
Introduksjon til datavitenskapens livssyklus
Data Science Livssyklus dreier seg om å bruke maskinlæring og andre analysemetoder for å produsere innsikt og spådommer fra data for å oppnå et forretningsmål. Hele prosessen innebærer flere trinn som rengjøring av data, klargjøring, modellering, modellevaluering, etc. Det er en lang prosess og kan ta flere måneder å fullføre. Så det er veldig viktig å ha en generell struktur for å følge for ethvert problem. Den globalt anerkjente strukturen for å løse ethvert analytisk problem kalles Cross Industry Standard Process for Data Mining eller CRISP-DM framework.
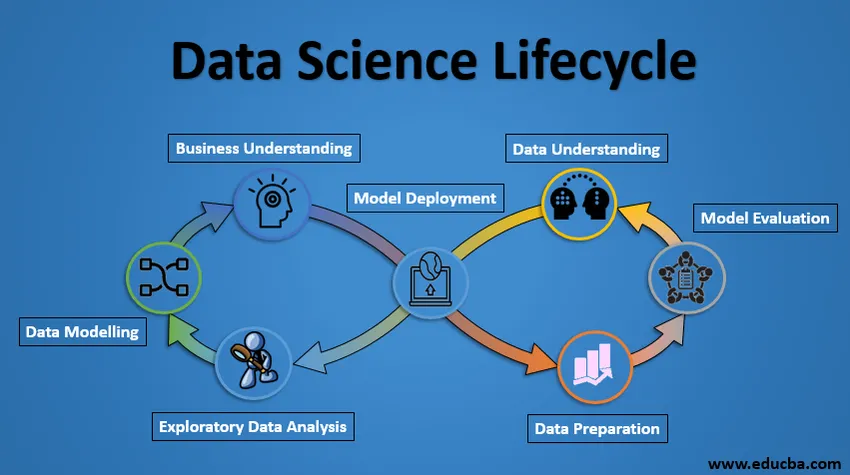
Livssyklus for datavitenskap
Nedenfor er prosjektets livssyklus for datavitenskap.
1. Forståelse av virksomheten
Hele syklusen dreier seg om virksomhetsmålet. Hva vil du løse hvis du ikke har et presist problem? Det er ekstremt viktig å forstå virksomhetsmålet tydelig, fordi det vil være det endelige målet med analysen. Bare etter god forståelse kan vi sette det spesifikke målet med analysen som er synkronisert med virksomhetsmålet. Du må vite om klienten ønsker å redusere kredittap, eller om de vil forutsi prisen på en vare, etc.
2. Forståelse av data
Etter forretningsforståelse er neste trinn dataforståelse. Dette innebærer innsamling av alle tilgjengelige data. Her må du jobbe tett med forretningsgruppen siden de faktisk er klar over hvilke data som er til stede, hvilke data som kan brukes til dette forretningsproblemet og annen informasjon. Dette trinnet innebærer å beskrive dataene, deres struktur, deres relevans, deres datatype. Utforsk dataene ved hjelp av grafiske plott. I utgangspunktet trekker du ut all informasjon du kan få om dataene ved bare å utforske dataene.
3. Forberedelse av data
Neste kommer dataforberedelsesstadiet. Dette inkluderer trinn som å velge relevant data, integrere dataene ved å slå sammen datasettene, rengjøre dem, behandle de manglende verdiene ved enten å fjerne dem eller pålegge dem, behandle feilaktige data ved å fjerne dem, også sjekke for outliers ved å bruke ruteoppgaver og håndtere dem . Konstruksjon av nye data, hent nye funksjoner fra eksisterende. Formater dataene i ønsket struktur, fjern uønskede kolonner og funksjoner. Dataforberedelse er det mest tidkrevende, men uten tvil det viktigste trinnet i hele livssyklusen. Modellen din vil være like god som dataene dine.
4. Utforskende dataanalyse
Dette trinnet innebærer å få noen ide om løsningen og faktorer som påvirker den, før du bygger selve modellen. Distribusjon av data innenfor forskjellige variabler av en funksjon utforskes grafisk ved bruk av søylediagrammer. Forhold mellom forskjellige funksjoner fanges opp gjennom grafiske fremstillinger som spredningsdiagrammer og varmekart. Mange andre datavisualiseringsteknikker brukes mye til å utforske hver funksjon individuelt, og ved å kombinere dem med andre funksjoner.
5. Datamodellering
Datamodellering er kjernen i dataanalysen. En modell tar de forberedte dataene som inndata og gir ønsket utdata. Dette trinnet inkluderer å velge riktig type modell, enten problemet er et klassifiseringsproblem, eller et regresjonsproblem eller et klyngeproblem. Etter å ha valgt modellfamilien, blant de forskjellige algoritmene blant den familien, må vi nøye velge algoritmene for å implementere og implementere dem. Vi må stille inn hyperparametrene til hver modell for å oppnå ønsket ytelse. Vi må også sørge for at det er en riktig balanse mellom ytelse og generaliserbarhet. Vi ønsker ikke at modellen skal lære dataene og prestere dårlig på nye data.
6. Evaluering av modellen
Her evalueres modellen for å sjekke om den er klar til å bli distribuert. Modellen er testet på usett data, evaluert på et nøye gjennomtenkt sett med evalueringsmålinger. Vi må også sørge for at modellen samsvarer med virkeligheten. Hvis vi ikke oppnår et tilfredsstillende resultat i evalueringen, må vi re-iterere hele modelleringsprosessen til ønsket nivå av beregninger er oppnådd. Enhver datavitenskapelig løsning, en maskinlæringsmodell, akkurat som et menneske, skal utvikle seg, skal kunne forbedre seg selv med nye data, tilpasse seg en ny evalueringsmetrik. Vi kan bygge flere modeller for et visst fenomen, men mange av dem kan være ufullkomne. Modellevaluering hjelper oss å velge og bygge en perfekt modell.
7. Model Deployment
Modellen etter en streng evaluering blir endelig distribuert i ønsket format og kanal. Dette er det siste trinnet i datavitenskapens livssyklus. Hvert trinn i datavitenskapens livssyklus som er beskrevet ovenfor, bør arbeides nøye. Hvis noen trinn utføres på feil måte, vil det følgelig påvirke neste trinn, og hele innsatsen går til spill. For eksempel, hvis data ikke blir samlet inn riktig, mister du informasjonen og du bygger ikke en perfekt modell. Hvis data ikke blir renset ordentlig, fungerer ikke modellen. Hvis modellen ikke blir evaluert riktig, vil den mislykkes i den virkelige verden. Helt fra forretningsforståelse til modellutplassering, bør hvert trinn bli gitt riktig oppmerksomhet, tid og krefter.
Anbefalte artikler
Dette er en guide til Data Science livssyklus. Her diskuterer vi en oversikt over Data Science Lifecycle og trinnene som utgjør en data science livssyklus. Du kan også gå gjennom relaterte artikler for å lære mer -
- Introduksjon til data science algoritmer
- Data Science vs Software Engineering | Topp 8 nyttige sammenligninger
- Forskjellstyper datavitenskapsteknikker
- Data Science ferdigheter med typer