

Introduksjon til Hadoop Architecture
Hadoop Architecture er et open source-rammeverk som hjelper deg med å behandle store datasett enkelt. Det hjelper med å lage applikasjoner som behandler enorme data med større hastighet. Den benytter seg av de distribuerte datakonseptene der data spres over forskjellige noder i en klynge. Applikasjonene som er bygget ved hjelp av Hadoop benytter seg av varedatamaskiner. Disse datamaskinene er lett tilgjengelige i markedet til lave priser. Dette resultatet oppnår større regnekraft til en lav pris. Alle dataene som finnes i Hadoop ligger på HDFS i stedet for et lokalt filsystem. HDFS er et Hadoop Distribuert filsystem. Denne modellen er basert på datalokalitet der beregningslogikken sendes til nodene som er til stede i en klynge som inneholder dataene. Denne logikken er ikke annet enn en logikk som kompilerer programmet.
Hadoop Arkitektur
Den grunnleggende ideen med denne arkitekturen er at hele lagring og prosessering skjer på to trinn og på to måter. Det første trinnet er prosessering som gjøres av Map redusere programmering, og den andreveis trinnet er å lagre dataene som gjøres på HDFS. Den har en master-slave-arkitektur for lagring og databehandling. Hovednoden for datalagring i Hadoop er navnet node. Det er også en hovednode som gjør arbeidet med å overvåke og parallelle databehandlingen ved å bruke Hadoop Map Reduce. Slavene er andre maskiner i Hadoop-klyngen som hjelper til med å lagre data og også utføre komplekse beregninger. Hver slaveknute har blitt tildelt en oppgavespor og en datanode har en jobbsøker som hjelper i å kjøre prosessene og synkronisere dem effektivt. Denne typen systemer kan settes opp enten på sky eller på stedet. Navneknuten er et enkelt feil punkt når den ikke kjører i modus med høy tilgjengelighet. Hadoop-arkitekturen har også bestemmelser for å opprettholde en stand by Name-node for å beskytte systemet mot feil. Tidligere var det sekundære navneknuter som fungerte som en sikkerhetskopi når den primære navneknuten var nede.
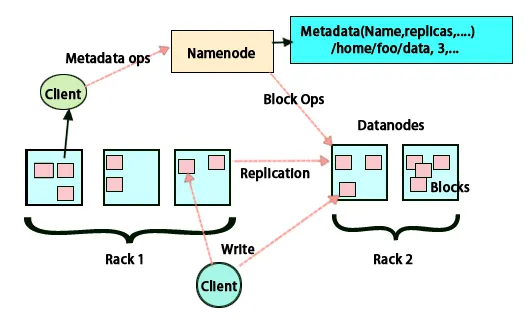
FSimage og redigere logg
FSimage og redigeringslogg sikrer vedvarenhet av filsystemmetadata for å følge med all informasjon og navneknute lagrer metadataene i to filer. Disse filene er FSimage og redigeringsloggen. Jobben til FSimage er å holde et komplett øyeblikksbilde av filsystemet på et gitt tidspunkt. Endringene som stadig gjøres i et system, må føres oversikt over. Disse trinnvise endringene som å gi nytt navn eller legge til detaljer til filen lagres i redigeringsloggen. Rammeverket gir et bedre alternativ i stedet for å opprette en ny FSimage hver gang, et bedre alternativ å kunne lagre dataene mens en ny fil for FSimage. FSimage lager et nytt øyeblikksbilde hver gang endringer gjøres Hvis Navneknuten mislykkes, kan den gjenopprette sin forrige tilstand. Den sekundære navnnoden kan også oppdatere kopien hver gang det er endringer i FSimage og redigere logger. Dermed sikrer det at selv om navnet noden er nede, i nærvær av sekundær navn node vil det ikke være noe tap av data. Navneknute krever ikke at disse bildene må lastes inn på sekundærnodenoden.
Datareplikering
HDFS er designet for å behandle data raskt og gi pålitelige data. Den lagrer data på tvers av maskiner og i store klynger. Alle filer lagres i en serie blokker. Disse blokkene er kopiert for feiltoleranse. Blokkstørrelsen og replikasjonsfaktoren kan avgjøres av brukerne og konfigureres i henhold til brukerens krav. Som standard er replikasjonsfaktoren 3. Replikeringsfaktoren kan spesifiseres på tidspunktet for filopprettelsen, og den kan endres senere. Alle avgjørelser angående disse kopiene blir tatt med navnet noden. Navneknuten fortsetter å sende hjerteslag og blokkere rapport med jevne mellomrom for alle dataknuter i klyngen. Mottakelsen av hjerteslag innebærer at dataknuten fungerer som den skal. Blokkeringsrapport spesifiserer listen over alle blokker som er til stede på datanoden.
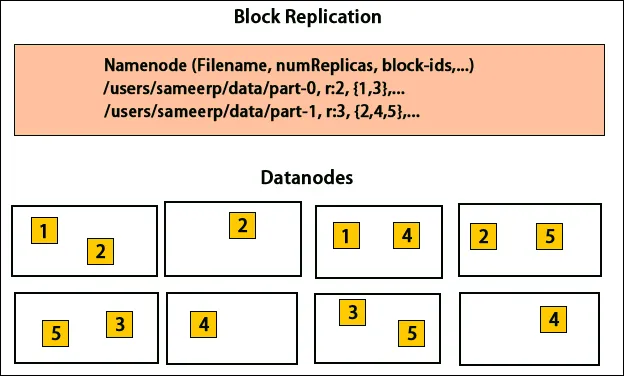
Plassering av kopier
Plassering av kopier er en veldig viktig oppgave i Hadoop for pålitelighet og ytelse. Alle de forskjellige datablokkene er plassert på forskjellige stativer. Implementeringen av replikkplassering kan gjøres i henhold til pålitelighet, tilgjengelighet og nettverksbåndbreddebruk. Klyngen av datamaskiner kan spres over forskjellige stativer. Ikke mer enn to noder kan plasseres på samme stativ. Den tredje kopien bør plasseres på et annet rack for å sikre mer pålitelighet av data. De to nodene på stativet kommuniserer gjennom forskjellige brytere. Navneknuten har rack-ID for hver datanode. Men å plassere alle noder på forskjellige stativer forhindrer tap av data og tillater bruk av båndbredde fra flere stativer. Det kutter også inter-rack-trafikken og forbedrer ytelsen. Dessuten er sjansen for rackfeil veldig mindre sammenlignet med nodesvikt. Det reduserer den samlede nettverksbåndbredden når data leses fra to unike stativer i stedet for tre.
Kart reduksjon
Map Reduce brukes til behandling av data som er lagret på HDFS. Den skriver distribuerte data på tvers av distribuerte applikasjoner som sikrer effektiv behandling av store datamengder. De behandler på store klynger og krever vare som er pålitelig og feiltolerant. Kjernen i Map-redusere kan være tre operasjoner som kartlegging, samling av par og blanding av resulterende data.
Konklusjon - Hadoop Architecture
Hadoop er et open source-rammeverk som hjelper i et feiltolerant system. Den kan lagre store datamengder og hjelper til med å lagre pålitelige data. De to delene med å lagre data i HDFS og behandle dem gjennom kart-redusere hjelp til å fungere ordentlig og effektivt. Den har en arkitektur som hjelper deg med å administrere alle datablokkene og også ha den nyeste kopien ved å lagre den i FSimage og redigere logger. Replikeringsfaktoren hjelper også med å ha kopier av data og få dem tilbake når det er en feil. HDFS flytter også fjernede filer til søppelkatalogen for optimal bruk av plass.
Anbefalte artikler
Dette har vært en guide til Hadoop Architecture. Her har vi diskutert Arkitektur, Kart redusere, Plassering av replikker, Datareplikering. Du kan også gå gjennom andre foreslåtte artikler for å lære mer -
- Bli Hadoop-utvikler
- Introduksjon til Android
- Hva er Tableau? | Et overblikk
- Hva er MapReduce i Hadoop?