
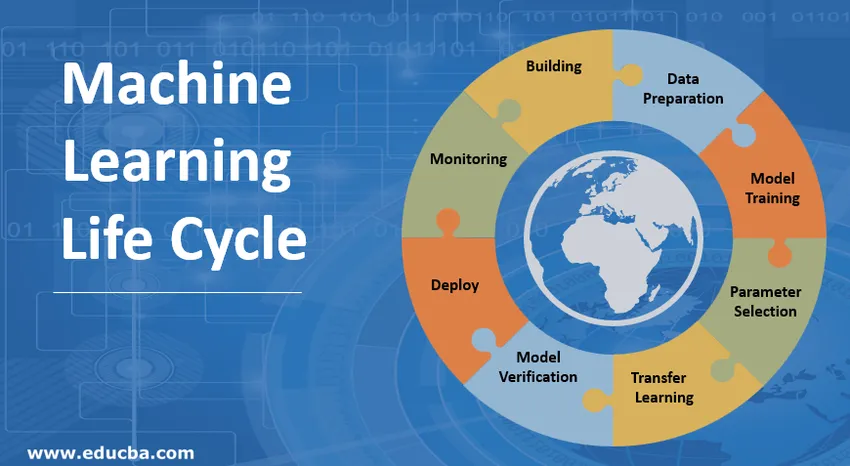
Introduksjon til maskinlæring (ML) livssyklus
Machine Learning Life Cycle handler om å tilegne seg kunnskap gjennom data. Maskinens læringssyklus beskriver en trefaseprosess som brukes av dataforskere og dataingeniører for å utvikle, trene og tjene modeller. Utvikling, trening og service av maskinlæringsmodeller er resultatet av en prosess som kalles maskinlæringens livssyklus. Det er et system som bruker data som input, og som har evnen til å lære og forbedre ved hjelp av algoritmer uten å være programmert til det. Maskinens læringssyklus har tre faser som vist på figuren gitt nedenfor: rørledningsutvikling, trening og inferens.
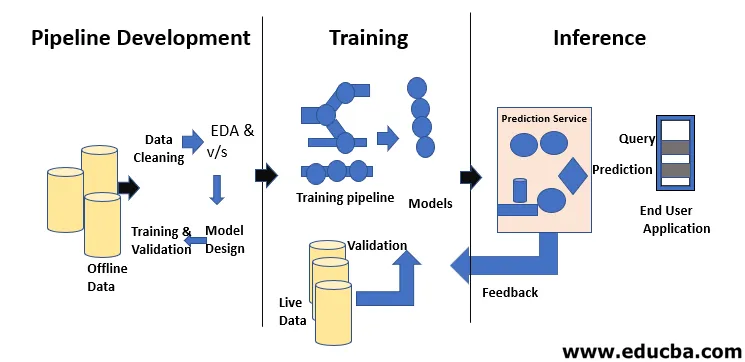
Det første trinnet i maskinens læringssyklus består av å transformere rå data til et renset datasett, det datasettet blir ofte delt og gjenbrukt. Hvis en analytiker eller en dataforsker som støter på problemer i mottatte data, må de få tilgang til de opprinnelige dataene og transformasjonsskriptene. Det er en rekke årsaker til at vi kanskje vil returnere til tidligere versjoner av modellene og dataene våre. For eksempel kan det å finne den tidligere beste versjonen kreve å søke gjennom mange alternative versjoner ettersom modeller uunngåelig ødelegger forutsigbarheten. Det er mange årsaker til denne forringelsen, som et skifte i distribusjonen av data som kan resultere i en rask nedgang i forutsigbarhet som kompensasjon for feil. Diagnostisering av denne nedgangen kan kreve å sammenligne treningsdata med direktedata, omskolere modellen, revidere tidligere designbeslutninger eller til og med redesigne modellen.
Læring av feil
Utvikling av modeller krever separate opplærings- og testing av datasett. Overforbruk av testdata under trening kan føre til dårlig generalisering og ytelse, da de kan føre til overdreven tilpasning. Kontekst spiller en viktig rolle her, og det er derfor nødvendig å forstå hvilke data som ble brukt til å trene de tiltenkte modellene og hvilke konfigurasjoner. Maskinens læringssyklus er datadrevet fordi modellen og resultatet av trening er knyttet til dataene den ble trent på. En oversikt over en ende til ende maskin læringsrørledning med et dataperspektiv er vist i figuren gitt nedenfor:
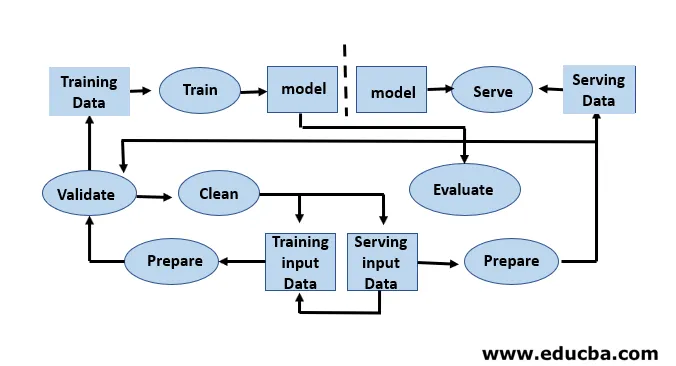
Trinn involvert i maskinlæring livssyklus
Machine Learning-utvikleren utfører kontinuerlig eksperimentering med nye datasett, modeller, programvarebiblioteker, innstiller parametere for å optimalisere og forbedre modellnøyaktigheten. Siden modellytelsen er helt avhengig av inputdataene og treningsprosessen.
1. Bygge maskinlæringsmodellen
Dette trinnet bestemmer hvilken type modell som er basert på applikasjonen. Den finner også ut at bruken av modellen i modellinnlæringsstadiet slik at de kan utformes riktig i samsvar med behovet for en tiltenkt applikasjon. En rekke maskinlæringsmodeller er tilgjengelige, for eksempel Supervised-modellen, Unsupervised-modellen, klassifiseringsmodeller, regresjonsmodeller, grupperingsmodeller og forsterkende læringsmodeller. En nær innsikt er avbildet i figuren gitt nedenfor:
2. Forberedelse av data
En rekke data kan brukes som input for maskinlæringsformål. Disse dataene kan komme fra en rekke kilder, for eksempel en virksomhet, farmasøytiske selskaper, IoT-enheter, bedrifter, banker, sykehus osv. Store mengder data blir gitt på læringstrinnet til maskinen, ettersom antallet data øker, justeres det mot gir ønskede resultater. Disse utgangsdataene kan brukes til analyse eller mates som input til andre maskinlæringsapplikasjoner eller systemer som de vil fungere som et frø for.
3. Modelltrening
Denne fasen er opptatt av å lage en modell ut fra dataene som er gitt til den. På dette stadiet blir en del av treningsdataene brukt til å finne modellparametere som koeffisientene til et polynom eller vekter av i maskinlæring som hjelper til med å minimere feilen for det gitte datasettet. De resterende data blir deretter brukt til å teste modellen. Disse to trinnene gjentas generelt flere ganger for å forbedre ytelsen til modellen.
4. Valg av parameter
Det innebærer valg av parametere tilknyttet opplæringen som også kalles hyperparametre. Disse parametrene styrer effektiviteten av treningsprosessen, og resultatene av modellen avhenger til slutt av dette. De er veldig viktige for en vellykket produksjon av maskinlæringsmodellen.
5. Overfør læring
Siden det er mange fordeler med å gjenbruke maskinlæringsmodeller på tvers av forskjellige domener. Til tross for at en modell ikke kan overføres mellom forskjellige domener direkte, blir den således brukt til å tilveiebringe et startmateriale for å begynne opplæringen av en neste trinnmodell. Dermed reduserer det treningstiden betydelig.
6. Verifisering av modeller
Innspillet til dette trinnet er den trente modellen produsert av modellinnlæringsstadiet, og utgangen er en bekreftet modell som gir tilstrekkelig informasjon til at brukerne kan bestemme om modellen er egnet for den tiltenkte bruken. Dermed er dette stadiet i maskinlæringssyklusen opptatt av at en modell fungerer som den skal når den behandles med usynlige innganger.
7. Distribuer maskinlæringsmodellen
I dette stadiet av maskinens læringssyklus bruker vi å integrere maskinlæringsmodeller i prosesser og applikasjoner. Det endelige målet med dette stadiet er riktig funksjonalitet av modellen etter distribusjon. Modellene bør brukes på en slik måte at de kan brukes til slutninger, så vel som de bør oppdateres regelmessig.
8. Overvåking
Det innebærer inkludering av sikkerhetstiltak for å sikre at modellen fungerer riktig i løpet av levetiden. For å få dette til er det nødvendig med riktig styring og oppdatering.
Fordel med maskinlæring livssyklus
Maskinlæring gir fordelene med kraft, hastighet, effektivitet og intelligens gjennom læring uten eksplisitt å programmere disse til en applikasjon. Det gir muligheter for forbedret ytelse, produktivitet og robusthet.
Konklusjon - Machine Learning Life Cycle
Maskinlæringssystemer blir viktigere dag for dag ettersom datamengden involvert i forskjellige applikasjoner øker raskt. Maskinlæringsteknologi er hjertet i smarte enheter, husholdningsapparater og online tjenester. Suksessen til maskinlæring kan utvides til å omfatte sikkerhetskritiske systemer, datastyring, høy ytelse databehandling, som har et stort potensial for applikasjonsdomener.
Anbefalte artikler
Dette er en guide til Machine Learning Life Cycle. Her diskuterer vi introduksjonen, Læring av feil, trinn involvert i maskinlæring livssyklus og fordeler. Du kan også gå gjennom de andre foreslåtte artiklene våre for å lære mer–
- Kunstige etterretningsfirmaer
- QlikView-settanalyse
- IoT økosystem
- Cassandra datamodellering