

Introduksjon til AdaBoost algoritme
AdaBoost-algoritmen kan brukes til å øke ytelsen til hvilken som helst maskinlæringsalgoritme. Machine Learning har blitt et kraftig verktøy som kan gjøre forutsigelser basert på en stor datamengde. Det har blitt så populært i nyere tid at bruken av maskinlæring kan bli funnet i våre daglige aktiviteter. Et vanlig eksempel på det er å få forslag til produkter mens du handler på nettet basert på tidligere gjenstander kjøpt av kunden. Maskinlæring, ofte referert til som prediktiv analyse eller prediktiv modellering, kan defineres som datamaskinens evne til å lære uten å være programmert eksplisitt. Den bruker programmerte algoritmer for å analysere inputdata for å forutsi output innenfor et akseptabelt område.
Hva er AdaBoost-algoritme?
I maskinlæring stod boosting fra spørsmålet om et sett med svake klassifisere kunne konverteres til en sterk klassifiserer. Svak elev eller klassifiserer er en elev som er bedre enn tilfeldig gjetting, og dette vil være robust når det gjelder for mye montering som i et stort sett med svake klassifiserere, der hver svake klassifiserer er bedre enn tilfeldig. Som en svak klassifiserer brukes vanligvis en enkel terskel for en enkelt funksjon. Hvis funksjonen er over terskelen enn forutsagt, hører den til positive ellers hører til negativ.
AdaBoost står for 'Adaptive Boosting' som forvandler svake elever eller prediktorer til sterke prediktorer for å løse klassifiseringsproblemer.
For klassifisering kan den endelige ligningen settes som nedenfor: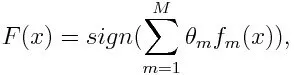
Her utpeker f m den m svake klassifiseringen og m representerer dens tilsvarende vekt.
Hvordan AdaBoost-algoritme fungerer?
AdaBoost kan brukes til å forbedre ytelsen til maskinlæringsalgoritmer. Det brukes best med svake elever og disse modellene oppnår høy nøyaktighet over tilfeldige sjanser for et klassifiseringsproblem. De vanlige algoritmene med AdaBoost som brukes er beslutningstrær med nivå en. En svak elev er en klassifiserer eller prediktor som presterer relativt dårlig med tanke på nøyaktighet. Det kan også antydes at de svake elevene er enkle å beregne og mange forekomster av algoritmer kombineres for å skape en sterk klassifiserer gjennom boosting.
Hvis vi tar et datasett som inneholder n antall poeng, og vurder de nedenfor
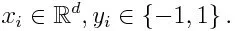
-1 representerer negativ klasse og 1 indikerer positiv. Det initialiseres som nedenfor, vekten for hvert datapunkt som:
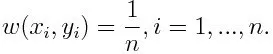
Hvis vi vurderer iterasjon fra 1 til M for m, vil vi få uttrykket nedenfor:
Først må vi velge den svake klassifisereren med den laveste vektede klassifiseringsfeilen ved å tilpasse de svake klassifisererne til datasettet.
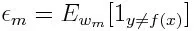
Beregn deretter vekten for den meste svake klassifiseringen som nedenfor:
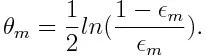
Vekten er positiv for en klassifiserer med en nøyaktighet over 50%. Vekten blir større hvis klassifiseringen er mer nøyaktig og den blir negativ hvis klassifiseringen har nøyaktighet mindre enn 50%. Prediksjonen kan kombineres ved å snu skiltet. Ved å snu prediksjonens tegn, kan en klassifiserer med 40% nøyaktighet konverteres til 60% nøyaktighet. Så klassifisereren bidrar til den endelige prediksjonen, selv om den presterer dårligere enn tilfeldig gjetting. Den endelige prediksjonen vil imidlertid ikke ha noe bidrag eller få informasjon fra klassifiseringen med nøyaktig 50% nøyaktighet. Eksponentiell betegnelse i telleren er alltid større enn 1 for en feilklassifisert sak fra den positive vektede klassifisereren. Etter iterasjon blir de feilklassifiserte sakene oppdatert med større vekter. De negativt vektede klassifisatorene oppfører seg på samme måte. Men det er en forskjell at etter at skiltet er omvendt; de riktige klassifiseringene opprinnelig ville konvertere til feilklassifisering. Den endelige prediksjonen kan beregnes ved å ta hensyn til hver klassifiserer og deretter utføre summen av deres vektede prediksjon.
Oppdaterer vekten for hvert datapunkt som nedenfor:
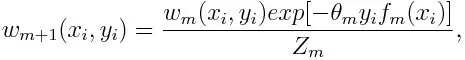
Z m er her normaliseringsfaktoren. Den sørger for at summen av alle instansvekter blir lik 1.
Hva brukes AdaBoost-algoritme til?
AdaBoost kan brukes til ansiktsgjenkjenning da det ser ut til å være standardalgoritmen for ansiktsgjenkjenning i bilder. Den bruker en avvisningskaskade som består av mange lag klassifiserere. Når deteksjonsvinduet ikke gjenkjennes på noe lag som et ansikt, blir det avvist. Den første klassifiseringen i vinduet kaster det negative vinduet og holder beregningskostnadene til et minimum. Selv om AdaBoost kombinerer de svake klassifisatorene, brukes prinsippene til AdaBoost også for å finne de beste funksjonene du kan bruke i hvert lag av kaskaden.
Fordeler og ulemper med AdaBoost-algoritmen
En av de mange fordelene med AdaBoost-algoritmen er at den er rask, enkel og enkel å programmere. Dessuten har den fleksibiliteten til å bli kombinert med en hvilken som helst maskinlæringsalgoritme, og det er ikke nødvendig å stille inn parametrene bortsett fra T. Den er utvidet til å lære problemer utover binær klassifisering, og den er allsidig fordi den kan brukes med tekst eller numerisk data.
AdaBoost har også få ulemper som det er fra empiriske bevis og spesielt utsatt for jevn støy. Svake klassifiseringer som er for svake kan føre til lave marginer og overmasse.
Eksempel på AdaBoost-algoritme
Vi kan vurdere et eksempel på opptak av studenter til et universitet hvor enten de vil bli tatt opp eller nektet. Her finner du de kvantitative og kvalitative data fra forskjellige aspekter. For eksempel kan resultatet av opptaket som kan være ja / nei være kvantitativt, mens ethvert annet område som ferdigheter eller hobbyer fra studenter kan være kvalitativt. Vi kan enkelt komme frem med riktig klassifisering av treningsdata til bedre enn sjansen for forhold som om eleven er god i et bestemt emne, så blir hun / han tatt opp. Men det er vanskelig å finne svært nøyaktig prediksjon og da kommer svake elever inn i bildet.
Konklusjon
AdaBoost hjelper deg med å velge treningssettet for hver nye klassifiserer som blir trent basert på resultatene fra forrige klassifiserer. Også mens du kombinerer resultatene; den bestemmer hvor mye vekt som skal tillegges hver klassifiseres foreslåtte svar. Den kombinerer de svake elevene for å skape en sterk en for å rette opp klassifiseringsfeil, som også er den første vellykkede boostingalgoritmen for binære klassifiseringsproblemer.
Anbefalte artikler
Dette har vært en guide til AdaBoost algoritme. Her diskuterte vi konseptet, bruk, arbeid, fordeler og ulemper med eksempel. Du kan også gå gjennom andre foreslåtte artikler for å lære mer -
- Naive Bayes algoritme
- Spørsmål om markedsføring av sosiale medier
- Link Building Strategies
- Plattform for markedsføring på sosiale medier