

Karriere i Hadoop - Introduksjon
Hadoop er ikke bare et rammeverk i Big Data-verdenen. Det har et bredt økosystem med en paraply av relaterte teknologier. Av samme grunn er en karriere i Hadoop lovende. Hvis du har god forståelse av Hadoop-grunnleggende, vil det være et grunnlag for god karriere i Hadoop.
Utdanning til karriere i Hadoop
Som mange nye datateknologier, krever ikke Hadoop noen spesifikk utdannelsesbakgrunn som sådan. Rundt halvparten av Hadoop-utviklere er fra ikke-datavitenskapelig bakgrunn som statistikk eller fysikk. Så det er tydelig at bakgrunnen ikke er til hinder for å komme inn i Hadoops verden, forutsatt at du er klar til å lære grunnleggende. Det er gode online kurs dekker Hadoop - den fra eduCBA er det beste eksemplet - master-apache-Hadoop
Videre, hvis du vil gå dypere inn i et spesifikt område av Hadoop klyngestyring eller datamodellering i Hive-materialer om hvert spesifikt emne som er tilgjengelig som online kurs og lærebøker. Det meste av tiden Hadoop-klynger vil bli satt opp i en skyleverandør som AWS eller Azure. Så å bli kjent med hvilken som helst skyleverandør du velger, vil hjelpe mye. Hadoop-tjeneste fra AWS heter EMR.
Populær spesialisering inkluderer:
- Spark - skalerbar databehandlingsmotor i minnet
- HBase - Ingen SQL-database på toppen av HDFS
- Beam - Streaming databehandling av første tilnærming
- Pig - Data transformation (ETL) scripting
- Hive - Datavarehus
- Mahout, Spark MLlib - skalerbar maskinlæring på Hadoop
- Apache Drill - SQL-motor på Hadoop
- Flume, Sqoop - Data Ingesting Services
- Solr & Lucene - Søke og indeksere
Karrierevei i Hadoop
I henhold til resultatene fra Stack Overflow Survey 2017 er Hadoop ledende innen det mest populære og mest elskede rammeverket i Big Data-rom (Survey Link). Dette er bare mulig fordi folk fra forskjellige IT-perspektiv fant Hadoop som en potensiell karrierevei og ønsker å bytte.
Uansett hva din nåværende rolle er som IT-rolle, vil det være en lett tilpasningsbar bytte til en karriere i Hadoop-verdenen. Noen populære eksempler -
- Programvareutvikler (programmerer) -> Hadoop Data Developer som arbeider med forskjellige Hadoop-abstraksjons-SDK-er og henter verdi fra data.
- Data Analyst -> Så du er dyktig i SQL. Stor mulighet i Hadoop til å jobbe på SQL-motorer som Hive eller Impala
- Business Analyst -> Organisasjoner som prøver å bli mer lønnsomme ved å bruke massivt innsamlede data, og rolle for en forretningsanalytiker er avgjørende i dette.
- ETL Developer -> Hvis du jobber som en tradisjonell ETL-utvikler, kan du enkelt skifte til Hadoop ETL ved å bruke verktøy som Spark.
- Testere -> Det er stor etterspørsel etter testere i Hadoop-verdenen. Ved å forstå det grunnleggende ved Hadoop og dataprofilering, kan alle testere bytte til denne rollen.
- BI / DW-yrker -> Kan enkelt bytte til Hadoop Data-arkivering til Datamodellering.
- Senior IT-fagfolk -> Med en dyp forståelse av domenet og eksisterende utfordringer i dataverdenen, kan en senior profesjonell bli konsulenter ved å få kunnskap om hvordan Hadoop prøver å løse disse utfordringene.
- Det er generiske roller som Data Engineers eller Big Data Engineering som er ansvarlig for å implementere løsningen for det meste på toppen av Cloud-leverandører. Ved å få kunnskap om datakomponenter i skyen gir, vil dette være en lovende rolle.
Jobbstillinger
Hadoop økosystem tilbyr en rekke karriereveier
- MapReduce Developer - Dette er i utgangspunktet en Java-utviklerrolle som også forstår hvordan Hadoop-systemer fungerer internt. Det er en abstraksjon som Hive eller Pig tilgjengelig, fremdeles er MapReduce-jobber nødvendige for systemer med høy ytelse. MapReduce-utviklere er den som forstår et system inn og ut og betalte veldig høyt.
- Hadoop-administratorer - Dette er personer som er ansvarlige for å holde Hadoop-klyngen sunn og prestere. Dette kan omfatte typiske administratoroppgaver som vanlige systemhelsekontroller, men et flertall av oppgavene som trengs for å forstå Hadoop-systemarkitektur.
- Devops - Distribuer nye systemkomponenter og andre utviklingsrelaterte endringer i Hadoop-klyngen. Ansvaret for denne rollen varierer mye og avhenger av kulturen i en organisasjon.
- Data Developer - Databehandling på toppen av Hadoop. Dette er en av de mest populære rollene i Hadoop-økosystemet. Personer med SQL eller analytisk bakgrunn passer best for disse rollene. Arbeid hovedsakelig med en abstraksjon på høyt nivå av Hadoop som Hive eller Pig.
- Datasikkerhetsadministrator - Data er de mest verdifulle eiendelene og sikring av dem er viktigst. Sikkerhetsadministratorer sikrer bransjestandard retningslinjer og beste praksis for å beskytte data, med forståelsesfull begrensning av et system
- Datavisualisator - Håndter neste generasjons visualiseringsverktøy som tillater dynamisk dataskivering og aggregering med datatbuffring i minnet
- ETL Developer - Transformer data for forbedring av datakvalitet eller i henhold til forretningslogikk ved bruk av Hadoop økosystemverktøy. ETL-prosessen kan være streaming eller batch.
- Systemarkitekt - Design systemer med høy ytelse med tanke på datatilgjengelighet og holdbarhet på en kostnadseffektiv måte. Avhenger sterkt av maskinvareleverandør.
- Data Architect - Bortsett fra tradisjonell logisk / fysisk utforming av data, vil mange ting som kolonnekoding, denormalisering, partisjoneringsdesign osv. Være et dataarkitts ansvar.
Anbefalte kurs
- Online XML og Java Training
- Node.JS-kurs
- Silverlight treningskurs
- Ember.JS-programmet
Lønn
En gjennomsnittslønn for en programvareutvikler i USA er $ 90, 956 per år, mens gjennomsnittslønnen til Hadoop-utvikleren er en måte høyere - $ 118, 234 per år (Per per faktisk.com - faktisk.com)
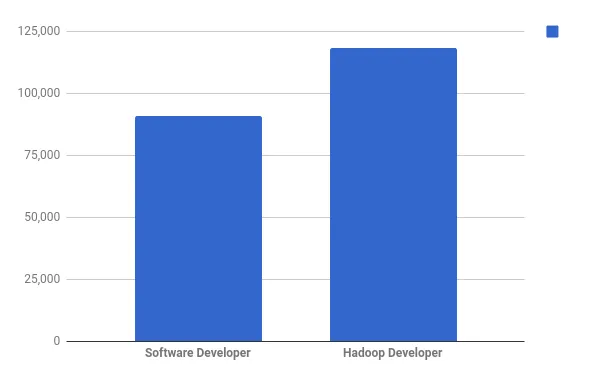
Lønn til Hadoop-utvikler i toppbedrifter i USA (Ref: faktisk.com)
| eple | 147.573 dollar per år |
| Wipro | 110.553 dollar per år |
| HERO.jobs | 158 715 dollar per år |
| MBCAA | 133.422 dollar per år |
| Ventures Unlimited Inc | 130 000 dollar per år |
| Nityo Infotech Services Pvt. Ltd. | 128.633 dollar per år |
| NORDSTJERNEN | 126 370 dollar per år |
| PRI-teknologi | 121.396 dollar per år |
| NITYO INFOTECH | $ 116 909 per år |
| HortonWorks, Inc | 110 710 dollar per år |
Karriereutsikt
Hadoop-økosystemet blir veldig avvikende for å møte en endring i forretningsbehov. Ettersom data generert øker eksponentielt og flere og flere organisasjoner blir datadrevne, vil relevansen av Hadoop-systemet bare øke.
Noen av de bemerkelsesverdige trendene:
- Skift fra batchbehandling til å streame den første databehandlingsmetoden ved å bruke Spark and Beam
- Mer sanntids Machine Learning-modell brukt til sanntidsdata ved å bruke Spark ML
- Frakoblet SQL-motorer fra datalagring som Presto på toppen av S3 for ad-hoc-analyse på toppen av datasjøen.
- Columnar MPP-databaser som AWS Redshift for rask datatilgang
Som et grunnleggende aspekt av Big Data-behandling ligger på feiltolerante distribuerte og horisontalt skalerbare systemer, som er godt implementert av Hadoop, vil Hadoop fortsette som et ledende økosystem for databehandling.
Anbefalt artikkel
Dette har vært en guide til Karriere i Hadoop. Her har vi diskutert Introduksjon, utdanning, karrierevei i Hadoop, lønn og karriereutsikter i Hadoop. kan du også se på følgende artikkel for å lære mer -
- Azure Paas vs Iaas og deres nyttige fordeler
- Finn ut forskjellene mellom Java vs Node JS
- Beste ekspertråd på karrierer i Mainframe
- Karrierer i SQL
- Nyttige karrierer som programvareingeniør
- Hadoop Administrator | Ferdigheter og karrierevei