
Oversikt over nevrale nettverksalgoritmer
- La oss først vite hva betyr et nevralt nettverk? Nevrale nettverk er inspirert av de biologiske nevrale nettverkene i hjernen, eller vi kan si nervesystemet. Det har skapt mye spenning, og det foregår fortsatt forskning på denne undergruppen Machine Learning i industrien.
- Den grunnleggende beregningsenheten i et nevralt nettverk er en nevron eller node. Den mottar verdier fra andre nevroner og beregner utdataene. Hver node / nevron er assosiert med vekt (w). Denne vekten er gitt i henhold til den relative viktigheten av den aktuelle nevronen eller noden.
- Så hvis vi tar f som nodefunksjon, vil nodefunksjonen f gi utdata som vist nedenfor: -
Utgang av nevron (Y) = f (w1.X1 + w2.X2 + b)
- Hvor w1 og w2 er vekt, er X1 og X2 numeriske innganger mens b er skjevheten.
- Ovennevnte funksjon f er en ikke-lineær funksjon også kalt aktiveringsfunksjon. Dets grunnleggende formål er å introdusere ikke-linearitet da nesten alle data fra den virkelige verden er ikke-lineære, og vi vil at nevroner skal lære disse representasjonene.
Ulike nevrale nettverksalgoritmer
La oss nå se på fire forskjellige nevrale nettverksalgoritmer.
1. Gradient Descent
Det er en av de mest populære optimaliseringsalgoritmene innen maskinlæring. Den brukes mens du trener en maskinlæringsmodell. Med enkle ord: Det brukes i utgangspunktet for å finne verdier på koeffisientene som ganske enkelt reduserer kostnadsfunksjonen så mye som mulig. Først av alt starter vi med å definere noen parameterverdier og deretter ved å bruke kalkulus begynner vi å iterativt justere verdiene slik at den tapte funksjonen reduseres.
La oss nå komme til den delen som er gradient ?. Så en gradient betyr i stor grad utskriften til en hvilken som helst funksjon vil endre seg hvis vi reduserer inngangen med lite eller med andre ord kan vi kalle den til skråningen. Hvis skråningen er bratt, vil modellen lære raskere på samme måte som en modell slutter å lære når skråningen er null. Dette er fordi det er en minimeringsalgoritme som minimerer en gitt algoritme.
Under formelen for å finne den neste posisjonen vises i tilfelle av gradient nedstigning.
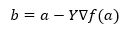
Hvor b er neste posisjon
a er nåværende posisjon, gamma er en ventende funksjon.
Så som du kan se gradient nedstigning er en veldig lydteknikk, men det er mange områder der gradient nedstigning ikke fungerer som den skal. Nedenfor er noen av dem gitt:
- Hvis algoritmen ikke blir utført ordentlig, kan vi støte på noe som problemet med å forsvinne gradient. Disse oppstår når gradienten er for liten eller for stor.
- Problemer kommer når dataopplegg utgjør et ikke-konveks optimaliseringsproblem. Gradient anstendig fungerer bare med problemer som er det konvekse optimaliserte problemet.
- En av de veldig viktige faktorene å se etter når du bruker denne algoritmen er ressurser. Hvis vi har mindre minne tildelt applikasjonen, bør vi unngå gradient nedstigningsalgoritme.
2. Newtons metode
Det er en andreordens optimaliseringsalgoritme. Det kalles en andre orden fordi den benytter seg av den hessiske matrisen. Så, den hessiske matrisen er ikke annet enn en kvadratmatrise av andreordens delvise derivater av en skalærvaluert funksjon. I Newtons metodeoptimaliseringsalgoritme brukes den til den første derivatet av en dobbel differensierbar funksjon f slik at den kan finne røttene / stasjonære punkter. La oss nå gå inn på trinnene som kreves av Newtons metode for optimalisering.
Den evaluerer først tapsindeksen. Den sjekker deretter om stoppkriteriene er sanne eller usanne. Hvis den er falsk, beregner den deretter Newtons treningsretning og treningsfrekvens og forbedrer deretter parameterne eller vekten til nevronet og igjen fortsetter den samme syklusen. Så du kan nå si at det tar færre trinn i forhold til gradient nedstigning for å få minimum verdien av funksjonen. Selv om det tar færre trinn i forhold til gradient nedstigningsalgoritmen, brukes den likevel ikke mye, da den eksakte beregningen av hessian og dens inverse er beregningsdyktig veldig kostbar.
3. Konjugert gradient
Det er en metode som kan betraktes som noe mellom gradient nedstigning og Newtons metode. Hovedforskjellen er at den akselererer den langsomme konvergensen som vi vanligvis forbinder med gradientnedstigning. Et annet viktig faktum er at det kan brukes til både lineære og ikke-lineære systemer, og det er en iterativ algoritme.
Den ble utviklet av Magnus Hestenes og Eduard Stiefel. Som allerede nevnt ovenfor at den produserer raskere konvergens enn gradient nedstigning. Årsaken til at den er i stand til å gjøre det, er at i konjugert gradientalgoritme er søket gjort sammen med konjugerte retninger, på grunn av hvilken det konvergerer raskere enn gradient nedstigningsalgoritmer. Et viktig poeng å merke seg er at γ kalles konjugatparameteren.
Treningsretningen tilbakestilles med jevne mellomrom til det negative av gradienten. Denne metoden er mer effektiv enn gradientnedstigning når det gjelder å trene det nevrale nettverket, da det ikke krever den hessiske matrisen som øker beregningsbelastningen, og den konvergerer også raskere enn gradientnedstigningen. Det er hensiktsmessig å bruke i store nevrale nettverk.
4. Quasi-Newton-metoden
Det er en alternativ tilnærming til Newtons metode, ettersom vi er klar over at Newtons metode er beregningsdyktig. Denne metoden løser ulempene i en grad slik at i stedet for å beregne den hessiske matrisen og deretter beregne den inverse direkte, bygger denne metoden opp en tilnærming til å inverse Hessian ved hver iterasjon av denne algoritmen.
Nå beregnes denne tilnærmingen ved å bruke informasjonen fra det første derivatet av tapsfunksjonen. Så vi kan si at det sannsynligvis er den best egnede metoden å håndtere store nettverk da det sparer beregningstid og også at det er mye raskere enn gradient nedstigning eller konjugert gradientmetode.
Konklusjon
Før vi avslutter denne artikkelen, la oss sammenligne beregningshastighet og minne for de ovennevnte algoritmer. I henhold til minnekrav krever gradient nedstigning minst minne, og det er også den tregeste. I motsetning til at Newtons metode krever mer regnekraft. Så med tanke på alle disse, er Quasi-Newton-metoden den best egnede.
Anbefalte artikler
Dette har vært en guide til nevrale nettverksalgoritmer. Her diskuterer vi også oversikten over nevrale nettverksalgoritmer sammen med henholdsvis fire forskjellige algoritmer. Du kan også gå gjennom andre foreslåtte artikler for å lære mer -
- Machine Learning vs Neural Network
- Maskiner for læring av maskiner
- Neural Networks vs Deep Learning
- K- Betyr Clustering Algorithm
- Guide to Classification of Neural Network