
Hva er SVM-algoritme?
SVM står for Support Vector Machine. SVM er en overvåket maskinlæringsalgoritme som ofte brukes til klassifiserings- og regresjonsutfordringer. Vanlige applikasjoner av SVM-algoritmen er Intrusion Detection System, Håndskriftgjenkjenning, Protein Structure Prediction, Detecting Steganography in digital images, etc.
I SVM-algoritmen er hvert punkt representert som et dataelement i det n-dimensjonale rommet der verdien til hver funksjon er verdien av en spesifikk koordinat.
Etter planlegging er klassifisering utført ved å finne hype-plan som skiller to klasser. Se bildet under for å forstå dette konseptet.
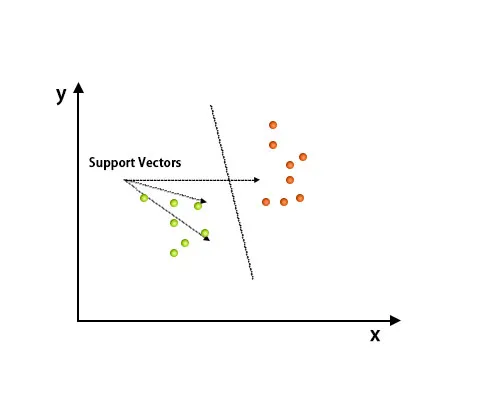
Support Vector Machine-algoritmen brukes hovedsakelig for å løse klassifiseringsproblemer. Støttevektorer er ikke annet enn koordinatene til hvert dataelement. Support Vector Machine er en grense som skiller to klasser ved hjelp av hyperplan.
Hvordan fungerer SVM-algoritmen?
I avsnittet ovenfor har vi diskutert differensiering av to klasser ved bruk av hyperplan. Nå skal vi se hvordan fungerer denne SVM-algoritmen.
Scenario 1: Identifiser riktig hyperplan
Her har vi tatt tre hyperplaner, A, B og C. Nå må vi identifisere riktig hyperplan for å klassifisere stjerne og sirkel.
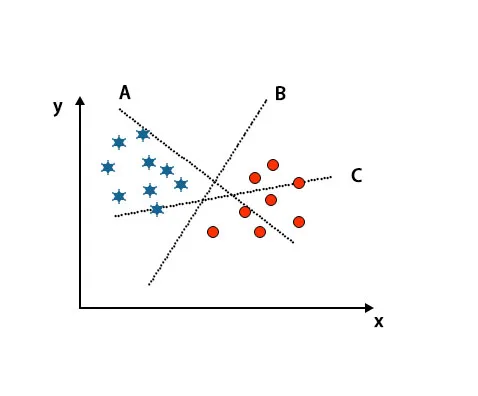
For å identifisere riktig hyperplan bør vi kjenne tommelfingerregelen. Velg hyperplan som skiller to klasser. I det ovennevnte bildet skiller hyperplan B to klasser veldig godt.
Scenario 2: Identifiser riktig hyperplan
Her har vi tatt tre hyperplaner, dvs. A, B, og C. Disse tre hyperplanene skiller allerede klasser veldig godt.
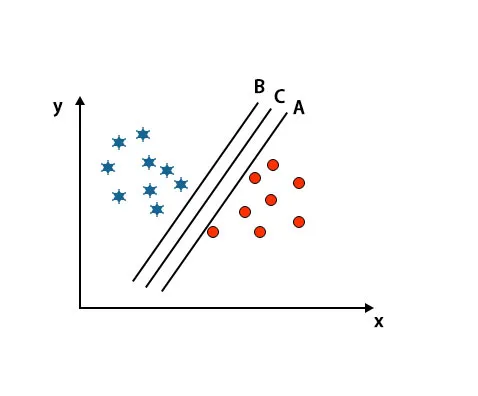
I dette scenariet, for å identifisere riktig hyperplan, øker vi avstanden mellom de nærmeste datapunktene. Denne avstanden er ingenting annet enn en margin. Se bildet under.
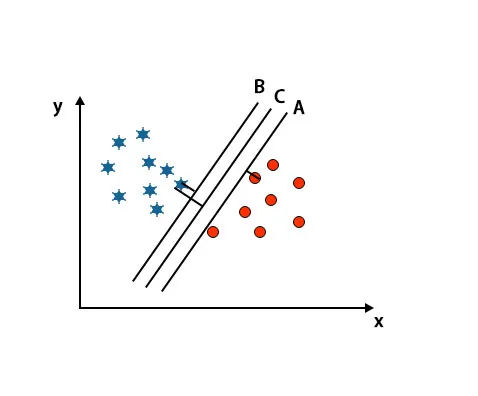
I det ovennevnte bildet er marginen til hyperplan C høyere enn hyperplanet A og hyperplan B. Så i dette scenariet er C det riktige hyperplanet. Hvis vi velger hyperplanet med en minimumsmarginal, kan det føre til feilklassifisering. Derfor valgte vi hyperplan C med maksimal margin på grunn av robusthet.
Scenario 3: Identifiser riktig hyperplan
Merk: For å identifisere hyperplanet, følg de samme reglene som nevnt i de foregående seksjonene.
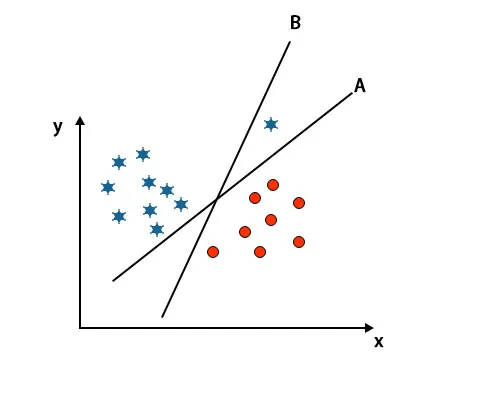
Som du kan se i det ovennevnte bildet, er marginen til hyperplan B høyere enn margen til hyperplan A, det er derfor noen vil velge hyperplan B som høyre. Men i SVM-algoritmen velger den det hyperplanet som klassifiserer klasser nøyaktig før maksimal margin. I dette scenariet har hyperplan A klassifisert alt nøyaktig, og det er en viss feil med klassifiseringen av hyperplan B. Derfor er A det riktige hyperplanet.
Scenario 4: Klassifiser to klasser
Som du ser i bildet under, kan vi ikke skille to klasser ved å bruke en rett linje fordi en stjerne ligger som en utligger i den andre sirkelklassen.
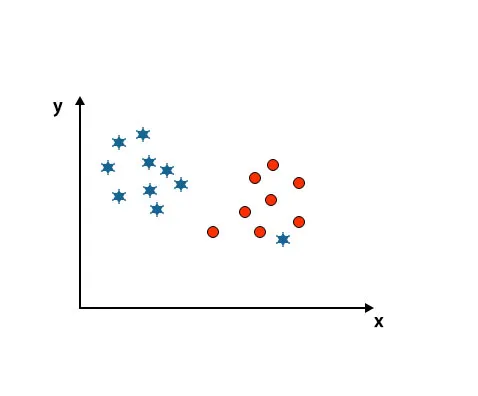
Her er en stjerne i en annen klasse. For stjerneklasse er denne stjernen den overordnede. På grunn av robusthetsegenskapen til SVM-algoritmen, vil den finne riktig hyperplan med høyere margin ignorerer en uteligger.
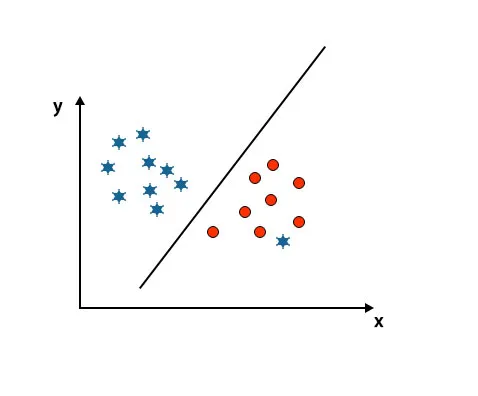
Scenario 5: Fin hyperplan for å skille klasser
Til nå har vi sett lineært hyperplan. I bildet nedenfor har vi ikke lineært hyperplan mellom klasser.
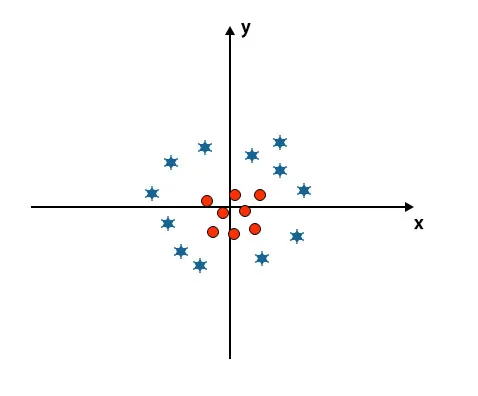
For å klassifisere disse klassene introduserer SVM noen tilleggsfunksjoner. I dette scenariet skal vi bruke denne nye funksjonen z = x 2 + y 2.
Plotter alle datapunkter på x- og z-aksen.

Merk
- Alle verdiene på z-aksen skal være positive fordi z er lik summen av x kvadrat og y kvadrat.
- I det ovennevnte plottet er røde sirkler lukket for opprinnelsen til x-aksen og y-aksen, noe som fører verdien til z til lavere og stjernen er nøyaktig motsatt av sirkelen, det er borte fra opprinnelsen til x-aksen og y-aksen, noe som fører verdien til z til høy.
I SVM-algoritmen er det enkelt å klassifisere ved å bruke lineært hyperplan mellom to klasser. Men spørsmålet som oppstår her er bør vi legge til denne funksjonen i SVM for å identifisere hyperplan. Så svaret er nei, for å løse dette problemet har SVM en teknikk som er kjent som et kjernetriks.
Kernel trick er funksjonen som transformerer data til en passende form. Det er forskjellige typer kjernefunksjoner som brukes i SVM-algoritmen, dvs. Polynomial, lineær, ikke-lineær, Radial Base-funksjon, etc. Her konverteres lavdimensjonalt input-rom til et høyere-dimensjonalt rom ved bruk av kernel trick.
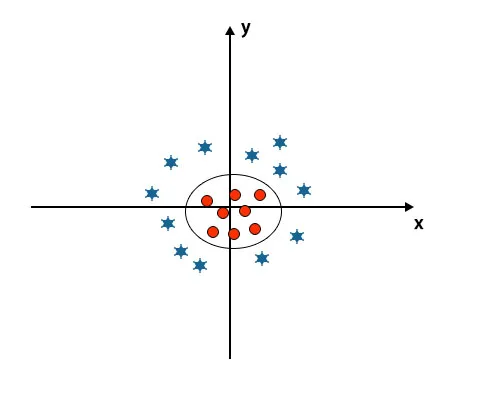
Når vi ser på hyperplanet opprinnelsen til aksen og y-aksen, ser det ut som en sirkel. Se bildet under.
Fordeler med SVM-algoritme
- Selv om inndata er ikke-lineære og ikke-separerbare, genererer SVM-er nøyaktige klassifiseringsresultater på grunn av deres robusthet.
- I beslutningsfunksjonen bruker den et undergruppe av treningspunkter kalt støttevektorer, og dermed er det minneeffektivt.
- Det er nyttig å løse ethvert komplekst problem med en passende kjernefunksjon.
- I praksis generaliseres SVM-modeller, med mindre risiko for overmasse i SVM.
- SVM-er fungerer utmerket for tekstklassifisering og når du finner den beste lineære separatoren.
Ulemper med SVM-algoritme
- Det tar lang treningstid når du jobber med store datasett.
- Det er vanskelig å forstå den endelige modellen og individuell innvirkning.
Konklusjon
Den har blitt guidet til å støtte Vector Machine Algoritm, som er en maskinlæringsalgoritme. I denne artikkelen diskuterte vi hva som er SVM-algoritmen, hvordan den fungerer og det er fordelene i detalj.
Anbefalte artikler
Dette har vært en guide til SVM Algoritme. Her diskuterer vi dets arbeid med et scenario, fordeler og ulemper med SVM-algoritme. Du kan også se på følgende artikler for å lære mer -
- Data mining algoritmer
- Dataminingsteknikker
- Hva er maskinlæring?
- Machine Learning Tools
- Eksempler på C ++ algoritme