

Introduksjon til lineær regresjonsanalyse
Det er ofte forvirrende å lære noe konsept som til og med er en del av vårt daglige liv. Men det er ikke et problem, vi kan hjelpe og utvikle oss til å lære av våre hverdagslige aktiviteter bare ved å analysere ting og ikke føle oss redde for å stille spørsmål. Hvorfor pris påvirker etterspørselen etter varene, hvorfor endring i rente påvirker pengemengden. Alle disse kan besvares ved en enkel tilnærming kjent som lineær regresjon. Den eneste kompleksiteten man føler når man arbeider med lineær regresjonsanalyse er identifisering av avhengige og uavhengige variabler.
Vi må finne hva som påvirker hva, og halvparten av problemet er løst. Vi må se om det er pris eller etterspørsel som påvirker hverandre oppførsel. Når vi først fikk vite hvilken som er den uavhengige variabelen og avhengige variabelen, er vi gode til å gå for analysen. Det er flere typer regresjonsanalyser tilgjengelig. Denne analysen avhenger av variablene som er tilgjengelige for oss.
De 3 typene regresjonsanalyse
Disse tre regresjonsanalysene har maksimal brukstilfeller i den virkelige verden, ellers er det mer enn 15 typer regresjonsanalyse. Typer regresjonsanalyse som vi skal diskutere er:
- Lineær regresjonsanalyse
- Flere lineære regresjonsanalyser
- Logistisk regresjon
I denne artikkelen vil vi fokusere på Simple Linear Regression analyse. Denne analysen hjelper oss med å identifisere forholdet mellom den uavhengige faktoren og den avhengige faktoren. Med enklere ord hjelper Regresjonsmodellen oss med å finne at hvordan endringene i den uavhengige faktoren påvirker den avhengige faktoren. Denne modellen hjelper oss på flere måter som:
- Det er en enkel og kraftig statistisk modell
- Det vil hjelpe oss med å lage spådommer og prognoser
- Det vil hjelpe oss å ta en bedre forretningsavgjørelse
- Det vil hjelpe oss å analysere resultatene og korrigere feil
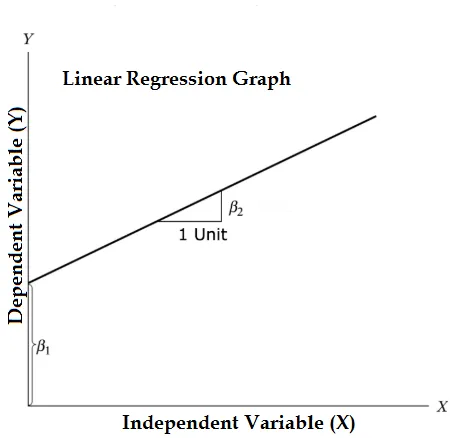
Ligningen av lineær regresjon og del den i relevante deler
Y = β1 + β2X + ϵ
- Hvor β1 i den matematiske terminologien kjent som avskjæring og β2 i den matematiske terminologien kjent som en skråning. De er også kjent som regresjonskoeffisienter. ϵ er feilbegrep, det er den delen av Y som regresjonsmodellen ikke kan forklare.
- Y er en avhengig variabel (andre termer som om hverandre kan brukes for avhengige variabler er responsvariabel, regressand, målt variabel, observert variabel, responderende variabel, forklart variabel, utfallsvariabel, eksperimentell variabel og / eller utgangsvariabel).
- X er en uavhengig variabel (regressorer, kontrollert variabel, manipulert en variabel, forklaringsvariabel, eksponeringsvariabel og / eller inngangsvariabel).
Problem: For å forstå hva som er lineær regresjonsanalyse tar vi "Cars" datasettet som kommer som standard i R-kataloger. I dette datasettet er det 50 observasjoner (i utgangspunktet rader) og 2 variabler (kolonner). Kolonnenavn er “Dist” og “Speed”. Her må vi se påvirkningen på avstandsvariabler på grunn av endringshastighetsvariabler. For å se strukturen til dataene kan vi kjøre en kode Str (datasett). Denne koden hjelper oss å forstå strukturen til datasettet. Disse funksjonalitetene hjelper oss å ta bedre beslutninger fordi vi har et bedre bilde i datasettet om datastrukturen. Denne koden hjelper oss å identifisere typen datasett.
Kode:

På samme måte for å sjekke statistikk sjekkpunktene til datasettet kan vi bruke kode Sammendrag (biler). Denne koden inneholder et gjennomsnitt, median, utvalg av datasettet på en gang, som forskeren kan bruke mens han håndterer problemet.
Produksjon:
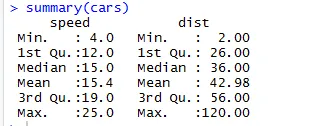
Her kan vi se den statistiske utgangen til hver variabel vi har i datasettet vårt.
Den grafiske representasjonen av datasett
Typer grafisk representasjon som vil dekke her er og hvorfor:
- Spredningsdiagram: Ved hjelp av grafen kan vi se i hvilken retning vår lineære regresjonsmodell går, om det er noen sterke bevis som kan bevise modellen vår eller ikke.
- Box Plot: Hjelper oss med å finne utlikere.
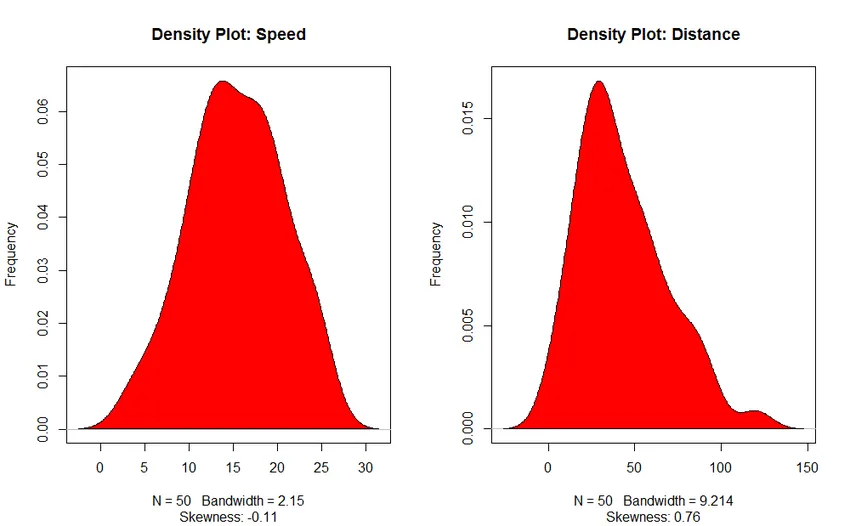
- Density Plot: Hjelp oss å forstå fordelingen av den uavhengige variabelen, i vårt tilfelle er den uavhengige variabelen “Speed”.
Fordeler med grafisk representasjon
Her er følgende fordeler:
- Enkelt å forstå
- Hjelper oss å ta en rask beslutning
- Sammenlignende analyse
- Mindre innsats og tid
1. Spredningsdiagram: Det vil bidra til å visualisere eventuelle forhold mellom den uavhengige variabelen og den avhengige variabelen.
Kode:

Produksjon:
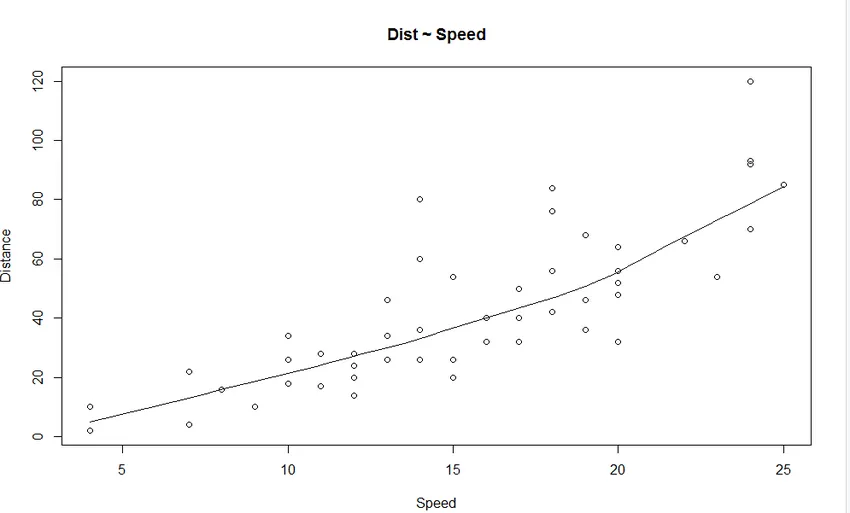
Vi ser fra grafen et lineært økende forhold mellom den avhengige variabelen (Distanse) og den uavhengige variabelen (Hastighet).
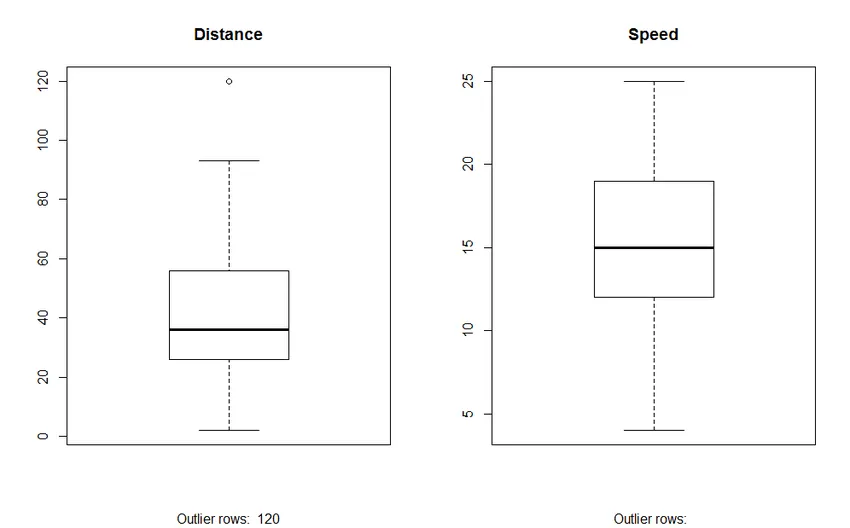
2. Box Plot: Box plot hjelper oss med å identifisere outliers i datasettene. Fordelene med å bruke en boksplott er:
- Grafisk visning av variabler plassering og spredning.
- Det hjelper oss å forstå datas skjevhet og symmetri.
Kode:

Produksjon:
3. Tetthetsplott (for å sjekke normaliteten i distribusjonen)
Kode:
 Produksjon:
Produksjon:
Korrelasjonsanalyse
Denne analysen hjelper oss å finne forholdet mellom variablene. Det er hovedsakelig seks typer korrelasjonsanalyse.
- Positiv korrelasjon (0, 01 til 0, 99)
- Negativ korrelasjon (-0, 99 til -0, 01)
- Ingen korrelasjon
- Perfekt korrelasjon
- Sterk korrelasjon (en verdi nærmere ± 0, 99)
- Svak korrelasjon (en verdi nærmere 0)
Scatter-plot hjelper oss med å identifisere hvilke typer korrelasjonsdatasett som er blant dem, og koden for å finne korrelasjonen er

Produksjon:
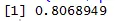
Her har vi en sterk positiv sammenheng mellom hastighet og avstand, noe som betyr at de har et direkte forhold mellom seg.
Lineær regresjonsmodell
Dette er kjernekomponenten i analysen, tidligere prøvde vi bare å teste ting om datasettet vi har er logisk nok til å kjøre en slik analyse eller ikke. Funksjonen vi planlegger å bruke er lm (). Denne funksjonen inneholder to elementer som er formel og data. Før vi tildeler hvilken variabel som er avhengig eller uavhengig, må vi være veldig sikre på det fordi hele formelen vår er avhengig av det.
Formelen ser slik ut,
Lineær regresjon <- lm (avhengig variabel ~ uavhengig variabel, data = dato. Ramme)
Kode:

Produksjon:
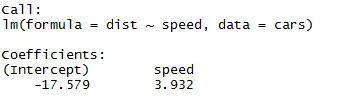
Som vi kan huske fra det ovennevnte segmentet av artikkelen, er likningen av lineær regresjon:
Y = β1 + β2X + ϵ
Nå vil vi passe inn informasjonen vi har fått fra koden ovenfor i denne ligningen.
dist = −17.579 + 3.932 ∗ hastighet
Bare det å finne ligningen av lineær regresjon er ikke tilstrekkelig, vi må også sjekke statistikken som er betydelig. For dette må vi gi en kode "Sammendrag" på vår lineære regresjonsmodell.
Kode:

Produksjon:

Det er flere måter å sjekke statistikken som er signifikant for en modell, her bruker vi P-verdi metoden. Vi kan vurdere en modell som er statistisk tilpasset når P-verdien er mindre enn det forhåndsbestemte statistiske signifikante nivået, som ideelt sett er 0, 05. Vi kan se i vår sammendragstabel (lineær_regresjon) at P-verdien er under 0, 05 nivå, slik at vi kan konkludere med at modellen vår er statistisk signifikant. Når vi er sikre på modellen vår, kan vi bruke datasettet vårt til å forutsi ting.
Anbefalte artikler
Dette er en guide til Lineær regresjonsanalyse. Her diskuterer vi de tre typene lineær regresjonsanalyse, den grafiske representasjonen av datasett med fordeler og lineære regresjonsmodeller. Du kan også gå gjennom andre relaterte artikler for å lære mer-
- Regresjonsformel
- Regresjonstesting
- Lineær regresjon i R
- Typer av dataanalyseteknikker
- Hva er regresjonsanalyse?
- Topp forskjeller av regresjon vs klassifisering
- Topp 6 forskjeller av lineær regresjon vs logistisk regresjon