tegnet til brukernes valg. Det betyr i utgangspunktet at hvis det er et samsvar i strengen, vil det erstatte det matchede tegnet eller strengen med strengen eller tegnet ditt og returnere den endrede strengen. Det tar tre argumenter. For eksempel vil vi bare erstatte det hvite området med '&' i strengen vår.
Kode:
import re
word = "Raju is 22 years old"
rgex ='\s'
x =re.sub(rgex, '&', word)
print(x)
La oss nå se på output for koden ovenfor.
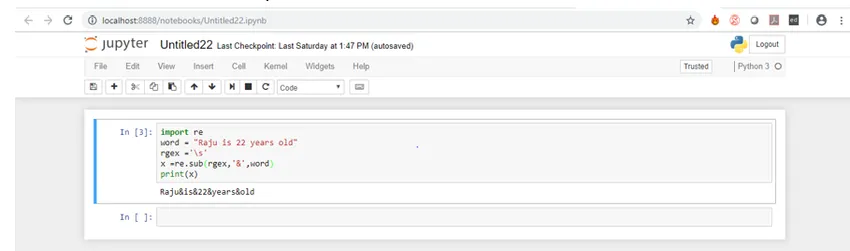
Som du kan se, ble alle mellomrom erstattet av '&'.
Konklusjon
I denne artikkelen diskuterte vi regex-modulen og dens forskjellige Python-innebygde funksjoner. Regex er veldig viktig og brukes mye i forskjellige programmeringsspråk.
Anbefalte artikler
Dette er en guide til Python Regex. Her diskuterer vi Introduksjon til Python Regex og noen viktige regexfunksjoner sammen med et eksempel. Du kan også gå gjennom de andre foreslåtte artiklene våre for å lære mer–
- Mens Loop i Python
- Omvendt nummer i Python
- Python nøkkelord
- Python-sett
- PHP nøkkelord
- C ++ nøkkelord