

Data Supply Chain
Data har blitt den største eiendelen til en virksomhet. Jo større data det blir mer komplekst å håndtere dem. Det blir mer utfordrende å administrere og analysere dataene og få ønsket forretningsforståelse fra dataene. Hovedmålet er å gjøre det mulig for forretningsfolk å ta bedre beslutninger basert på analyse av enorme datasett.
Hvis dataflyten ikke er korrekt, vil ikke virksomheten kunne dra størst mulig utbytte av dataene sine. Dataene skal flyte lett gjennom en organisasjon og dens økosystemer.
Av denne grunn er det viktig å lage en dataforsyningskjede som får dataene til å fungere mot forretningsmessige mål og skape et miljø for å nå disse målene.
Hva er en dataforsyningskjede?
Før du går inn i Data Supply-kjeden. først, la oss se hva som er en forsyningskjede?
En stor datatilførselskjede er en prosess der noe går inn i en organisasjon, gjennomgår en transformasjon og kommer som noe av verdi som kan brukes av folket.
En dataforsyningskjede er også den samme som alle andre forsyningskjeder der data legges inn fra den ene enden av systemet og i neste trinn blir den transformert ved hjelp av analytics. Til slutt blir det levert som et sett med nyttig innsikt om organisasjonen som kan brukes til ytterligere forbedringer i virksomheten. Analyser av dataforsyningskjeden vil komme inn i organisasjonen er avledet fra forskjellige kilder som nettsteder, sosiale nettverk, mobilapper, blogger, CRM og andre. Data Supply chain er mer relatert til standardisering av data.
Fordelene med dataforsyningskjeden
De viktigste fordelene ved å bruke en dataforsyningskjede er listet opp nedenfor
- Optimaliserer driftseffektiviteten
- Forbedrer smidighet i virksomheten
- Reduserer datatiden
- Enkelt å få plass til nye datakilder
- Justerbar for å håndtere store data i fremtiden
- Forbedrer datakvaliteten og tilfredsstiller på samme side kundens krav
- Hjelper med å finne ut nye inntektsmodeller der data fungerer som en eiendel
- Behandler dataene raskt
- Øker inntektene til selskapet ved å hjelpe dem til å ta bedre beslutninger.
- Forbedre kundeforholdet
Hvorfor er det viktigere å bygge en Big data supply chain?
-
Datakvalitet er viktigere enn kvantitet
Big data supply chain er den enkleste måten å forbedre effektiviteten til enhver organisasjon. Så selskaper bør alltid fokusere på kvaliteten på dataene og finne ut flere kilder som kvalitetsdata kan stammer fra.
-
Flere data betyr mye
Søk etter mer data er i en prosess av mange selskaper. I tillegg til dette bør selskaper også prøve å lage sine egne data. Å lage nye datakilder kan være en stor fordel for selskapet.
-
Med fokus på forretningsmessige mål
Det viktigste er at alle menneskene i selskapet, fra ansatte til CIO, skal kjenne til forretningsmessige mål. Dataene skal rettes mot virksomhetsmålene. Big data supply chain vil bidra til å gjøre det.
-
Bred bruk av data
Big data supply chain som er anskaffet fra forskjellige kilder, bør brukes riktig i organisasjonen. Av denne grunn må selskapet bruke forskjellige strategier og teknologier.
Komponenter i dataforsyningskjeden
De viktige komponentene i en dataforsyningskjede er gitt nedenfor
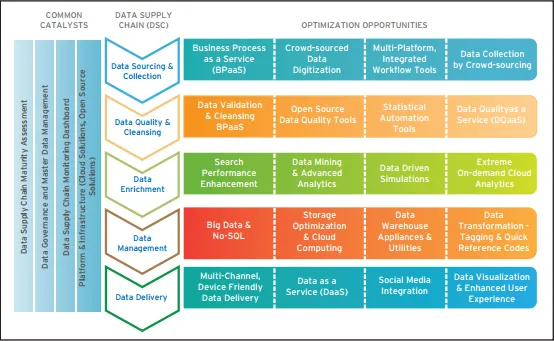
- Datasourcing og innsamling - Dette inkluderer forretningsprosess som en tjeneste, outsourcing av forretningsprosesser og Crowdsourcing. Crowdsourcing anses som en erstatning for tradisjonell outsourcing-metode. Her betyr skare mennesker med felles interesse. De deler løsninger til fordel for organisasjonen som kalles folkemengden
- Datakvalitet og rensing - Data av høy kvalitet er en veldig verdifull ressurs som øker brukeropplevelsen. For å forbedre slik erfaring bør bedrifter bruke spesialbyggede løsninger og leverandører for å gi best mulig resultat. Datakvalitet som en tjeneste (DQaaS) må utgjøre en stor del av datakvaliteten da den følger en sentralisert tilnærming. Open source-verktøy er det beste for å jobbe med rotete datasett.
- Datainriking - Ved bruk av store dataverktøy som Hadoop kan dataanrikningskomponentene behandle dataene raskere og gi raskere og bedre resultater.
- Datahåndtering - Avanserte datavarehusfunksjoner går utover det tradisjonelle datavarehuset og tilbyr vellykket forretningsintelligens. De er enkle og rimelige. Open source klyngede filsystemer som HDFS og andre kan løse noen av de største utfordringene i dataforsyningskjeden.
- Data Delivery - Data levering inkluderer datavisualisering, klassifisering av databaser, integrering av sosiale medier, brukervennlig dataoverføring og Data As a Service (DaaS)
Data Supply Chain Analyst
Data supply chain analytiker er arkitekturen for den moderne data supply chain prosessen. Hvis det gjøres på en ordentlig måte, vil analytikeren av dataforsyningen la selskapene til å utnytte flere datakilder og forbedre datafunnet i stor grad. Analyser av dataforsyningskjeden vil hjelpe organisasjonen til å møte tre store begrensninger. De blir diskutert under temaene til dataforsyningskjedenanalytiker:
-
Bevegelse
For å få grundig kunnskap om dataene trenger virksomheter å utlede det fra forskjellige kilder og deretter bruke passende prosesserings- og lagringssystem. Mens du flytter data, skal det ikke være tap av selv enkeltdata, og akselerasjon hjelper til med å gjøre det. Det bringer nøyaktige data inn i organisasjonen og sørger for at de kan behandles raskt.
-
Behandling
Behandlingen av data avhenger hovedsakelig av volum og type data. Organisasjoner vil forvente at systemet vil gjøre beregninger på dataene raskere enn noen gang. Analysteknologi for dataforsyningskjede vil hjelpe til med å forhåndsbehandle dataene som kommer inn og effektivisere dataene med eksisterende data fra organisasjonen for å bidra til å ta smartere beslutninger. Dataakselerering hjelper i rask behandling av data ved å forbedre maskinvare- og programvarekomponentene og hjelper med å forbedre effektiviteten.
-
interaktivitet
Interaktivitet betyr bruken av dataene. Det er mange løsninger for å få forventede resultater fra gitte spørsmål. Nå er det nye programmeringsspråk utviklet for å støtte systemene. Dataakselerering hjelper brukerne til å bygge bro mellom infrastrukturen og applikasjonene. Dette hjelper deg også med å levere spørringsresultatene raskt.
5 trinn for å bygge en dataforsyningskjede
Her er de fem trinnene for å bygge en dataforsyningskjede
-
Datatjenesteplattform
Det første og fremst trinnet i å lage en datatilførselskjede er å begynne med å velge en datatjenesteplattform som hjelper selskapet å ha enkel tilgang til dataene fra forskjellige kilder når de trenger det. Gjennom denne dataplattformen kan brukerne ha tilgang til et stort basseng med data direkte. Dataplattformen kan kjøpes fra en leverandør. Det kan være en enkelt dataplattform eller det kan være en kombinasjon av forskjellige plattformer levert av forskjellige leverandører.
I dag er det også separate dataplattformer som hjelper til med å utlede data fra en bestemt kilde. Men alle disse plattformene fungerer gjennom en vanlig standard tilgangsprotokoll. Nylig har mange organisasjoner begynt å bruke API-administrasjonsplattformer.
-
Akselerere data gjennom forsyningskjeden
Det neste trinnet i denne prosessen er å integrere dataene fra forskjellige kilder. I det siste skiller selskaper mellom ofte brukt informasjon og mindre relevante data. Jo mer relevante data lagres på systemer med høy ytelse, og de mindre relevante lagres i systemer med langsom ytelse. Men nå kan organisasjoner øke hastigheten på dataene. Dataene er tilgjengelige for menneskene i organisasjonen med stor hastighet, og dette hjelper med å få mer kunnskap fra dataene.
-
Fremme dataoppdagelse
Tradisjonelle BI-metoder krever mer informasjon fra dataforskerne eller dataanalytiker for å få et svar på et foreskrevet forretningsspørsmål. Men nå på grunn av dataoppdagelsesverktøyene, selv før selskapene begynner å avhøre, skiller de sine egne spørsmål som forventes å oppstå fra selskapene etter å ha blitt kjent med dataene i detalj.
-
Innser dataverdi
I sluttfasen av dataforsyningskjeden som er transformert, kan nå deles og være tilgjengelig. Bedrifter kan forstå dataene bedre og få kunnskap om det. De kan ta beslutninger basert på dataene. For å øke verdien på dataene kan de deles med selskapets leverandører, partnere og kunder.
-
Kognitiv databehandling
Kognitiv databehandling er en metode der maskinen læres å utnytte dataene, lære av dem og finne ut hva som kan gjøres med den. Dataforsyningskjeden gir en langsiktig løsning. I eldre metode kan en løsning finne ut for en spesifikk oppgave eller en enkelt sak. Men gjennom maskinlæringssystemer kan systemer få mer kunnskap fra data som erfaring, de kan lagres og de kan bruke dem i fremtiden når det eksisterer den samme situasjonen.
Bygge en bedre dataforsyningskjede
En organisasjon som har infrastruktur for å fange opp, behandle, analysere og distribuere dataene over hele forsyningskjeden, vil være i stand til å administrere varebeholdningene sine uten å miste forretningsmuligheter. Det er vanskelig å forutsi kunder i disse dager. Som et resultat er mange virksomheter i retning av etterspørselsdrevet produksjon. Dataforsyningskjeder som kan identifisere og svare på etterspørselen fra virksomheten, vil hjelpe dem med å oppnå sine produksjonsplaner, distribusjonsmodeller, definere markedsføringsstrategier og så videre.
Dataforsyningskjeden må holdes enkel og integrert. En stor utfordring med data er å få tilgang til og analysere dataene i forskjellige formater og strukturer som ligger i stedet-applikasjonen eller i skyen. Det er den største utfordringen som dataanalytikerne står overfor på sikt. Dataforskeren eller dataanalytikeren skal være kjent med SQL for å bygge bro mellom disse utfordringene og løse de komplekse problemene i data.
Beslutningstakere av leverandørkjeden er også mer avhengige av kvalitetsdata. Kvalitetsdata er med på å ta smarte beslutninger basert på nøyaktig informasjon tilgjengelig. Organisasjonen skal sørge for at dataene som brukes i beslutningsprosessen for forsyningskjeden er rene og nøyaktige. For å maksimere potensialet for dataforsyningsledere bør følge disse enkle trinnene.
-
Arbeid med nøyaktige data i sanntid
Hovedfaktoren i forsyningsnettverket er å ha en datakonsistens. Mangel på datakonsistens er et stort problem som de fleste selskaper står overfor. En viktig metode for å få nøyaktige data er å analysere tidspunktet for MRP-data som kommer inn i organisasjonen. Bedrifter kan også bruke datafangst og validering arbeidsflyter for å finne ufullstendige poster i systemet ditt. Hyppig revisjon kan også gjøres for å finne ut eventuelle feil i data.
Mobil teknologi hjelper deg med å forbedre sanntidsdataene og integrere dem med forsyningsnettverkene. Mobile enheter kan brukes til å sende og motta data umiddelbart hvor som helst og når som helst.
-
Fjern unødvendige data og prosesser
Ufullstendige og unødvendige data er bortkastet tid i forsyningskjedeprosessen. Selskapet bør ha en uavhengig AP-automatiseringsløsning for å sjekke dataene for treveis matching. En måte å finne ut unødvendige data er å evaluere områdene i forsyningsnettverket der flere prosesser brukes til å streame dataene til et integrert system. Dette vil bidra til å segmentere unødvendige data i hele bedriften og segmentere verdifulle data med jevnlig frekvens. Som et resultat vil dataene være mer konsistente og pålitelige for å ta bedre beslutninger.
-
Sentralisert dataløsning
Den største utfordringen med datatilførselskjedenettverk er den økende mengden informasjon hver dag. Sannheten er at jo mer data ikke alltid betyr bedre data. På grunn av fusjoner og anskaffelser vokser datatilførselsnettverket ofte. Så organisasjoner må finne måter å kombinere data fra forskjellige kilder og fra en stor mengde leverandører.
Den beste løsningen er å implementere et forsyningskjedens samarbeidssystem som vil hjelpe deg å strategisk se dataene dine. Denne visningen kan bidra til å sortere data i nødvendige deler og generere rapporter om sanntidsinformasjon.
Konklusjon
Dataforsyningskjeden vil være et stort fokus for mange virksomheter de kommende årene. Velge de riktige nøkkelelementene og tjenestene i Data Supply Chain vil bidra til å øke produktiviteten og optimalisere virksomheten for endringer i markedet.
relaterte artikler
Dette har vært en guide til hva som er en dataforsyningskjede? Her diskuterer vi også de 5 trinnene for å bygge en dataforsyningskjede sammen med Fordeler og dens komponenter. Du kan også lese Big data supply chain-
- 9 viktige måter å forbedre styring av forsyningskjeden
- Data Scientist vs Data Engineer - 7 fantastiske sammenligninger
- Data Scientist vs Business Analyst - Finn ut de 5 enorme forskjellene
- Vet den beste 7 forskjellen mellom Data Mining Vs Data Analyse