

Forskjellen mellom Apache Hive og Apache HBase -
Apache Hive-historien begynner i 2007 når ikke Java-programmerer må slite mens han bruker Hadoop MapReduce. Forskere og utvikler spådde at i morgen er en epoke av Big Data. Allerede forskjellige dataformater som strukturerte, semistrukturerte og ustrukturerte ble samlet opp. Til og med Facebook slet med den større mengden databehandling. Forskere på Facebook introduserte Apache Hive for databehandling på Hadoop Cluster. Facebook var det første selskapet som kom med Apache Hive.
Apache HBase-historien begynner i 2006 da den San Francisco-baserte oppstarten Powerset prøvde å bygge en naturlig søkemotor for nettet. HBase er en implementering av Googles Bigtable. Forsto vi noen gang, hvorfor det var behov for å komme med enda en lagringsarkitektur? Relational Database Management System har eksistert siden begynnelsen av 1970-tallet. Det er mange brukssaker der relasjonsdatabaser perfekt gir mening, men for noen spesifikke problemer passer ikke relasjonsmodellen særlig bra.
La meg forklare om Apache Hive og Apache HBase i flere detaljer.
Forskjeller mellom Apache Hive og Apache HBase
Apache Hive er et Apache-åpen kildekode-prosjekt bygget oppå Hadoop for spørring, oppsummering og analyse av store datasett ved bruk av et SQL-lignende grensesnitt. Apache Hive gir et SQL-aktig språk kalt HiveQL, som transparent konverterer spørsmål til MapReduce for utføring på store datasett som er lagret i Hadoop Distribuerte filsystem (HDFS). Apache Hive er en Hadoop klyngekomponent som normalt distribueres av dataanalytikere. Apache-bikube brukes til batchbehandling av store ETL-jobber. Apache Hive støtter også batch-SQL-spørsmål på veldig store datasett. Apache Hive øker skjemaets designfleksibilitet og også dataserialisering og deserialisering. Apache Hive støtter ikke OLTP (Online Transaction Processing) fordi hive ikke støtter spørsmål i sanntid og radnivåoppdateringer.
Apache HBase er en open source NoSQL-database som gir sanntids-, lese- og skrivetilgang til store datasett. NoSQL er ikke-relasjonell database. Apache HBase er distribuert kolonneorientert database som kjøres på toppen av Hadoop Distribuert File System (HDFS). Så HBase bringer fordelene med NoSQL til Hadoop. Apache HBase tilbyr tilfeldig tilgang til data som er til stede i HDFS. Den utnytter feiltoleransen som leveres av HDFS. Brukeren kan lagre dataene i HDFS enten direkte eller gjennom HBase.
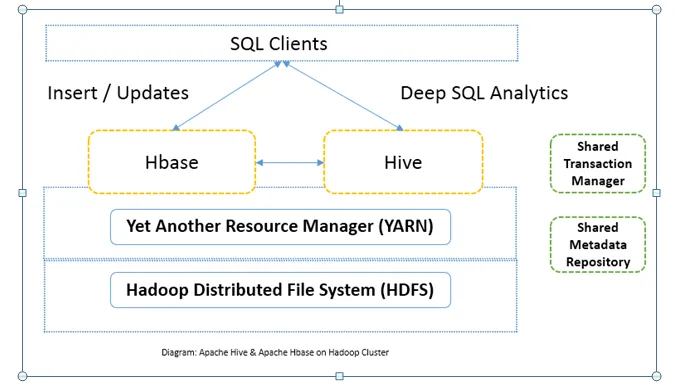
Sammenligning fra topp til hodet mellom Apache Hive vs Apache HBase (Infographics)
Nedenfor er topp 12-forskjellen mellom Apache Hive og Apache HBase

Viktige forskjeller - Apache Hive vs Apache HBase
Nedenfor er listen over punkter, som beskriver de viktigste forskjellene mellom Apache Hive og Apache HBase:
- Apache HBase er en database mens Apache Hive er en databasemotor.
- Apache Hive brukes hovedsakelig til batchbehandling (OLAP), mens Apache HBase hovedsakelig brukes til transaksjonell prosessering (OLTP).
- Apache Hive kjører de fleste SQL-spørsmål mens Apache HBase ikke tillater SQL-spørsmål direkte.
- Apache Hive støtter ikke operasjonsnivåoperasjoner som oppdatering, innsetting og sletting, mens Apache HBase støtter operasjonsnivåoperasjoner som oppdatering, innsetting og sletting.
- Apache Hive kjører på toppen av MapReduce mens Apache HBase kjører på toppen av Hadoop Distribuerte filsystem (HDFS).
Apache Hive spør etter filene ved å definere en virtuell tabell og kjøre HQL-spørringer på toppen av den. Det er en prosess der filer praktisk talt er koblet til en tabell som struktur og bruker kan utføre Hive Query Language (HQL) og disse spørsmålene blir konvertert til MapReduce Job by Hive. Brukeren trenger ikke å skrive MapReduce-jobb, HQL-spørsmål konverteres internt til krukkefiler og disse krukkefilene blir implementert på datasett.
Mens du er i Apache HBase, er tabeller delt inn i regioner og blir servert av regionens servere. Flere regioner er vertikalt delt av kolonnefamilier i butikker og butikker lagres som filer i HDFS.
Når du skal bruke Apache Hive:
- Krav til datalagring
- Analytiske spørringer
- Dataanalyse som er kjent med SQL
Når du skal bruke Apache HBase:
- Rask og interaktiv databehandling
- Sanntidsspørsmål
- Raske oppslag
- Behandlingen på serversiden
- Tilfeldig lese / skrivetilgang til Big Data
- Brukbarhet skalerbarhet
Apache Hive kan brukes til å beregne trender og logger på e-handelsnettsted for bestemt varighet, region eller tidssone. Den kan brukes til å behandle batch-forespørsler over historiske data, mens Apache HBase kan brukes av Facebook eller LinkedIn for meldinger og sanntidsanalyse. Den kan også brukes til å telle likes.
Apache Hive vs Apache HBase sammenligningstabell
Jeg diskuterer store artefakter og skiller mellom Apache Hive og Apache HBase.
| Apache Hive | Apache HBase | |
| Databehandling | Apache Hive brukes til
batchbehandling dvs. Online Analytical Processing (OLAP) | Apache HBase brukes til transaksjonell prosessering, dvs. Online Transactionional Processing (OLTP) |
| Behandler hastighet | Apache Hive har høyere latenstid på grunn av å utføre MapReduce-jobb i bakgrunnen | Apache HBase jobber med sanntidsforespørsel og mye raskere enn Apache Hive |
| Kompatibilitet med Hadoop | Apache Hive kjører på toppen av MapReduce | Apache HBase kjører på toppen av HDFS |
| Definisjon | Apache Hive er åpen kildekode og ligner på SQL brukt for analytiske spørringer | Apache HBase er åpen kildekode NoSQL-database som brukes til sanntidsspørring |
| Delt metadata | Data opprettet i Apache Hive er automatisk synlige for Apache HBase | Data opprettet i Apache HBase er automatisk synlige for Apache Hive |
| skjema | Apache-bikube støtter skjema for å sette inn data i tabeller | Apache HBase er skjemafri database. |
| Oppdater funksjonen | Oppdateringsfunksjonen er komplisert i Apache Hive | Brukeren kan veldig enkelt oppdatere dataene i Apache HBase |
| operasjoner | Operasjoner i Apache Hive kjører ikke i sanntid | Operasjoner i Apache HBase kjører i sanntid |
| Datatyper | Apache Hive er ment for strukturerte og semistrukturerte data | Apache HBase er for ustrukturerte data. |
| Konsistensnivå | Apache-bikube støtter eventuell konsistens | Apache HBase støtter øyeblikkelig konsistens |
| Partisjonsmetoder | Apache Hive støtter Sharding-funksjoner | Apache HBase støtter også Sharding-funksjoner |
| Datalagring | Datoen lagres i Hive Metastore, Partitions and Buckets in Apache Hive | Data lagres i kolonne og på rad av tabeller i Apache HBase |
Konklusjon - Apache Hive vs Apache HBase
Vanligvis brukes Apache Hive vs Apache HBase sammen i samme klynge. Begge kan brukes sammen for å forbedre prosessorkraften. Siden bikube forbedrer de analytiske sidene av HDFS mens HBase forbedrer transaksjoner i sanntid. Brukeren kan bruke Hive som et ETL-verktøy for batchinnsatser med dataene i HBase og deretter for å utføre spørsmål som ytterligere kan bli med data som er til stede på HBase-tabeller med dataene som allerede er til stede på HDFS. Data kan leses og skrives fra Apache Hive til HBase og tilbake igjen. Grensesnittet mellom Apache Hive og Apache HBase er fremdeles modningsfase. Det er mye mer som kommer. Likevel kan jeg si at begge Apache Hive vs Apache HBase gjør Hadoop-klyngen mer robust og kraftig.
Relaterte artikler:
Dette har vært en guide til Apache Hive vs Apache HBase, deres betydning, sammenligning av topp mot hod, nøkkelforskjeller, sammenligningstabell og konklusjon. Du kan også se på følgende artikler for å lære mer -
- Topp 5 Big Data Trender
- 5 Utfordringer med Big Data Analytics
- Hvordan knekke Hadoop-utviklerintervjuet?
- 5 Utfordringer med Big Data Analytics