
Introduksjon til Hive Group av
Grupper etter som navnet antyder, vil den gruppere posten som tilfredsstiller visse kriterier. I denne artikkelen skal vi se på gruppen etter HIVE. I arv RDBMS som MySQL, SQL, etc, er gruppe etter en av de eldste klausulene som blir brukt. Nå har den funnet sin plass på en lignende måte i filbasert datalagring kjent som HIVE.
Vi vet at Hive har overgått mange arv RDBMS i håndtering av enorme data uten at en krone er brukt på leverandører for å vedlikeholde databasene og serverne. Vi trenger bare å konfigurere HDFS for å håndtere bikube. Generelt går vi til tabeller fordi sluttbrukeren kan tolke fra strukturen og kan spørre etter som filer vil være klønete for dem. Men vi måtte gjøre dette ved å betale leverandørene for å skaffe servere og vedlikeholde dataene våre i form av tabeller. Så Hive gir den kostnadseffektive mekanismen der den drar nytte av filbaserte systemer (måten bikuben lagrer dataene sine) så vel som tabeller (tabellstruktur for sluttbrukere å spørre etter).
Gruppe av
Grupper ved å bruke de definerte kolonnene fra Hive-tabellen for å gruppere dataene. Du kan også tenke at du har en tabell med folketellingsdata fra hver by i alle delstatene der bynavn og statnavn er en av kolonnene. Nå i spørringen, hvis vi grupperer etter stater, vil alle dataene fra forskjellige byer i en bestemt stat bli gruppert sammen, og man kan enkelt visualisere dataene bedre nå før måten gruppen ble brukt på.
Syntax of Hive Group By
Den generelle syntaks for gruppen ved klausul er som nedenfor:
SELECT (ALL | DISTINCT) select_expr, select_expr, …
FROM table_reference
(WHERE where_condition) (GROUP BY col_list) (HAVING having_condition) (ORDER BY col_list)) (LIMIT number);
eller for enklere spørsmål,
from Group By
Select department, count(*) from the university.college Group By department;
Her viser avdelingen til en av kolonnene i college-tabellen som er til stede i universitetsdatabasen, og verdien av den er forskjellig i avdelinger som kunst, matematikk, ingeniørfag, osv. La oss se noen eksempler for å demonstrere gruppe etter.
Jeg har laget et eksempel tabell deck_of_cards for å demonstrere gruppen etter. Opprettelsen av tabellerklæringen er som følger:
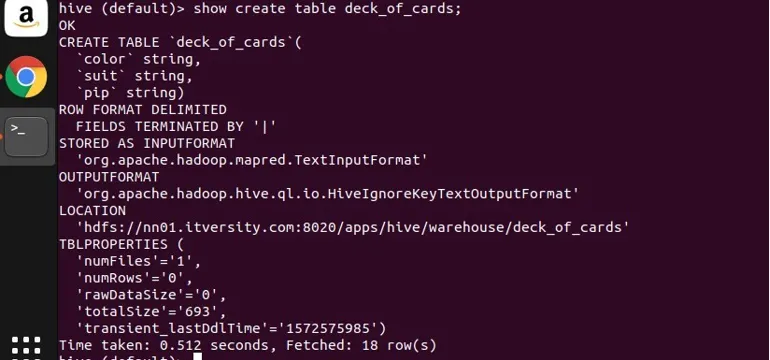
du kan se ovenfra at den har tre strengen kolonner farge, dress og pip. La meg skrive et spørsmål for å gruppere dataene etter fargen og få antallet.
select color, count(*) from deck_of_cards group by color;
Hive tar utgangspunktet spørringen ovenfor for å konvertere den til kartreduseringsprogrammet ved å generere tilsvarende java-kode og krukkefil og deretter utføre. Denne prosessen kan ta litt tid, men den kan definitivt håndtere store data sammenlignet med tradisjonelle RDBMS. Se skjermbildet nedenfor med den detaljerte loggen for å utføre spørringen ovenfor.
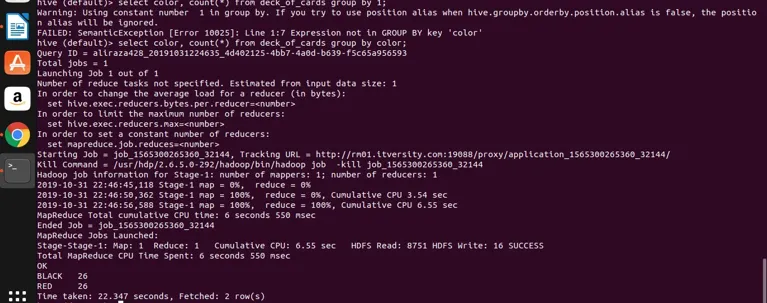
Du kan se at SVART er 26 og RØD er 26.
la oss nå bruke gruppering på to kolonner (farge og farge og få gruppetelling) og se resultatet nedenfor.
Select color, suit, count(*) from deck_of_cards group by color, suit
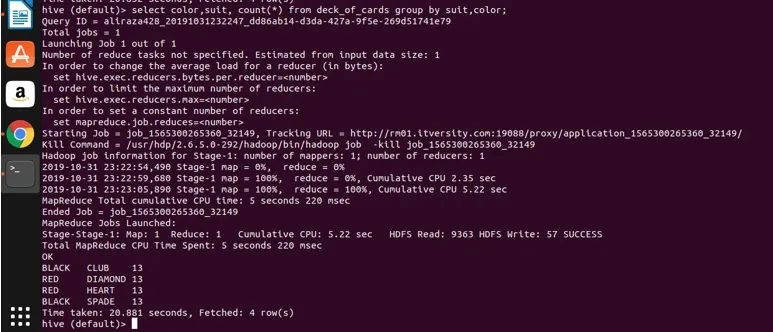
I utgangspunktet er det fire forskjellige grupper over Club, Spade som har farge svart og Diamond og hjerte som er fargerøde.
Lagring av resultatet fra gruppe etter årsak i en annen tabell
Hive gir også, som alle andre RDBMS, funksjonen til å sette inn dataene med opprette tabellsetninger. La oss se på å lagre resultatet fra et valgt uttrykk ved å bruke en gruppe ved i en annen tabell. La meg bruke selve spørringen ovenfor der jeg har brukt to kolonner i gruppe etter.
create table cards_group_by
as
select color, suit, count(*) from deck_of_cards
group by color, suit;
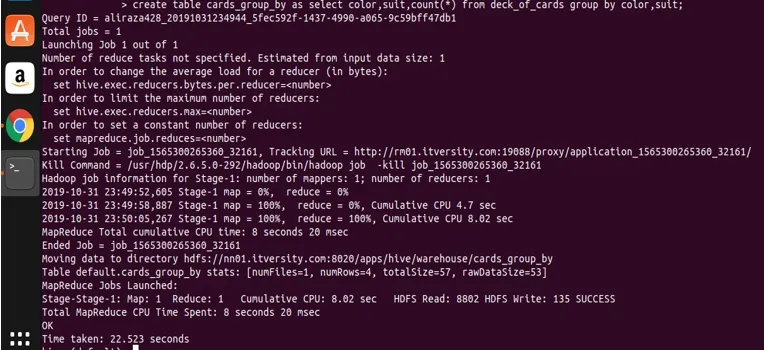
La oss nå spørre i den opprettede tabellen for å se og validere dataene.

La oss nå begrense resultatet av gruppen ved å bruke klausul. Som vist i den generiske syntaks kan vi bruke begrensninger på gruppen ved å bruke. Her bruker jeg tabellen ordser_items, og strukturen er som følger av beskrivelsen.
hive (retail_db_ali)> describe order_items;
OK
order_item_id int
order_item_order_id int
order_item_product_id int
order_item_quantity tinyint
order_item_subtotal float
order_item_product_price float
Time taken: 0.387 seconds, Fetched: 6 row(s)
select order_item_id, order_item_order_id from order_items group by order_item_id, order_item_order_id having order_item_order_id=5;
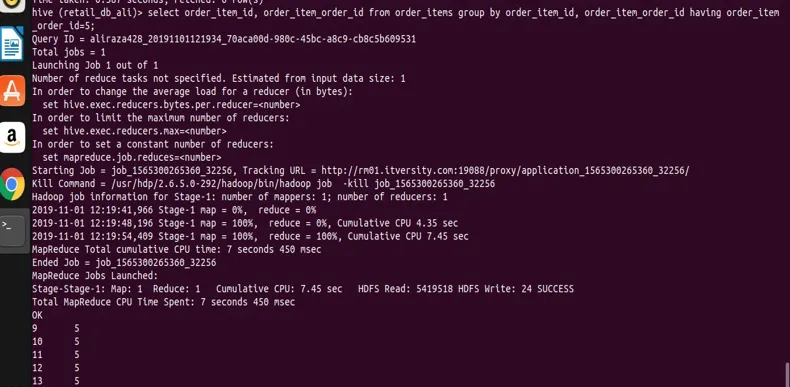
fra resultatet kan du se skjermbildet som vi bare har poster med order_item_order_id verdi 5.
Gruppe etter Sammenfatning
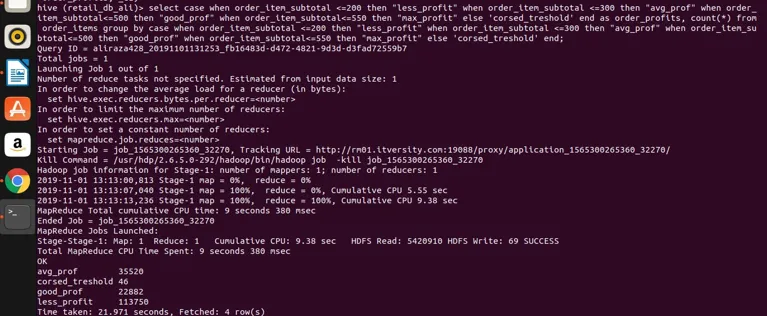
La oss nå se på litt komplekse spørsmål som involverer CASE-uttalelser med gruppen av. Vi bruker dette på order_items-tabellen. Vi vil se nedenfor at vi kan kategorisere de ikke-aggregerende kolonnene som vi ikke kan bruke gruppen direkte på.
Select
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end
as order_profits,
count(*) from order_items
group by
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end;
la oss utføre det i bikuben for å få resultater
Konklusjon - Hive Group av
slik at vi kan se at vi har gruppert order_item_subtotal i fire forskjellige kategorier (hvis du legger merke til at order_item_subtotal er en ikke-aggregerende kolonne og direkte gruppe ved ikke kan brukes på den), og vi har gruppert dem sammen og fått tellene deres også for verdiene som tilfredsstiller området som definert i valgt uttrykk. Her er den enkle regelen hvis kolonnen ikke er sammensatt og vårt utvalgte uttrykk er sammensatt, uansett hva der i valguttrykket som også skal være til stede i gruppen ved klausuluttrykk. Så vi har sett hvordan en berømt klausul RDBMS klausulgruppe av også kan brukes på Hive uten noen begrensninger. Det kan brukes på enkle utvalgte uttrykk. Samle og filtrere uttrykk, bli med uttrykk og komplekse CASE-uttrykk også.
Anbefalte artikler
Dette er en guide til Hive Group By. Her diskuterer vi gruppen etter, syntaks, eksempler på bikubegruppen etter med forskjellige forhold og implementering. Du kan også se på følgende artikler for å lære mer -
- Bli med i Hive
- Hva er en bikube?
- Hive Arkitektur
- Hive-funksjon
- Hive Bestill av
- Installasjon av bikube
- Topp 6 typer sammenføyninger i MySQL med eksempler