
Forskjellen mellom maskinlæring og prediktiv analyse
Maskinlæring er et område innen informatikk, som i økende grad sprang og bundet i disse dager. Nyere fremskritt innen maskinvareteknologier som resulterte i en enorm økning i datakraft som GPU (grafiske prosesseringsenheter) og avansement i nevrale nettverk, maskinlæring har blitt et summende ord. I hovedsak kan vi bruke maskinlæringsteknikker bygge algoritmer for å trekke ut data og se viktig skjult informasjon fra den. Prediktiv analyse er også en del av maskinlæringsdomenet som er begrenset til å forutsi fremtidig utfall fra data basert på tidligere mønstre. Selv om prediktiv analyse har vært i bruk siden mer enn to tiår, hovedsakelig i bank- og finanssektoren, har anvendelse av maskinlæring fått prominens i den senere tid med algoritmer som objektdeteksjon fra bilder, tekstklassifisering og anbefalingssystemer.
Maskinlæring
Maskinlæring bruker internt statistikk, matematikk og informatikk for å bygge logikk for algoritmer som kan utføre klassifisering, prediksjon og optimalisering i både sanntid og batchmodus. Klassifisering og regresjon er to hovedklasser av et problem under maskinlæring. La oss forstå både Machine Learning og Predictive Analytics i detalj.
Klassifisering
Under disse bøttene med et problem, har vi en tendens til å klassifisere et objekt basert på dets forskjellige egenskaper i en eller flere klasser. For eksempel å klassifisere en bankkunde for å være kvalifisert for et boliglån eller ikke basert på kredittloggen. Vanligvis vil vi ha transaksjonsdata tilgjengelig for kunden, for eksempel hans alder, inntekt, utdannelsesbakgrunn, hans arbeidserfaring, bransje han jobber i, antall avhengige, månedlige utgifter, eventuelle tidligere lån, hans utgiftsmønster, kreditthistorie osv. og basert på denne informasjonen vil vi pleie å beregne om han skulle få lån eller ikke.
Det er mange standardlæringsalgoritmer for maskiner som brukes til å løse klassifiseringsproblemet. Logistisk regresjon er en slik metode, sannsynligvis mest brukt og mest kjent, også den eldste. Bortsett fra det har vi også noen av de mest avanserte og kompliserte modellene som strekker seg fra beslutnings tre til tilfeldig skog, AdaBoost, XP boost, støttevektormaskiner, naive baize og nevrale nettverk. Siden de siste par årene kjører dyp læring i forkant. Typisk brukes nevralt nettverk og dyp læring for å klassifisere bilder. Hvis det er hundre tusen bilder av katter og hunder og du ønsker å skrive en kode som automatisk kan skille bilder av katter og hunder, kan det være lurt å gå til dype læringsmetoder som et innviklet nevralt nettverk. Lommelykt, kafé, sensorflyt, etc. er noen av de populære bibliotekene i python for å gjøre dyp læring.
For å måle nøyaktigheten til regresjonsmodeller brukes beregninger som falsk positiv hastighet, falsk-negativ hastighet, følsomhet osv.
regresjon
Regresjon er en annen klasse problemer i maskinlæring der vi prøver å forutsi den kontinuerlige verdien av en variabel i stedet for en klasse i motsetning til i klassifiseringsproblemer. Regresjonsteknikker brukes vanligvis til å forutsi aksjekursen på en aksje, salgsprisen på et hus eller en bil, etterspørsel etter en viss vare osv. Når tidsserieegenskaper også spiller inn, blir regresjonsproblemer veldig interessante å løse. Lineær regresjon med vanlig minste firkant er en av de klassiske maskinlæringsalgoritmene i dette domenet. For tidsseriebasert mønster brukes ARIMA, eksponentielt glidende gjennomsnitt, vektet glidende gjennomsnitt og enkelt glidende gjennomsnitt.
For å måle nøyaktigheten til regresjonsmodeller brukes metrics som å bety kvadratfeil, absolutt gjennomsnittlig kvadratfeil, rotmåls kvadratfeil osv.
Predictive Analytics
Det er noen områder med overlapping mellom maskinlæring og prediktiv analyse. Selv om vanlige teknikker som logistikk og lineær regresjon hører under både maskinlæring og prediktiv analyse, er avanserte algoritmer som et beslutnings tre, tilfeldig skog, etc. i det vesentlige maskinlæring. Under prediktiv analyse forblir målet med problemene veldig smalt der hensikten er å beregne verdien av en bestemt variabel på et fremtidig tidspunkt. Predictive analytics er mye statistikk lastet mens maskinlæring er mer en blanding av statistikk, programmering og matematikk. En typisk prediktiv analytiker bruker tiden sin på å beregne t square, f statistikk, Innova, chi-square eller vanlig minst square. Spørsmål som om dataene normalt er distribuert eller skjevt, bør studentens t-distribusjon brukes eller bjellekurve brukes, skal alfa tas med 5% eller 10% feil dem hele tiden. De ser etter djevelen i detaljer. En maskinlæringsingeniør plager ikke med mange av disse problemene. Hodepinen deres er helt annerledes, de finner seg selv fast på forbedring av nøyaktighet, falsk-positiv hastighetsminimering, utbedre håndtering, normalisering av området eller validering av k fold.
En prediktiv analytiker bruker stort sett verktøy som Excel. Scenario eller målsøking er deres favoritt. De bruker av og til VBA eller mikroskriving og skriver knapt noen lang kode. En maskinlærende ingeniør bruker all sin tid på å skrive kompliserte koder utover vanlig forståelse, han bruker verktøy som R, Python, Saas. Programmering er deres viktigste arbeid, å fikse feil og teste på de forskjellige landskapene en daglig rutine.
Disse forskjellene gir også en stor forskjell i etterspørsel og lønn. Mens prediktive analytikere er det i går, er maskinlæring fremtiden. En typisk maskinlæringsingeniør eller dataforsker (som det meste kalles i disse dager) betales 60-80% mer enn en typisk programvareingeniør eller prediktiv analytiker for den saks skyld, og de er nøkkeldriveren i dagens teknologiaktiverte verden. Uber, Amazon og nå selvkjørende biler er også mulig på grunn av dem.
Sammenligning fra hodet til hodet mellom Machine Learning vs Predictive Analytics (Infographics)
Nedenfor er topp 7-sammenligningen mellom Machine Learning vs Predictive Analytics
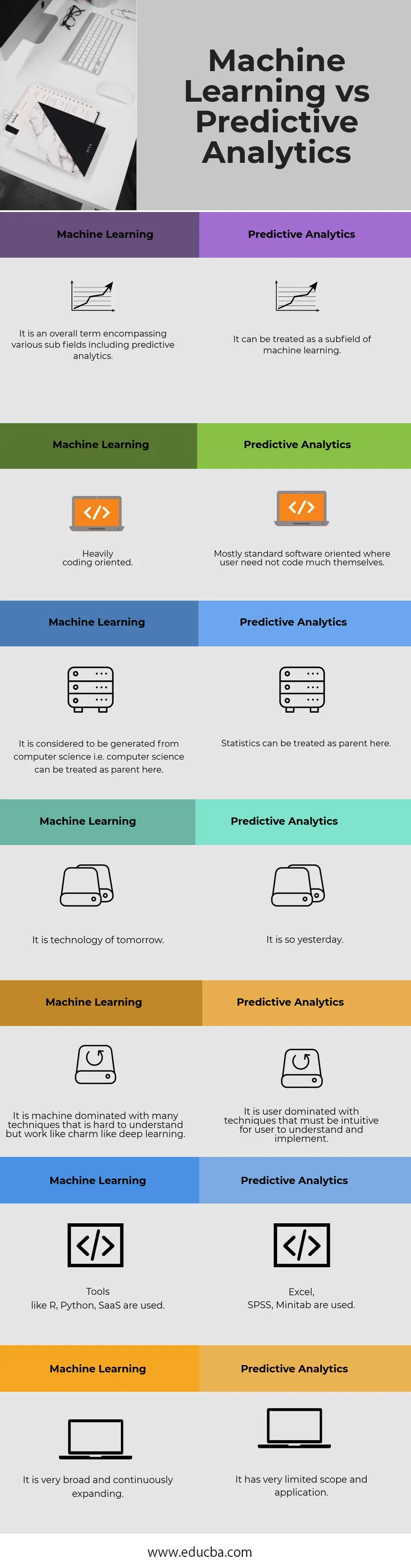
Sammenligningstabel for Machine Learning vs Predictive Analytics
Nedenfor er den detaljerte forklaringen av Machine Learning vs Predictive Analytics
| Maskinlæring | Predictive Analytics |
| Det er et overordnet begrep som omfatter forskjellige underfelt inkludert prediktiv analyse. | Det kan behandles som et underfelt for maskinlæring. |
| Tungt kodingsorientert. | Stort sett standard programvareorientert der en bruker ikke trenger å kode mye selv |
| Det anses å være generert fra informatikk, dvs. datavitenskap kan behandles som foreldrene her. | Statistikk kan behandles som foreldre her. |
| Det er morgendagens teknologi. | Det er slik i går. |
| Det er en maskin dominert av mange teknikker som er vanskelig å forstå, men fungerer som sjarm som dyp læring. | Det er brukerdominert med teknikker som må være intuitivt for en bruker å forstå og implementere. |
| Verktøy som R, Python, SaaS brukes. | Excel, SPSS, Minitab brukes. |
| Den er veldig bred og utvides kontinuerlig. | Det har et veldig begrenset omfang og anvendelse. |
Konklusjon - Machine Learning vs Predictive Analytics
Fra diskusjonen ovenfor om både Machine Learning og Predictive Analytics, er det tydelig at prediktiv analyse i utgangspunktet er et underfelt for maskinlæring. Maskinlæring er mer allsidig og er i stand til å løse et bredt spekter av problemer.
Anbefalt artikkel
Dette har vært en guide til Machine Learning vs Predictive Analytics, deres betydning, sammenligning av topp mot hod, nøkkelforskjeller, sammenligningstabell og konklusjon. Du kan også se på følgende artikler for å lære mer -
- Lær Big Data Vs Machine Learning
- Forskjellen mellom Data Science vs Machine Learning
- Sammenligning mellom Predictive Analytics vs Data Science
- Data Analytics vs Predictive Analytics - Hvilken er nyttig