

Forskjellen mellom data mining og web mining
Databehandling : Det er et konsept for å identifisere et betydelig mønster fra dataene som gir et bedre utfall. Identifisere mønstre fra hvor? Fra dataene som genereres fra systemene.
Web mining : Prosessen med å utføre Data mining på nettet kalles Web mining. Trekker ut webdokumentene og oppdager mønstrene fra det.
Eksempel: Teknikker brukt for prediktiv analyse. (Værmelding basert på å identifisere mønstrene fra historiedataene)
Lar oss forstå den viktigste forskjellen mellom data mining og web mining i detalj i dette innlegget.
Analogi
Gull produseres av prosessen som kalles gullgruvedrift. Den blir trukket ut og raffinert fra malmen. Det endelige resultatet av gullgruvedrift er edelt metall. Like måte,
for å få nøkkelinformasjon (data som er verdt) fra en rå kilde, brukes data mining teknikk. Her blir mønsteret som er oppdaget fra rå datakilde ansett som verdifullt for dataanalytikeren / dataforskerne for å fortsette med beslutningen som påvirker forretningsverdien.
Datautvinning
Enkelt sagt er datadrift et begrep om kunnskap om gruvedrift fra forskjellige datasett. Kunnskapen som trekkes ut blir videre brukt til å gi prognoser eller anbefalinger. Dataene som skal utvinnes, er enten tilgjengelige i datavarehuset eller andre eksterne systemer. Data kan være tilgjengelig på forskjellige tabeller med ulik atferd eller attributter. For å identifisere mønsteret, må sammenhengen mellom flere datasett identifiseres.
Trinn i data mining
Siden data mining er et abstrakt, er listen over trinn involvert her,
- Forberedelse av data
- Mønsterfunn
- Bygg modeller for å forutsi / anbefale (for å nevne noen tilfeller)
- Oppsummerer modellverdien
Nett gruvedrift
Nett gruvedrift er et abstrakt da det er tre forskjellige typer teknikker for gruvedrift.
- Nettverksdrift
- Nettstruktur gruvedrift
- Nettbruk gruvedrift
Web gruvedrift klasser for informasjonsinnsamling 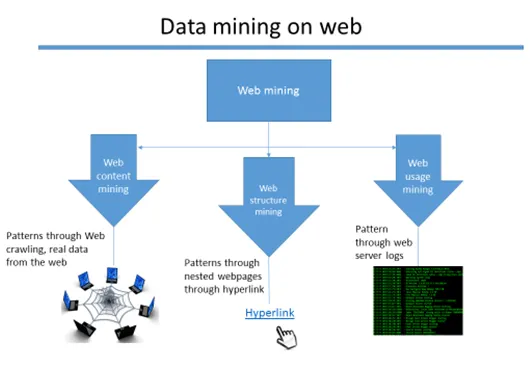
Nettverksdrift
Data fra websidene blir trukket ut for å oppdage forskjellige mønstre som gir en betydelig innsikt. Det er mange teknikker for å trekke ut data som skraping av nett (for eksempel - skrapete og Octoparse er de velkjente verktøyene som utfører gruvedrift av nettinnhold.
Et av de beste eksemplene - For å gjennomføre en begivenhet eller et hvilket som helst program, analyserer organisasjonen først om lokasjonene (hvilket sted som er best egnet til å gjennomføre programmet slik at det blir fullt oppmøte). For å utføre disse analysene, må man samle stedsspesifikk informasjon om byen, oppgi og hvor langt arrangementet fra innbyderen befinner seg. Eventuelle stedsspesifikke data kan hentes ut fra nettet. Det er her gruveinnholdet på nettet kommer inn i bildet.
Nettstruktur gruvedrift
Data fra hyperkoblinger som fører til forskjellige sider blir samlet og utarbeidet for å oppdage et mønster. For å se en persons offentlige profil fra en blogg eller annen webside, er det stor sjanse for at de legger inn sosiale lenker på sosiale medier. Så dataene blir ikke bare hentet fra en enkelt kilde, men også fra de nestede sidene gjennom hyperkoblingene som er knyttet til hver side. Det er forskjellige algoritmer for å utføre dette. (Eksempel: PageRank-algoritme)
Nettbruk gruvedrift:
Når en webapplikasjon er vert, er det nok av webserverlogger som blir generert om applikasjonens brukerwebaktivitet. Disse loggene blir ansett som en rå data til gjengjeld meningsfulle data blir trukket ut og mønstre blir identifisert.
For eksempel for enhver e-handelsvirksomhet, når de ønsker å øke omfanget av virksomheten eller legge til en forbedring for bedre kundeopplevelse, overvåkes brukers nettaktivitet gjennom applikasjonsloggene og data mining blir brukt på den.
Web mining og data mining er mer eller mindre lignende teknikker, men web mining handler om analyse på nettet. Data mining er ikke begrenset til nettet. Det er en tradisjonell prosess som foregår for all dataanalyse.
Når vi snakker om dataene fra nettet, er det varianter av data som kan observeres. Det kan være strukturerte data (databasedata blir trukket gjennom API hvis de blir utgitt for offentlig). Semistrukturerte data - alle nettaktivitetsrelaterte eller til og med serverlogger. Eller til og med ustrukturerte data som bilder etc. (hvis noen analyser blir utført på bilder)
Sammenligning fra hodet til hodet mellom data mining og web mining (infographics)
Nedenfor er de 7 beste sammenligningene mellom data mining og web mining

Viktige forskjeller mellom data mining og web mining
Følgende er forskjellen mellom data mining og web mining er som følger
Web mining og data mining er begge nesten like når det gjelder å identifisere mønstrene. Men hvor og hva er forskjellen i gruvedrift på nettet fra data mining. Hva slags data og data hentes fra hvor? Dette er de to ultimate aspektene som bringer forskjellen mellom Data mining og Web mining.
Web mining er under data mining, men dette er begrenset til nettrelaterte data og identifisering av mønstrene. Data mining er et stort konsept som involverer flere trinn fra å klargjøre dataene til validering av sluttresultatene som fører til beslutningsprosessen for en organisasjon.
Data mining vs Web mining Comparision Table
| Grunnlag for sammenligning | Datautvinning | Nett gruvedrift |
| Konsept | Mønsteridentifikasjon fra data tilgjengelig i alle systemer. | Mønsteridentifikasjon fra nettdata. |
| Søknad / brukssaker | Værmelding ved hjelp av historiske værmeldinger | Datasøking HITS / PageRank teknikker |
| Hvem gjør dette? | Data forskere Dataingeniører | Dataforskere / Dataanalytikere Dataingeniører |
| Prosess | Datautvinning -> Oppdagelse av mønster -> Utvikle funksjonen / løse den (algoritme) | Samme prosess, men på nettet ved bruk av nettdokumentene |
| Verktøy | Maskinlæringsalgoritmer | scrappy, Side rangering, Apache-logger |
| Hvor betydelig | Mange organisasjoner er avhengige av datavitenskapelige resultater for å ta beslutninger. | Web-relatert data pull vil påvirke den eksisterende data mining prosessen. |
| ferdigheter | Datarensingsteknikker, maskinlæringsalgoritmer, statistikk, sannsynlighet | Kunnskap om applikasjonsnivå, Datateknikk, statistikk, sannsynlighet |
Konklusjon - Data mining vs web mining
Eventuelle gruvedriftsteknikker med dataene er å oppdage kunnskapen og hvor godt den kan brukes til å oppnå et bedre resultat. Organisasjoner som er opptatt av å forbedre virksomheten og tjene høyt, trenger de mange beslutninger å ta basert på dataene som i stor grad er tilgjengelige i systemene deres generert i et enormt volum. Ikke alle data anses for å gi kunnskap og innsikt. Hvilke, hvorfor og hva er de viktigste spørsmålene forskere / dataanalytikere må tenke på når de forbereder seg på å identifisere mønstrene. På en veldig lekmannsperiode er datadrift som en prosess med å kverke melken til å lage smør.
Anbefalt artikkel
Dette har vært en guide til Data mining vs Web mining, deres betydning, sammenligning av Head to Head, nøkkelforskjeller, sammenligningstabell og konklusjon. Du kan også se på følgende artikler for å lære mer -
- Data Mining Vs Statistics - Hvilken er bedre
- 10 kraftige trinn for effektiv planlegging av webdesign
- Data mining vs maskinlæring - 10 beste ting du trenger å vite
- De tre beste tingene å lære om datamining og tekstgruvedrift
- Verktøy og teknikker som brukes i prosessering av data