
Introduksjon til Hive Architecture
Hive Architecture er bygget på toppen av Hadoop-økosystemet. Hive har ofte interaksjoner med Hadoop. Apache Hive klarer både SQL-databasesystemet og Map-redusere. Hive-applikasjoner kan skrives på forskjellige språk som Java, python. Hive-arkitektur viser hvordan man skriver hive Query-språk og hvordan samhandlingene mellom programmereren gjøres ved hjelp av kommandolinjegrensesnittet. Hive-spørrespråk gjør jobben med å konvertere alle Hadoop-klyngeoppgavene gjennom kart-redusere. Som vi alle kjente Hadoop til å behandle big data i et distribuert miljø og danner en åpen kildekode ramme. Med bikube er det fleksibelt å administrere og utføre spørringen og en god støttespiller for å utføre funksjoner som innkapsling, ad-hoc-spørsmål. Denne artikkelen gir en kort introduksjon til bikubearkitektur som ligger på Hadoop-laget for å utføre oppsummering i big data.
Hive Architecture med sine komponenter
Hive spiller en viktig rolle i dataanalyse og integrering av forretningsintelligens, og den støtter filformater som tekstfil, rc-fil. Hive bruker et distribuert system for å behandle og utføre spørsmål, og lagringen blir til slutt gjort på disken og til slutt behandlet ved hjelp av et kartreduserende rammeverk. Det løser optimaliseringsproblemet som er funnet under kartreduserende og bikube, utfører batchjobber som er tydelig forklart i arbeidsflyten. Her lagrer en metabutikk skjemainformasjon. Et rammeverk kalt Apache Tez er designet for sanntidsforespørsler.
De viktigste komponentene i Hive er gitt nedenfor:
- Hive klienter
- Hive-tjenester
- Hive lagring (Meta lagring)
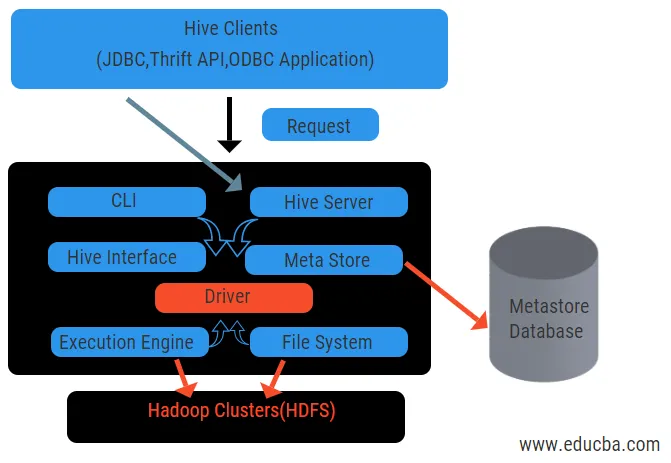
Diagrammet ovenfor viser arkitekturen til Hive og dens komponentelementer.
Hive-kunder:
De inkluderer Thrift-applikasjon for å utføre enkle bikubekommandoer som er tilgjengelige for python, rubin, C ++ og drivere. Disse klientapplikasjonens fordeler for å utføre spørsmål på bikuben. Hive har tre typer klientkategorisering: sparsomme klienter, JDBC og ODBC klienter.
Hive-tjenester:
For å behandle alle spørsmålene bikuben har forskjellige tjenester. Alle funksjonene defineres enkelt av brukeren i bikuben. La oss se alle disse tjenestene i korte trekk:
- Kommandolinjegrensesnitt (brukergrensesnitt): Det muliggjør interaksjon mellom brukeren og bikuben, et standardskall. Det gir en GUI for å utføre hive-kommandolinjen og bikubinnsikt. Vi kan også bruke nettgrensesnitt (HWI) for å sende inn spørsmål og interaksjoner med en nettleser.
- Hive Driver: Den mottar spørsmål fra forskjellige kilder og klienter som sparsommelig server og lagrer og henter på ODBC og JDBC driver som automatisk kobles til bikuben. Denne komponenten gjør semantisk analyse for å se tabellene fra metastore som analyserer en spørring. Driveren tar hjelp av kompilatoren og utfører funksjoner som en analyser, planlegger, utførelse av MapReduce-jobber og optimaliserer.
- Kompilator: Parsing og semantisk prosess av spørringen gjøres av kompilatoren. Den konverterer spørringen til et abstrakt syntaks-tre og igjen til DAG for kompatibilitet. Optimisatoren deler på sin side de tilgjengelige oppgavene. Eksekutorens jobb er å kjøre oppgavene og overvåke rørledningsplanen for oppgavene.
- Utførelsesmotor: Alle spørsmålene behandles av en utførelsesmotor. En DAG-sceneplaner utføres av motoren og hjelper til med å håndtere avhengighetene mellom de tilgjengelige trinnene og utføre dem på en riktig komponent.
- Metastore: Det fungerer som et sentralt lagringssted for å lagre all strukturert informasjon om metadata, også er det en viktig aspektdel for bikuben, da den har informasjon som tabeller og delingsdetaljer og lagring av HDFS-filer. Vi skal med andre ord si at metastore fungerer som et navneområde for tabeller. Metastore anses å være en egen database som også deles av andre komponenter. Metastore har to stykker som kalles service og backlog-lagring.
Datamodellen med bikuber er strukturert i Partisjoner, bøtter, tabeller. Alle disse kan filtreres, ha partisjonstaster og for å evaluere spørringen. Hive-spørring fungerer etter Hadoop-rammeverket, ikke på den tradisjonelle databasen. Hive-server er et grensesnitt mellom spørsmål fra eksterne klienter til bikuben. Utførelsesmotoren er fullstendig innebygd i en bikubeserver. Du kan finne bikube applikasjoner i maskinlæring, forretningsintelligens i oppdagelsesprosessen.
Work Flow of Hive:
Hive fungerer i to typer modus: interaktiv modus og ikke-interaktiv modus. Tidligere modus lar alle bikubekommandoer gå direkte til bikube mens den senere typen kjører kode i konsollmodus. Data er delt inn i partisjoner som videre deles opp i bøtter. Gjennomføringsplaner er basert på aggregering og skjevdata. En ekstra fordel med å bruke bikube er at den enkelt behandler stor skala av informasjon og har flere brukergrensesnitt.
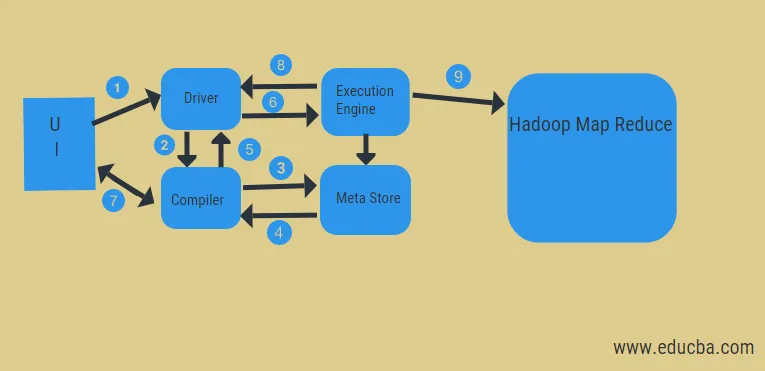
Fra diagrammet over kan vi få et glimt av dataflyten i bikuben med Hadoop-systemet.
Trinnene inkluderer:
- kjør spørringen fra brukergrensesnittet
- få en plan fra driveroppgavene DAG-stadier
- få metadataforespørsel fra metabutikken
- send metadata fra kompilatoren
- sende planen tilbake til sjåføren
- Utfør plan i utførelsesmotoren
- henter resultater for den aktuelle brukerforespørselen
- sende resultater toveisrettet
- utførelse av motorbehandling i HDFS med kart-redusere og hente resultater fra dataknodene opprettet av jobbsøkeren. den fungerer som en forbindelse mellom Hive og Hadoop.
Jobben til utførelsesmotoren er å kommunisere med noder for å få informasjonen lagret i tabellen. Her utføres SQL-operasjoner som opprette, slippe, endre for å få tilgang til tabellen.
Konklusjon:
Vi har gått gjennom Hive Architecture og deres arbeidsflyt. Hive utfører i utgangspunktet petabyte datamengder, og det er en datavarehus-pakke på Hadoop-plattformen. Ettersom bikube er et godt valg å håndtere høyt datavolum, hjelper det i forberedelse av data med guiden til SQL-grensesnittet for å løse MapReduce-problemene. Apache hive er et ETL-verktøy for å behandle strukturerte data. Å kjenne til bruken av bikuberarkitektur hjelper bedriftsfolk til å forstå prinsippet som fungerer i bikuben og har en god start med bikubeprogrammering.
Anbefalte artikler:
Dette har vært en guide til Hive Architecture. Her diskuterer vi bikubens arkitektur, forskjellige komponenter og arbeidsflyten til bikuben. Du kan også se på følgende artikler for å lære mer-
- Hadoop Arkitektur
- Bruker av Ruby
- Hva er C ++
- Hva er MySQL-database
- Hive Bestill av