

Introduksjon til Decision Tree in Data Mining
I dagens verden på "Big Data" betyr begrepet "Data Mining" at vi må se nærmere på store datasett og utføre "gruvedrift" på dataene og få frem den viktige juicen eller essensen i det dataene vil si. En veldig analog situasjon er kullgruvedrift der forskjellige verktøy kreves for å gruve kullet som ligger gravlagt dypt under bakken. Av verktøyene i Data mining er “Decision Tree” et av dem. Dermed er data mining i seg selv et stort felt der de neste par avsnittene vi dypdykker ned i Decision Tree “verktøyet” i Data Mining.
Algoritme av beslutningstreet i datamining
Et beslutnings tre er en veiledet læringsmetode der vi trener dataene til stede med å allerede vite hva målvariabelen faktisk er. Som navnet antyder har denne algoritmen en tre-type struktur. La oss først se på det teoretiske aspektet av beslutningstaket og deretter se på det samme i en grafisk tilnærming. I Decision Tree deler algoritmen datasettet i delmengder på grunnlag av det viktigste eller viktigste attributtet. Det mest betydningsfulle attributtet er angitt i rotnoden, og det er der splittelsen foregår av hele datasettet som er til stede i rotnoden. Denne delingen er kjent som beslutningsnoder. I tilfelle ikke mer splittelse er mulig at noden betegnes som en bladknute.
For å stoppe algoritmen for å nå et overveldende stadium, benyttes et stoppkriterium. Et av stoppkriteriene er minimum antall observasjoner i noden før splittelsen skjer. Når du bruker avgjørelsestreet ved deling av datasettet, må man være forsiktig med at mange noder bare har støyende data. For å imøtekomme en tidligere eller støyende dataproblemer, bruker vi teknikker kjent som Data beskjæring. Beskjæring av data er ikke annet enn en algoritme for å klassifisere data fra delmengden som gjør seg vanskelig å lære av en gitt modell.
Decision Tree-algoritmen ble utgitt som ID3 (Iterative Dichotomiser) av maskinforskeren J. Ross Quinlan. Senere ble C4.5 løslatt som etterfølgeren til ID3. Både ID3 og C4.5 er en grådig tilnærming. La oss nå se på et flytdiagram av Decision Tree-algoritmen.
For vår pseudokodeforståelse vil vi ta "n" datapunkter som hver har "k" -attributter. Under flytskjemaet blir husket "Informasjonsgevinst" som betingelsen for en splittelse.
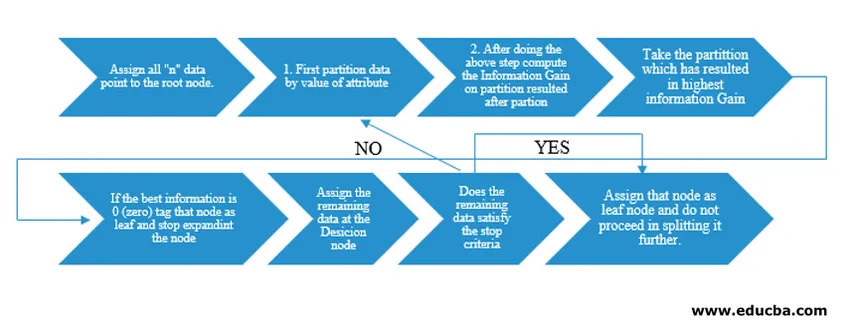
IG (on individual split) = Entropy before the split – Entropy after a split (On individual split)
I stedet for Information Gain (IG), kan vi også bruke Gini-indeksen som kriteriene for en splittelse. For å forstå forskjellen mellom disse to kriteriene i lekmannsbetegnelser kan vi tenke på denne informasjonsgevinsten som Differanse av entropi før splittelsen og etter splittelsen (delt på grunnlag av alle tilgjengelige funksjoner).
Entropi er som tilfeldighet og vi vil nå et punkt etter splittelsen for å ha minst mulig tilfeldighet. Derfor må informasjonsgevinst være størst for funksjonen vi ønsker å dele opp. Ellers hvis vi ønsker å velge å dele på basis av Gini-indeksen, ville vi finne Gini-indeksen for forskjellige attributter, og ved å bruke de samme finner vi ut vektet Gini-indeks for forskjellige splitt og bruker den med høyere Gini-indeks for å dele datasettet.
Viktige vilkår for beslutnings-treet i datamining
Her er noen av de viktige vilkårene for et beslutnings tre i data mining, gitt nedenfor:
- Root Node: Dette er den første noden der delingen skjer.
- Leaf Node: Dette er noden etter som det ikke er mer forgrening.
- Beslutningsnode: Noden som ble dannet etter deling av data fra en tidligere node, er kjent som en beslutningsnode.
- Gren: Delavsnitt av et tre som inneholder informasjon om kjølvannet av splittelse ved beslutningsnoden.
- Beskjæring: Når det er fjerning av undernoder til en beslutningsnode for å imøtekomme en uteliggende eller støyende data, kalles beskjæring. Det antas også å være det motsatte av å splitte.
Anvendelse av beslutningstreet i datamining
Decision Tree har et flytdiagram av arkitektur innebygd med typen algoritme. Den har egentlig et "Hvis X så Y ellers Z" -mønster mens delingen er laget. Denne typen mønstre brukes til å forstå menneskets intuisjon i det programmatiske feltet. Derfor kan man i utstrakt grad bruke dette i forskjellige kategoriseringsproblemer.
- Denne algoritmen kan brukes mye i feltet der objektivfunksjonen er relatert med hensyn til analysen som er gjort.
- Når det er mange handlingsmuligheter tilgjengelig.
- Tidligere analyse.
- Forstå det betydelige settet med funksjoner for hele datasettet og “mine” de få funksjonene fra en liste over hundrevis av funksjoner i big data.
- Velge den beste flyreisen for å reise til et reisemål.
- Beslutningsprosess basert på forskjellige omstendighetssituasjoner.
- Churn Analyse.
- Sentiment Analyse.
Fordeler med beslutningstreet
Her er noen fordeler med avgjørelsestreet forklart nedenfor:
- Brukervennlighet: Måten avgjørelsestreet skildres i sine grafiske former gjør det enkelt å forstå for en person med ikke-analytisk bakgrunn. Spesielt for personer i ledelse som ønsker å se på hvilke funksjoner som er viktige bare ved et blikk på beslutnings-treet kan få frem hypotesen.
- Datautforskning: Som diskutert er det å skaffe viktige variabler en kjernefunksjonalitet i beslutnings-treet og bruke det samme, man kan finne ut av under utforskning av data ved å bestemme hvilken variabel som vil trenge spesiell oppmerksomhet i løpet av data mining og modelleringsfasen.
- Det er veldig lite menneskelig inngrep i dataforberedelsesfasen, og som et resultat av den tidkrevende tid under data blir rengjøringen redusert.
- Decision Tree er i stand til å håndtere kategoriske så vel som numeriske variabler og ivaretar også klasseklassifiseringsproblemer.
- Som en del av forutsetningen har beslutnings-trær ingen forutsetning fra en romlig distribusjons- og klassifiseringsstruktur.
Konklusjon
Til slutt, for å avslutte beslutningstrær, bringer inn en helt annen klasse av ikke-linearitet og imøtekommes for å løse problemer med ikke-linearitet. Denne algoritmen er det beste valget å etterligne et beslutningsnivå tenke på mennesker og fremstille den i en matematisk-grafisk form. Det tar en ovenfra og ned tilnærming når det gjelder å bestemme resultater fra nye usettede data og følger prinsippet om splittelse og erobring.
Anbefalte artikler
Dette er en guide til Decision Tree in Data Mining. Her diskuterer vi algoritmen, viktigheten og anvendelsen av beslutningstreet i data mining sammen med fordelene. Du kan også se på følgende artikler for å lære mer -
- Data Science Machine Learning
- Typer av dataanalyseteknikker
- Decision Tree i R
- Hva er datamining?
- Veiledning for forskjellige metoder for dataanalyse