
Introduksjon til Poisson Regression i R
Poisson-regresjon er en type regresjon som ligner multippel lineær regresjon bortsett fra at responsen eller den avhengige variabelen (Y) er en tellevariabel. Den avhengige variabelen følger Poisson-fordelingen. Prediktoren eller uavhengige variabler kan være kontinuerlige eller kategoriske. På en måte ligner det på Logistic Regression som også har en diskret responsvariabel. Forutgående forståelse av Poisson-distribusjonen og dens matematiske form er veldig viktig for å utnytte den til prediksjon. I R kan Poisson-regresjon implementeres på en veldig effektiv måte. R tilbyr et omfattende sett med funksjoner for implementering.
Implementering av Poisson Regression
Vi vil nå fortsette å forstå hvordan modellen brukes. Følgende avsnitt gir en trinnvis prosedyre for det samme. For denne demonstrasjonen vurderer vi "galla" datasettet fra den "fjerne" pakken. Det gjelder artsmangfoldet på Galapagosøyene. Det er til sammen 7 variabler i datasettet. Vi bruker Poisson-regresjon for å definere et forhold mellom antall plantearter (arter) med andre variabler i datasettet.
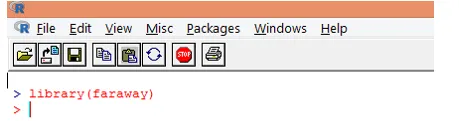
1. Last først den "fjerne" pakken. I tilfelle pakken ikke er til stede, kan du laste den ned ved hjelp av funksjonen install.packages ().
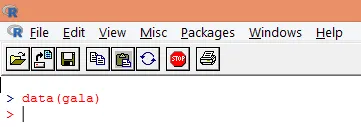
2. Når pakken er lastet inn, laster du "gala" datasettet i R ved å bruke data () -funksjonen som vist nedenfor.
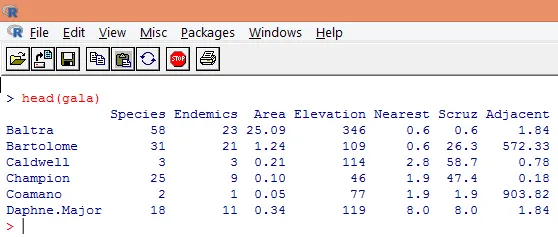
3. De lastede dataene skal visualiseres for å studere variabelen og kontrollere om det er noen avvik. Vi kan visualisere enten alle dataene, eller bare de første radene av dem ved hjelp av funksjonen hode () som vist på skjermbildet nedenfor.
4. For å få mer innsikt i datasettet, kan vi bruke hjelpefunksjonalitet i R som nedenfor. Det genererer R-dokumentasjonen som vist på skjermdumpen etter skjermbildet nedenfor.


5. Hvis vi studerer datasettet som nevnt i de foregående trinnene, kan vi finne at arter er en responsvariabel. Vi skal nå studere et grunnleggende sammendrag av prediktorvariablene.
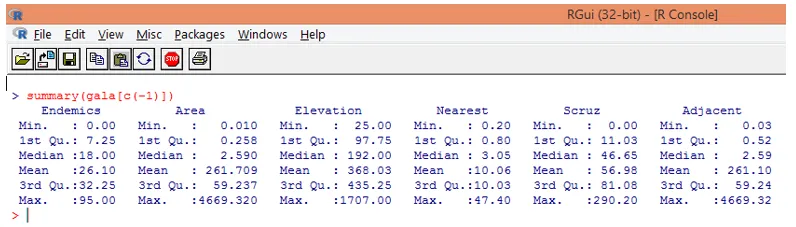
Som vi kan se ovenfor, har vi ekskludert variabelen Arter. Sammendragsfunksjonen gir oss grunnleggende innsikt. Bare observer medianverdiene for hver av disse variablene, og vi kan oppdage at det er en stor forskjell, når det gjelder verdiområdet, mellom første halvdel og andre halvdel, for f.eks. Variabel medianverdi for areal er 2, 59, men den maksimale verdien er 4669.320.
6. Nå som vi er ferdig med grunnleggende analyse, genererer vi et histogram for arter for å sjekke om variabelen følger Poisson-fordelingen. Dette er illustrert nedenfor.

Den ovennevnte koden genererer et histogram for variabelen av arter sammen med en tetthetskurve som er lagt over den.
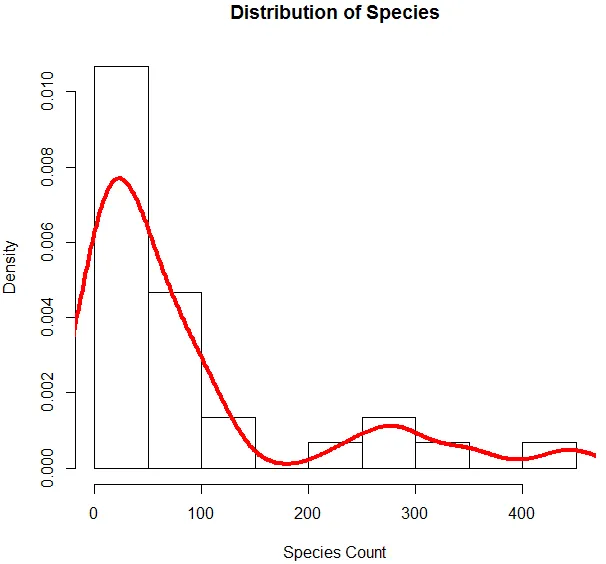
Visualiseringen ovenfor viser at arter følger en Poisson-distribusjon, da dataene er rett skjevt. Vi kan generere en boksplott også for å få mer innsikt i distribusjonsmønsteret som vist nedenfor.
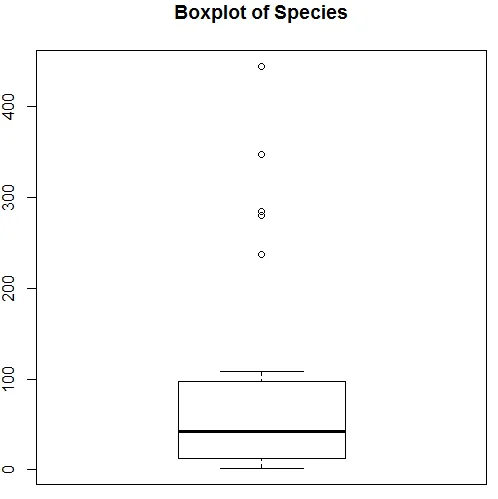
7. Etter å ha gjort med den foreløpige analysen, vil vi nå anvende Poisson-regresjon som vist nedenfor
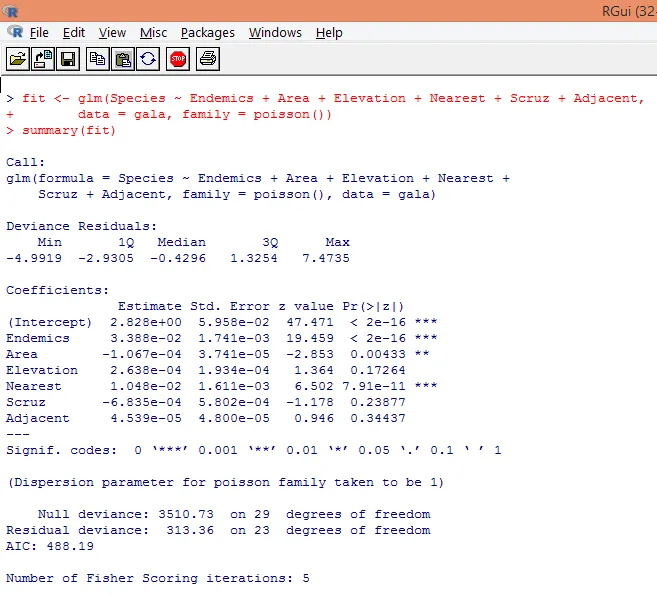
Basert på analysen ovenfor, finner vi at variabler Endemikk, område og nærmeste er betydningsfulle og bare inkludering av dem er tilstrekkelig til å bygge den rette Poisson-regresjonsmodellen.
8. Vi bygger en modifisert Poisson-regresjonsmodell som bare tar i betraktning tre variabler, dvs. Endemikk, område og nærmeste. La oss se hvilke resultater vi får.
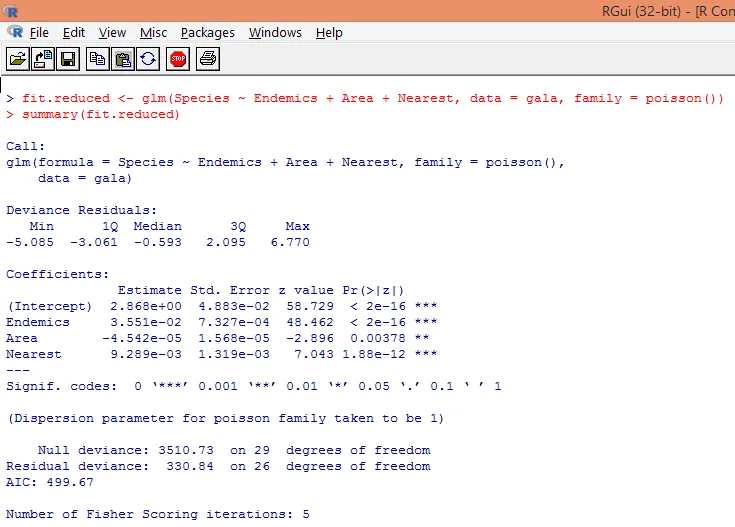
Utgangen produserer avvik, regresjonsparametere og standardfeil. Vi kan se at hver av parameterne er signifikante på p <0, 05 nivå.
9. Neste trinn er å tolke modellparametrene. Modellkoeffisientene kan oppnås enten ved å undersøke koeffisienter i utdata ovenfor eller ved å bruke coef () -funksjon.
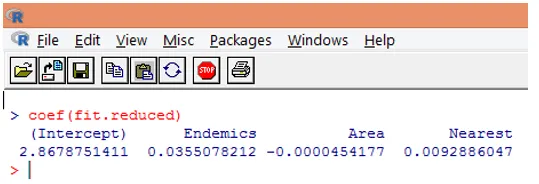
I Poisson-regresjon er den avhengige variabelen modellert som loggen for den betingede middelloggen (l). Regresjonsparameteren på 0, 0355 for Endemics indikerer at en enhetsøkning i variabelen er assosiert med en 0, 04 økning i loggmidlet antall arter, og holder andre variabler konstant. Avskjæringen er et gjennomsnittlig antall logg når hver av prediktorene er lik null.
10. Imidlertid er det mye lettere å tolke regresjonskoeffisientene i den opprinnelige skalaen til den avhengige variabelen (antall arter, i stedet for loggnummeret av arter). Eksponentiseringen av koeffisientene vil tillate en enkel tolkning. Dette gjøres som følger.
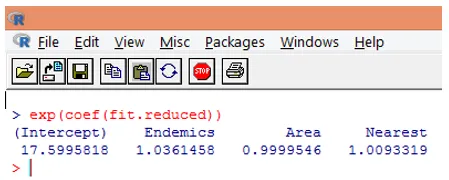
Fra funnene ovenfor kan vi si at en enhetsøkning i Areal multipliserer det forventede antallet arter med 0, 9999, og en enhetsøkning i antall endemiske arter representert av Endemics multipliserer antall arter med 1.0361. Det viktigste aspektet ved Poisson-regresjon er at eksponentielle parametere har en multiplikativ snarere enn en additiv effekt på responsvariabelen.
11. Ved å bruke trinnene ovenfor oppnådde vi en Poisson-regresjonsmodell for å forutsi antall plantearter på Galapagosøyene. Det er imidlertid veldig viktig å sjekke for overdispersjon. I Poisson-regresjon er variansen og midlene like.
Overdispersjon oppstår når den observerte variasjonen av responsvariabelen er større enn det som forutsettes av Poisson-fordelingen. Analyse av overdispersjon blir viktig ettersom det er vanlig med telledata, og kan påvirke de endelige resultatene negativt. I R kan overdispersjon analyseres ved bruk av “qcc” pakken. Analysen er illustrert nedenfor.
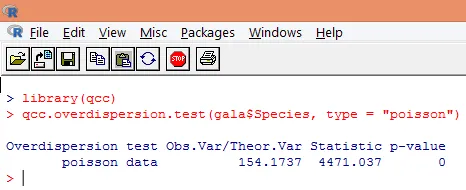
Ovennevnte signifikante test viser at p-verdien er mindre enn 0, 05, noe som sterkt antyder tilstedeværelsen av overdispersjon. Vi prøver å montere en modell ved å bruke glm () -funksjonen, ved å erstatte family = “Poisson” med family = “quasipoisson”. Dette er illustrert nedenfor.
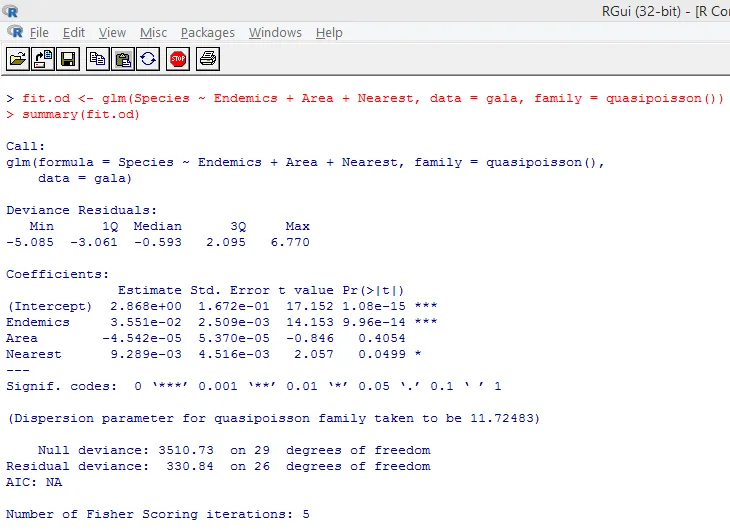
Nært å studere utdata ovenfor, kan vi se at parameterestimatene i kvasi-Poisson-tilnærmingen er identiske med de som er produsert av Poisson-tilnærmingen, selv om standardfeilene er forskjellige for begge tilnærmingene. I dette tilfellet, for Area, er p-verdien større enn 0, 05 som skyldes større standardfeil.
Betydningen av Poisson-regresjon
- Poisson Regresjon i R er nyttig for korrekte prediksjoner av den diskrete / telle variabelen.
- Det hjelper oss å identifisere de forklaringsvariablene som har en statistisk signifikant effekt på responsvariabelen.
- Poisson Regresjon i R er best egnet for hendelser av "sjelden" natur, da de har en tendens til å følge en Poisson-distribusjon mot vanlige hendelser som vanligvis følger en normal fordeling.
- Den er egnet for anvendelse i tilfeller der responsvariabelen er et lite heltall.
- Den har brede bruksområder, ettersom en prediksjon av diskrete variabler er avgjørende i mange situasjoner. I medisin kan det brukes til å forutsi virkningen av stoffet på helsen. Det er sterkt brukt i overlevelsesanalyse som død av biologiske organismer, svikt i mekaniske systemer, etc.
Konklusjon
Poisson-regresjon er basert på konseptet Poisson-distribusjon. Det er en annen kategori som tilhører settet med regresjonsteknikker som kombinerer egenskapene til både lineære og logistiske regresjoner. I motsetning til logistisk regresjon som bare genererer binær utgang, brukes den til å forutsi en diskret variabel.
Anbefalte artikler
Dette er en guide til Poisson Regression i R. Her diskuterer vi introduksjonen Implementing Poisson Regression and Importance of Poisson Regression. Du kan også gå gjennom de andre foreslåtte artiklene våre for å lære mer–
- GLM i R
- Tilfeldig nummergenerator i R
- Regresjonsformel
- Logistisk regresjon i R
- Linear Regression vs Logistic Regression | Topp forskjeller