

Introduksjon til gnistkommandoer
Apache Spark er et rammeverk som er bygget på toppen av Hadoop for raske beregninger. Det utvider begrepet MapReduce i det klyngebaserte scenariet for å effektivt kjøre en oppgave. Spark Command er skrevet i Scala.
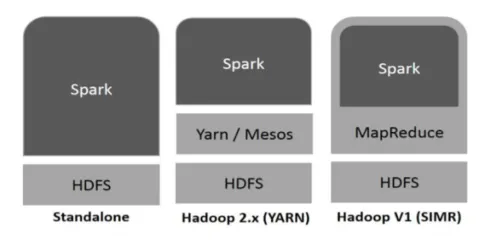
Hadoop kan brukes av Spark på følgende måter (se nedenfor):
Figur 1
https://www.tutorialspoint.com/
- Frittstående: Spark direkte utplassert på toppen av Hadoop. Gnistjobber går parallelt på Hadoop og Spark.
- Hadoop YARN: Spark kjører på Garn uten behov for noen forhåndsinstallasjon.
- Spark in MapReduce (SIMR): Spark in MapReduce brukes til å starte gnistjobb, i tillegg til frittstående distribusjon. Med SIMR kan man starte Spark og kan bruke skallet sitt uten administrativ tilgang.
Komponenter av gnist:
- Apache Spark Core
- Spark SQL
- Gniststrømming
- MLib
- GraphX
Resilient Distribuerte datasett (RDD) regnes som den grunnleggende datastrukturen i Spark-kommandoer. RDD er uforanderlig og skrivebeskyttet i naturen. Alle slags beregninger i gnistkommandoer gjøres gjennom transformasjoner og handlinger på RDD-er.
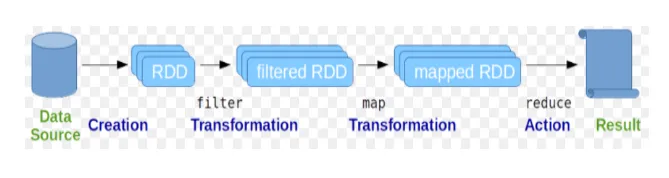
Fig. 2
Google-bilde
Gnistskall gir et medium for brukere å samhandle med funksjonalitet. Gnistkommandoer har mange forskjellige kommandoer som kan brukes til å behandle data på det interaktive skallet.
Grunnleggende gnistkommandoer
La oss ta en titt på noen av de grunnleggende gnistkommandoene som er gitt nedenfor: -
-
Slik starter du Spark shell:

Fig. 3
-
Les fil fra lokalt system:

Her er "sc" gnistkontekst. Tatt i betraktning “data.txt” er i hjemmekatalogen, leses det slik, ellers må man spesifisere hele banen.
-
Lag RDD gjennom parallellisering

NewData er RDD nå.
-
Telle varer i RDD

-
Samle inn
Denne funksjonen returnerer alt RDD-innhold til driverprogrammet. Dette er nyttig i feilsøking på forskjellige trinn i skriveprogrammet.
-
Les de første tre varene fra RDD

-
Lagre output / behandlet data i tekstfilen

Her er "output" -mappen gjeldende bane.
Midlertidige gnistkommandoer
1. Filter på RDD
La oss lage en ny RDD for elementer som inneholder "ja".

Transformasjonsfilter må kalles på eksisterende RDD for å filtrere på ordet “ja”, som vil opprette ny RDD med den nye listen over elementer.
2. Kjededrift

Her handlet filtertransformasjon og tellehandling sammen. Dette kalles kjededrift.
3. Les det første elementet fra RDD

4. Telle RDD-partisjoner
Som vi vet, er RDD laget av flere partisjoner, det oppstår behov for å telle nei. av partisjoner. Da det hjelper med tuning og feilsøking mens du arbeider med gnistkommandoer.

Som standard er minimum nr. pf-partisjon er 2.
5. bli med
Denne funksjonen blir sammen med to tabeller (tabellelement er på parvis vis) basert på den vanlige tasten. I parvis RDD er det første elementet nøkkelen og det andre elementet er verdien.
6. Buffer en fil
Cache er en optimaliseringsteknikk. Caching RDD betyr at RDD vil ligge i minnet, og all fremtidig beregning vil bli gjort på de RDD i minnet. Det sparer disketten tid og forbedrer forestillingene. Kort sagt, det reduserer tiden for tilgang til dataene.

Data blir imidlertid ikke bufret hvis du kjører over funksjonen. Dette kan bevises ved å besøke hjemmesiden:
http: // localhost: 4040 / oppbevaring
RDD blir bufret, når handlingen er utført. For eksempel:

Én funksjon til som fungerer som cache () er vedvarende (). Persist gir brukerne fleksibiliteten til å gi argumentet, noe som kan bidra til at data blir lagret i minne, disk eller minne. Vedvarer uten argument fungerer på samme måte som cache ().
Avanserte gnistkommandoer
La oss ta en titt på noen av de avanserte gnistkommandoene som er gitt nedenfor: -
-
Send en variabel
Broadcast-variabel hjelper programmereren med å lese den eneste variabelen som er lagret i hurtigbufring på hver maskin i klyngen, i stedet for å sende kopi av den variabelen med oppgaver. Dette hjelper deg med å redusere kommunikasjonskostnadene.
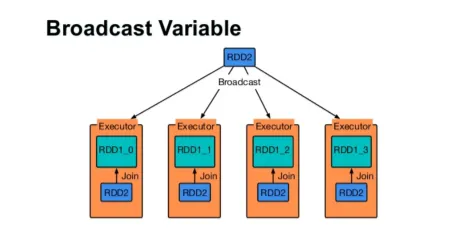
Fig. 4
Google-bilde
Kort sagt, det er tre hovedfunksjoner i den sendte variabelen:
- uforanderlige
- Passer i minnet
- Fordelt over klyngen
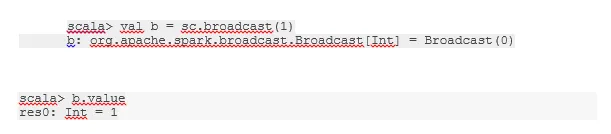
-
akkumulatorer
Akkumulatorer er variablene som blir lagt til tilknyttede operasjoner. Det er mange bruksområder for akkumulatorer som tellere, summer osv.

Navnet på akkumulatoren i koden kunne også sees i Spark UI.
-
Kart
Kartfunksjon hjelper med å iterere over hver linje i RDD. Funksjonen som brukes på kartet, brukes til alle elementer i RDD.
For eksempel, i RDD (1, 2, 3, 4, 6) hvis vi bruker “rdd.map (x => x + 2)”, vil vi få resultatet som (3, 4, 5, 6, 8).
-
Flatmap
Flatmap fungerer på samme måte som kartet, men kartet returnerer bare ett element mens flatmap kan returnere listen over elementer. Deling av setninger i ord vil derfor trenge flatkart.
-
Føre sammen
Denne funksjonen hjelper deg med å unngå stokking av data. Dette brukes i den eksisterende partisjonen, slik at mindre data blir blandet. På denne måten kan vi begrense bruken av noder i klyngen.
Tips og triks for å bruke gnistkommandoer
Nedenfor er de forskjellige tipsene og triksene med Spark-kommandoer: -
- Nybegynnere av Spark kan bruke Spark-shell. Ettersom Spark-kommandoer er bygd på Scala, er det absolutt bra å bruke scala-gnistskall. Imidlertid er python-gnistskall også tilgjengelig, så til og med at også noe man kan bruke, som er godt kjent med python.
- Gnistskall har mange alternativer for å administrere ressursene i klyngen. Under Command kan hjelpe deg med det:

- I Spark er det vanlige å jobbe med lange datasett. Men ting går galt når det kommer dårlige innspill. Det er alltid en god idé å slippe dårlige rader ved å bruke filterfunksjonen til Spark. Det gode settet med innspill vil være en god tur.
- Spark velger en egen partisjon for dine data. Men det er alltid en god praksis å følge med på skillevegger før du begynner i jobben. Å prøve ut forskjellige partisjoner vil hjelpe deg med parallellitet i jobben din.
Konklusjon - Gnistkommandoer:
Spark-kommando er en revolusjonerende og allsidig big data-motor, som kan fungere for batchbehandling, sanntidsbehandling, hurtigbufring av data osv. Spark har et rikt sett med Machine Learning-biblioteker som kan gjøre det mulig for dataforskere og analytiske organisasjoner å bygge sterke, interaktive og raske applikasjoner.
Anbefalte artikler
Dette har vært en guide til gnistkommandoer. Her har vi diskutert grunnleggende så vel som avanserte gnistkommandoer og noen umiddelbare gnistkommandoer. Du kan også se på følgende artikkel for å lære mer -
- Adobe Photoshop-kommandoer
- Viktige VBA-kommandoer
- Tableau kommandoer
- Juksark SQL (kommandoer, gratis tips og triks)
- Typer ledd i Spark SQL (eksempler)
- Gnistkomponenter | Oversikt og Topp 6-komponenter