

Introduksjon til Data Mining
Her i denne artikkelen skal vi lære om introduksjonen til Data mining, siden mennesker har utvunnet jorda fra århundrer for å få tak i alle slags verdifulle materialer. Noen ganger mens gruvedrift oppdages ting fra bakken som ingen forventet å finne i utgangspunktet. For eksempel i 1898, under utgravningen av en grav for å finne mumier i Saqqara, Egypt, ble det funnet en tregjenstand som nøyaktig lignet et fly. Den ble datert tilbake til 200 f.Kr., for rundt 2200 år siden! Men hvilken mulig informasjon kan vi få fra et stort sett med data? Og selv om vi begynner å gruve det, er det noen sjanser for å få noen uventede resultater fra datasettet? Før det skal vi gå nærmere inn på hva som er Data Mining.
Hva er datamining?
- Det er i utgangspunktet utvinning av viktig informasjon / kunnskap fra et stort sett med data.
- Tenk på data som en stor grunn / steinete overflate. Vi vet ikke hva som er inni den, vi vet ikke om noe nyttig er under steinene.
- I denne introduksjonen til Data mining søker vi etter skjult informasjon, men uten noen formening om hvilken type informasjon vi ønsker å finne og hva vi planlegger å bruke den en gang til, finner vi den.
- Akkurat som i Concept tradisjonell gruvedrift, i Data mining er det også forskjellige teknikker og verktøy, som varierer i henhold til hvilken type data vi gruver, så vi har klarert at det som er data mining gjennom dette emnet for introduksjon til Data mining.
Eksempel på datamining
Vi har lært om introduksjonen til data mining i delen ovenfor og fortsetter nå med eksemplene på data mining, som er listet nedenfor:
- Så det er en mobilnettoperatør. De konsulterer en dataminerer for å grave i samtalepostene til operatøren. Ingen spesifikke mål er gitt til Data Miner.
- Et kvantitativt mål å finne minst 2 nye mønstre i løpet av en måned er gitt.
- Når dataminearbeideren begynner å grave i dataene, finner han et mønster av at det er mindre internasjonale samtaler på onsdag sammenlignet med andre dager.
- Denne informasjonen deles med ledelsen, og de kommer med planen om å redusere de internasjonale samtalen på onsdager og starte en kampanje.
- Samtaleprisene øker, kundene er fornøyde med lav samtalepris, flere kunder melder seg på og selskapet tjener mer penger! Vinn-vinn situasjon!
Ved å huske eksemplet ovenfor, la oss nå se på de forskjellige trinnene som er involvert i data mining.
Trinn involvert i Data Mining
Vi har lært om introduksjonen til data mining i delen ovenfor, og går nå videre med trinnene involvert i data mining, som er listet nedenfor: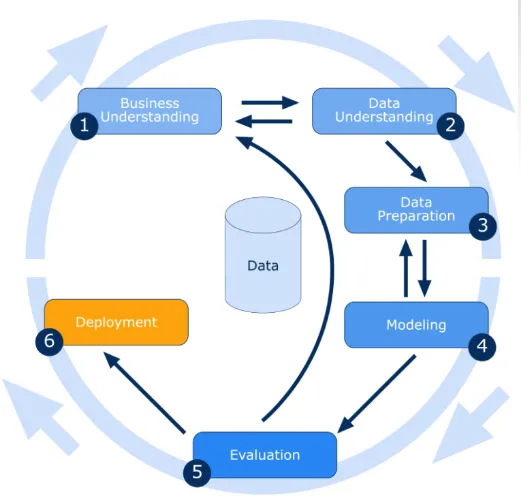
-
Forståelse av virksomheten
I denne introduksjonen til data mining, vil vi forstå alle aspekter av forretningsmessige mål og behov. Dagens situasjon vurderes ved å finne ressursene, forutsetningene og andre viktige faktorer. Følgelig etablere en god introduksjon til data mining plan for å oppnå både forretnings- og data mining mål.
-
Forståelse av data
Opprinnelig blir dataene samlet inn fra alle tilgjengelige kilder. Så velger vi det beste datasettet der vi kan hente ut dataene som kan være mer fordelaktig.
-
Forberedelse av data
Når datasettet er identifisert, blir det valgt, renset, konstruert og formatert i ønsket form.
-
Datamodellering
Det er en prosess med å renovere de gitte dataene i henhold til brukerens krav. en eller flere modeller kan opprettes i det forberedte datasettet, og til slutt må modellene vurderes nøye med å involvere interessenter for å sikre at opprettede modeller oppfyller forretningsinitiativer.
-
evaluering
Dette er en av de mest nødvendige prosessene innen data mining. Det inkluderer å gå gjennom alle aspekter av prosessen for å sjekke om det er mulig feil eller datalekkasje i prosessen. Også nye krav til virksomheten kan heves på grunn av de nye mønstrene som ble oppdaget.
-
Utplassering
Det betyr å ganske enkelt presentere kunnskapen på en slik måte at interessentene kan bruke den når de vil ha den. I eksemplet ovenfor viste det seg at internasjonale samtaler var mindre på onsdager, så denne informasjonen ble presentert for interessentene som igjen brukte denne informasjonen til sin fordel og økte fortjenesten.
Teknikker brukt i datamining
I avsnittet ovenfor har vi lært om introduksjonen til data mining, og vi går videre med teknikkene som brukes i data mining, som er listet nedenfor:
-
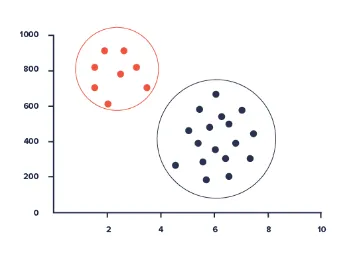
Cluster Analyse
Cluster Analyse gjør det mulig å identifisere en gitt brukergruppe i henhold til vanlige funksjoner i en database. Disse funksjonene kan omfatte alder, geografisk beliggenhet, utdanningsnivå og så videre.
-
Anomali Deteksjon
Det brukes til å bestemme når noe er merkbart forskjellig fra det vanlige mønsteret. Det brukes til å eliminere uoverensstemmelser eller uoverensstemmelser i databasen ved kilden.

-
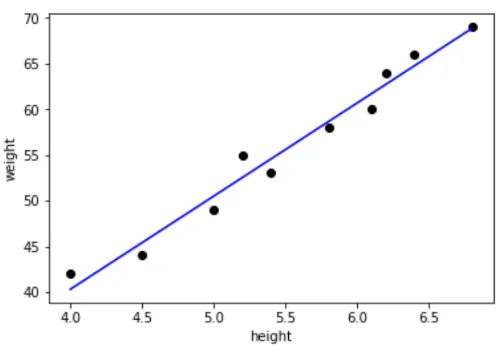
Regresjonsanalyse
Denne teknikken brukes til å lage prediksjoner basert på sammenhenger i datasettet. For eksempel kan man forutsi aksjekursen for et bestemt produkt ved å analysere fortidskursen og også ved å ta hensyn til de forskjellige faktorene som bestemmer aksjekursen. Eller som vist nedenfor, hvis vi har dataene om høyden og vekten til forskjellige personer, og gitt noe av høyden eller vekten, kan vi bestemme den andre verdien.
-
Klassifisering
Dette tar for seg tingene som har etiketter på den. Merk når det gjelder klyngedeteksjon, tingene hadde ikke en merkelapp i seg, og ved å bruke data mining måtte vi merke og forme i klynger, men i klassifisering er det eksisterende informasjon som lett kan klassifiseres ved hjelp av en algoritme. Et eksempel er spamfilter for e-post. Spamfilteret leveres med både relevante og spammeldinger (Treningsdata). Forskjellene mellom begge er identifisert, og gjør det mulig å klassifisere fremtidige e-poster riktig.

- Associativ læring
Den brukes til å analysere hvilke ting som har en tendens til å skje sammen enten i par eller større grupper. For eksempel folk som har en tendens til å kjøpe sitroner, kjøpe appelsiner også, folk som har en tendens til å kjøpe brød, kjøpe melk også og så videre. Så kjøpene som gjøres av alle kundene blir analysert og tingene som skjer sammen plasseres like ved for å øke salget. Så melk plasseres nær brød, sitroner plasseres ved siden av appelsiner og så videre.

Er datagruving etisk?
Så jeg planlegger en helgetur til Goa med en venn, jeg søker på internett etter gode steder å besøke i Goa. Neste gang jeg åpner internett, finner jeg annonser om forskjellige hoteller i Goa for opphold.
-
God ting?
Ja, internett har hjulpet meg å forenkle turen. Tross alt, hvis jeg bestemmer meg for å besøke Goa, vil jeg trenge å sove et sted, og en annonse som viser meg et hotell, er mye mer nyttig enn en annonse som viser meg tilfeldige klær å kjøpe.
-
Dårlig ting?
Ja! Hvorfor skulle et datagruveselskap som jeg aldri har hørt før, vite hvor jeg skal på ferie. Hva om jeg ikke har fortalt noen om denne turen, men her vet internett plutselig at jeg skal dit. Sannheten er at forretningsmodellen til datagruveselskapet er avhengig av dette. De samler inn disse dataene via informasjonskapsler og skript, så selger de dem til annonsører som på sin side prøver å selge meg noe annet (I dette tilfellet et hotellrom).
Så det kan være bra eller dårlig avhengig av måten vi ser på det. Vi kan også alltid slå av informasjonskapslene eller gå inkognito i tilfellet ovenfor. Selv om det er tilfelle, er en ting helt sikkert. Data mining er her for å bli.
Anbefalte artikler
Dette har vært en guide til Introduksjon til data mining. Her diskuterer vi betydningen, teknikkene og trinnene som er involvert i introduksjonen til data mining med et eksempel for å forstå bedre. Du kan også se på følgende artikler for å lære mer -
- Spørsmål om datagruving
- Predictive Analytics vs Data Mining
- Introduksjon til datavitenskap
- Hva er regresjonsanalyse?