

Introduserer tilbakevendende nevrale nettverk (RNN)
Et tilbakevendende nevralt nettverk er en type et kunstig nevralt nettverk (ANN) og brukes i bruksområder for naturlig språkbehandling (NLP) og talegjenkjenning. En RNN-modell er designet for å gjenkjenne sekvensiell karakteristikk av data og deretter bruke mønstrene for å forutsi det kommende scenariet.
Arbeid med tilbakevendende nevrale nettverk
Når vi snakker om tradisjonelle nevrale nettverk, er alle utgangene og inngangene uavhengige av hverandre som vist i diagrammet nedenfor:
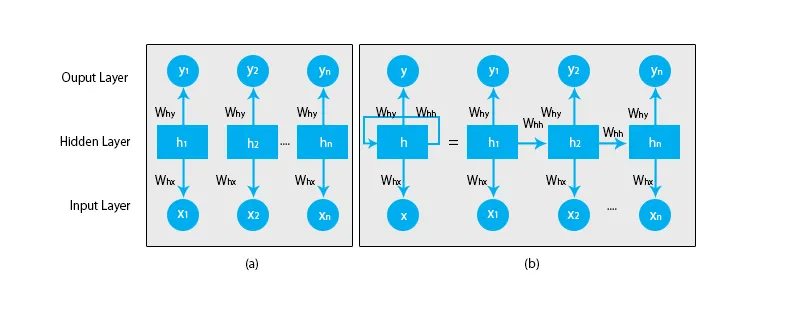
Men når det gjelder tilbakevendende nevrale nettverk, blir utgangen fra de foregående trinn matet inn i inngangen til gjeldende tilstand. For å forutsi for eksempel neste bokstav i et ord, eller for å forutsi neste ord i setningen, er det behov for å huske de forrige bokstavene eller ordene og lagre dem i en form for minne.
Det skjulte laget er det som husker litt informasjon om sekvensen. Et enkelt ekteeksempel som vi kan forholde oss til RNN er når vi ser på en film, og i mange tilfeller er vi i stand til å forutsi hva som vil skje videre, men hva om noen nettopp ble med i filmen og han blir bedt om å forutsi hva kommer til å skje neste gang? Hva blir svaret hans? Han eller hun vil ikke ha noen anelse fordi de ikke er klar over de tidligere hendelsene i filmen, og de har ikke noe minne om den.
En illustrasjon av en typisk RNN-modell er gitt nedenfor:
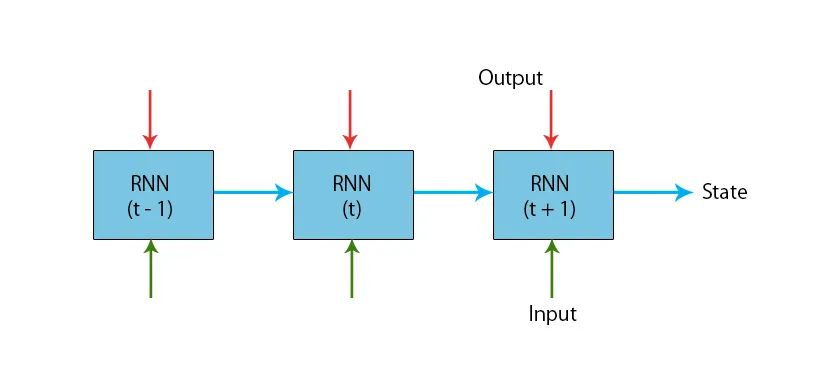
RNN-modellene har et minne som alltid husker hva som ble gjort i tidligere trinn og hva som er beregnet. Den samme oppgaven blir utført på alle inngangene, og RNN bruker den samme parameteren for hver av inngangene. Ettersom det tradisjonelle nevrale nettverket har uavhengige sett med input og output, er de mer komplekse enn RNN.
La oss prøve å forstå det gjentatte nevrale nettverket ved hjelp av et eksempel.
La oss si at vi har et nevralt nettverk med 1 inndatasjikt, 3 skjulte lag og 1 utgangslag.
Når vi snakker om andre eller tradisjonelle nevrale nettverk, vil de ha sine egne sett av skjevheter og vekter i skjulte lag som (w1, b1) for skjult lag 1, (w2, b2) for skjult lag 2 og (w3, b3) ) for det tredje skjulte laget, hvor: w1, w2 og w3 er vektene og, b1, b2 og b3 er forspenningene.
Gitt dette kan vi si at hvert lag ikke er avhengig av andre, og at de ikke kan huske noe om forrige innspill:
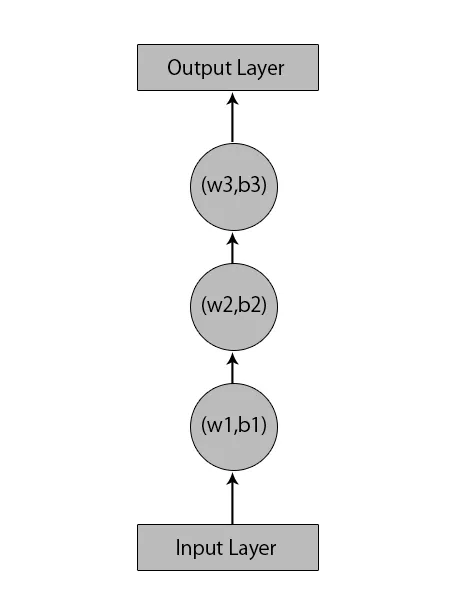
Hva en RNN vil gjøre er følgende:
- De uavhengige lagene blir konvertert til det avhengige laget. Dette gjøres ved å tilveiebringe de samme skjevhetene og vektene til alle lagene. Dette reduserer også antall parametere og lag i det tilbakevendende nevrale nettverket, og det hjelper RNN å huske den forrige utdataene ved å sende ut forrige utdata som inngang til det kommende skjulte laget.
- For å oppsummere, kan alle de skjulte lagene forbindes sammen til et enkelt tilbakevendende lag slik at vektene og skjevheten er de samme for alle de skjulte lagene.
Så et tilbakevendende nevralt nettverk vil se noe slik ut nedenfor:
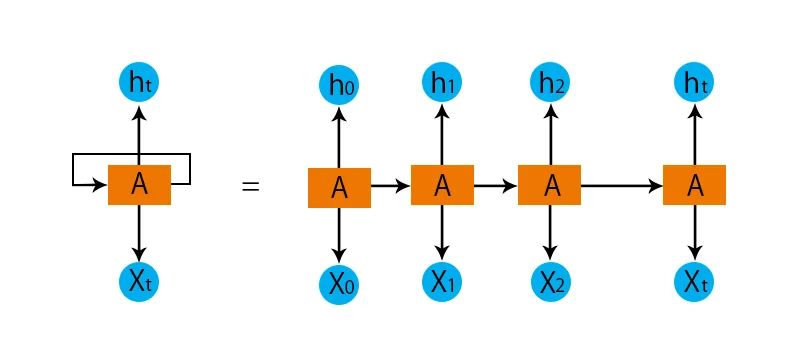
Nå er det på tide å håndtere noen av ligningene for en RNN-modell.
- For beregning av gjeldende tilstand,
h t= f (h t-1, x t ),
Hvor:
x t er inngangstilstanden
h t-1 er den forrige tilstanden,
h t er gjeldende tilstand.
- For beregning av aktiveringsfunksjonen
h t= tanh (W hh h t-1 +W xh x t ),
Hvor:
W xh er vekten ved tilførselsneuron,
Whh er vekten ved tilbakevendende nevron.
- For beregning av output:
Y t =W hy h t.
Hvor,
Y t er output og,
Vi er vekten ved utgangssjiktet.
Trinn for å trene et tilbakevendende nevralt nettverk
- I inngangslagene sendes den første inngangen med alle samme vekt- og aktiveringsfunksjon.
- Ved å bruke gjeldende inngang og forrige statusutgang, beregnes gjeldende tilstand.
- Nå vil nåværende tilstand h t bli h t-1 for andre gangstrinn.
- Dette fortsetter å gjenta for alle trinnene og for å løse et bestemt problem, kan det gå så mange ganger å bli med i informasjonen fra alle de foregående trinnene.
- Det siste trinnet blir deretter beregnet av den nåværende tilstanden til den endelige tilstanden og alle andre tidligere trinn.
- Nå genereres en feil ved å beregne forskjellen mellom den faktiske produksjonen og den genererte effekten av RNN-modellen vår.
- Det siste trinnet er når prosessen med tilbakepropagering oppstår der feilen tilbakeprogrammeres for å oppdatere vektene.
Fordeler med tilbakevendende nevrale nettverk
- RNN kan behandle innganger av hvilken som helst lengde.
- En RNN-modell er modellert for å huske hver informasjon gjennom hele tiden, noe som er veldig nyttig i enhver tidsserie prediktor.
- Selv om inngangsstørrelsen er større, øker ikke modellstørrelsen.
- Vektene kan deles på tvers av tidstrinnene.
- RNN kan bruke sitt interne minne til å behandle den vilkårlige serien med innganger, noe som ikke er tilfelle med fremtidige nevrale nettverk.
Ulemper med tilbakevendende nevrale nettverk
- På grunn av sin tilbakevendende natur er beregningen treg.
- Opplæring av RNN-modeller kan være vanskelig.
- Hvis vi bruker relu eller tanh som aktiveringsfunksjoner, blir det veldig vanskelig å behandle sekvenser som er veldig lange.
- Utsatt for problemer som eksplodering og gradient forsvinner.
Konklusjon
I denne artikkelen har vi lært en annen type kunstig nevralt nettverk kalt tilbakevendende nevralt nettverk, vi har fokusert på hovedforskjellen som gjør at RNN skiller seg ut fra andre typer nevrale nettverk, områdene der det kan brukes mye, slik som i talegjenkjenning og NLP (Natural Language Processing). Videre har vi gått bak arbeidet med RNN-modeller og funksjoner som brukes til å bygge en robust RNN-modell.
Anbefalte artikler
Dette er en guide til tilbakevendende nevrale nettverk. Her diskuterer vi introduksjonen, hvordan det fungerer, trinn, fordeler og ulemper ved RNN, etc. Du kan også gå gjennom andre foreslåtte artikler for å lære mer -- Hva er nevrale nettverk?
- Maskiner for læring av maskiner
- Introduksjon til kunstig intelligens
- Introduksjon til Big Data Analytics
- Implementering av nevrale nettverk