
Definisjon av Mean Shift Algoritm
Mean Shift-algoritme faller inn under uovervåket læring som er kategorisert som Clustering-algoritmen. Ideologien til Mean Shift-algoritmen er at den iterativt tilordner datapunkter til klyngene ved å skifte mot punktet som har det høyeste tetthetspunktet (Mode). Gjennomsnittlig skift underliggende logikk er basert på begrepet estimering av kjernetetthet referert til som KDE.
Mean Shift Algorithm Clustering
En uovervåket læringsteknikk oppdaget av Fukunaga og Hostetler for å finne klynger:
- Mean Shift er også kjent som den modus-søkende algoritmen som tilordner datapunktene til klyngene på en måte ved å forskyve datapunktene mot regionen med høy tetthet. Den høyeste tettheten av datapunkter blir betegnet som modellen i regionen. Mean Shift-algoritmen har applikasjoner som er mye brukt innen datasyn og bildesegmentering.
- KDE er en metode for å estimere fordelingen av datapunktene. Det fungerer ved å plassere en kjerne på hvert datapunkt. Kjernen i matematisk sikt er en vektingsfunksjon som vil bruke vekter for individuelle datapunkter. Å legge til den enkelte kjernen genererer sannsynligheten.
Kernefunksjonen kreves for å tilfredsstille følgende betingelser:
- Det første kravet er å sikre at estimatet av kjernetetthet blir normalisert.
- Det andre kravet er at KDE er godt assosiert med romets symmetri.
To populære kjernefunksjoner
Nedenfor er de to populære kjernefunksjonene som brukes i den:
- Flat Kernel
- Gaussisk kjerne
- Basert på Kernel-parameteren som brukes, varierer den resulterende tetthetsfunksjonen. Hvis det ikke er nevnt noen kjerneparameter, blir Gaussian Kernel som standard påberopt. KDE benytter seg av begrepet sannsynlighetstetthetsfunksjon som hjelper til med å finne de lokale maksimaene for datadistribusjonen. Algoritmen fungerer ved å lage datapunktene for å tiltrekke hverandre og tillate datapunktene mot området med høy tetthet.
- Datapunktene som prøver å konvergere mot de lokale maksimaene vil være av samme gruppegruppe. I motsetning til K-Means-klyngealgoritmen, avhenger ikke utgangen fra Mean Shift-algoritmen av forutsetninger om datapunktets form og antall klynger. Antall klynger vil bli bestemt av algoritmen med hensyn til data.
- For å utføre implementeringen av Mean Shift-algoritmen, bruker vi python-pakken SKlearn.
Implementering av den gjennomsnittlige skiftalgoritmen
Nedenfor er implementeringen av algoritmen:
Eksempel 1
Basert på Sklearn Tutorial for Mean Shift Clustering Algorithm. Det første utdraget vil implementere en gjennomsnittlig skiftalgoritme for å finne klyngene i det 2-dimensjonale datasettet. Pakker som brukes til å implementere middelskiftalgoritmen.
Kode:
fromcluster importMeanShift, estimate_bandwidth
from sklearn.datasets.samples_generator import make_blobs as mb
importpyplot as plt
fromitertools import cycle as cy
En viktig ting å merke seg er at vi vil bruke sklearns make_blobs-bibliotek for å generere datapunkter sentrert på tre steder. For å bruke den gjennomsnittlige skiftalgoritmen på de genererte punktene, må vi stille inn båndbredden som representerer samspillet mellom lengden. Sklearns bibliotek har innebygde funksjoner for å estimere båndbredden.
Kode:
#Sample data points
cen = ((1, .75), (-.75, -1), (1, -1)) x_train, _ = mb(n_samples=10000, centers= cen, cluster_std=0.6)
# Bandwidth estimation using in-built function
est_bandwidth = estimate_bandwidth(x_train, quantile=.1,
n_samples=500)
mean_shift = MeanShift(bandwidth= est_bandwidth, bin_seeding=True)
fit(x_train)
ms_labels = mean_shift.labels_
c_centers = ms_labels.cluster_centers_
n_clusters_ = ms_labels.max()+1
# Plot result
figure(1)
clf()
colors = cy('bgrcmykbgrcmykbgrcmykbgrcmyk')
fori, each inzip(range(n_clusters_), colors):
my_members = labels == i
cluster_center = c_centers(k) plot(x_train(my_members, 0), x_train(my_members, 1), each + '.')
plot(cluster_center(0), cluster_center(1),
'o', markerfacecolor=each,
markeredgecolor='k', markersize=14)
title('Estimated cluster numbers: %d'% n_clusters_)
show()
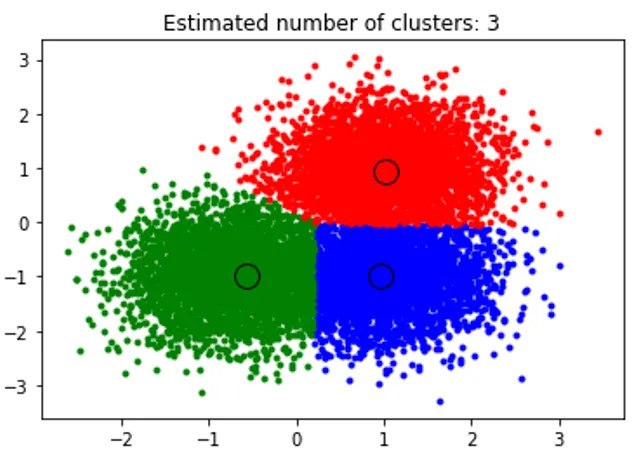
Utdraget ovenfor utfører klynging og algoritmen som er funnet klynger sentrert på hver klatt vi genererte. Vi kan se at fra bildet nedenfor plottet av kodebiten viser middelskiftalgoritmen som er i stand til å identifisere antall klynger som trengs i løpetid og finne ut den aktuelle båndbredden for å representere interaksjonslengden.
Produksjon:
Eksempel 2
Basert på bildesegmentering i datamaskinvisjon. Det andre utdraget vil utforske hvordan middelskiftalgoritmen som brukes i Deep Learning for å utføre segmentering av det fargede bildet. Vi benytter oss av den gjennomsnittlige skiftalgoritmen for å identifisere de romlige klyngene. Det tidligere utdraget brukte vi 2-D-datasett, mens vi i dette eksemplet vil utforske 3D-plass. Pixel av bildet blir behandlet som datapunkter (r, g, b). Vi må konvertere bildet til matriseformat slik at det hver piksel representerer datapunkt i bildet vi skal til segmentet. Clustering av fargeverdiene i mellomrom gir serier med klynger, der pikslene i klyngen vil være lik RGB-plass. Pakker som brukes til å implementere Mean Shift Algoritm:
Kode:
importnumpy as np
fromcluster importMeanShift, estimate_bandwidth
fromdatasets.samples_generator importmake_blobs
importpyplot as plt
fromitertools import cycle
fromPIL import Image
Under utdrag for å utføre segmentering av originalbildet:
#Segmentation of Color Image
img = Image.open('Sample.jpg.webp')
img = np.array(img)
#Need to convert image into feature array based
flatten_img=np.reshape(img, (-1, 3))
#bandwidth estimation
est_bandwidth = estimate_bandwidth(flatten_img,
quantile=.2, n_samples=500)
mean_shift = MeanShift(est_bandwidth, bin_seeding=True)
fit(flatten_img)
labels= mean_shift.labels_
# Plot image vs segmented image
figure(2)
subplot(1, 1, 1)
imshow(img)
axis('off')
subplot(1, 1, 2)
imshow(np.reshape(labels, (854, 1224)))
axis('off')
Det genererte bildet uttaler at denne tilnærmingen for å identifisere bildeformene og bestemme de romlige klyngene kan gjøres effektivt uten bildebehandling.
Produksjon:


Fordeler og applikasjoner betyr skiftalgoritme
Nedenfor er fordelene og anvendelsen av den gjennomsnittlige algoritmen:
- Det er mye brukt for å løse datamaskinsyn, der det brukes til bildesegmentering.
- Klynge av datapunkter i sanntid uten å nevne antall klynger.
- Presterer godt på bildesegmentering og videosporing.
- Mer robust mot utskyttere.
Fordeler med Mean Shift-algoritme
Nedenfor er proffs mean shift-algoritmen:
- Utgangen til algoritmen er uavhengig av initialiseringer.
- Prosedyren er effektiv da den bare har en parameter - Båndbredde.
- Ingen antagelser om antall dataklynger og form.
- Den har bedre ytelse enn K-Means Clustering.
Ulemper ved middelskiftalgoritme
Nedenfor er ulempene med den gjennomsnittlige skiftalgoritmen:
- Dyrt for store funksjoner.
- Sammenlignet med K-Means-klynger er det veldig treg.
- Algoritmeutgang avhenger av parameterbåndbredden.
- Output avhenger av størrelsen på vinduet.
Konklusjon
Selv om det er en grei tilnærming som først og fremst brukes til å løse problemer relatert til bildesegmentering, klynging. Det er relativt tregere enn K-Means, og det er beregningsdyktig.
Anbefalte artikler
Dette er en guide til Mean Shift-algoritmen. Her diskuterer vi problemer relatert til bildesegmentering, klynger, fordeler og to Kernel Function. Du kan også gå gjennom andre relaterte artikler for å lære mer-
- K- Betyr Clustering Algorithm
- KNN Algoritme i R
- Hva er genetisk algoritme?
- Kernemetoder
- Kernemetoder i maskinlæring
- Detalj forklaring av C ++ algoritme