

Oversikt over Kafka Applications
Et av trendfeltene i IT-bransjen er Big Data, der selskapet tar for seg en stor mengde kundedata og henter nyttig innsikt som hjelper deres virksomhet og gir kundene bedre service. En av utfordringene er å håndtere og overføre disse store datamengdene fra en ende til en annen for analyse eller prosessering. Det er her Kafka (et pålitelig meldingssystem) kommer inn i stykket, som hjelper til med å samle inn og transportere et enormt datamengde i virkeligheten. Kafka er designet for distribuerte høye gjennomføringssystemer og passer godt for applikasjoner i stor skala. Kafka støtter mange av dagens beste kommersielle og industrielle applikasjoner. Det er etterspørsel etter at Kafka-fagfolk har sterke ferdigheter og praktiske kunnskaper.
I denne artikkelen vil vi lære om Kafka, dens funksjoner, bruke saker og forstå noen bemerkelsesverdige applikasjoner der den brukes.
Hva er Kafka?
Apache Kafka ble utviklet hos LinkedIn og ble senere et open source Apache-prosjekt. Apache Kafka er et raskt, feiltolerant, skalerbart og distribuert meldingssystem som muliggjør kommunikasjon mellom to enheter, dvs. mellom produsenter (generator av meldingen) og forbrukere (mottaker av meldingen) ved hjelp av meldingsbaserte emner og gir en plattform for å håndtere alle datastrømmene i sanntid.
Funksjonene som gjør Apache Kafka bedre enn andre meldingssystemer og som kan brukes på sanntidssystemer, er den høye tilgjengeligheten, øyeblikkelig, automatisk gjenoppretting fra nodefeil og støtter levering av meldinger med lav latens. Disse funksjonene i Apache Kafka er med på å integrere det med store datasystemer og gjør det til en ideell komponent for kommunikasjon. 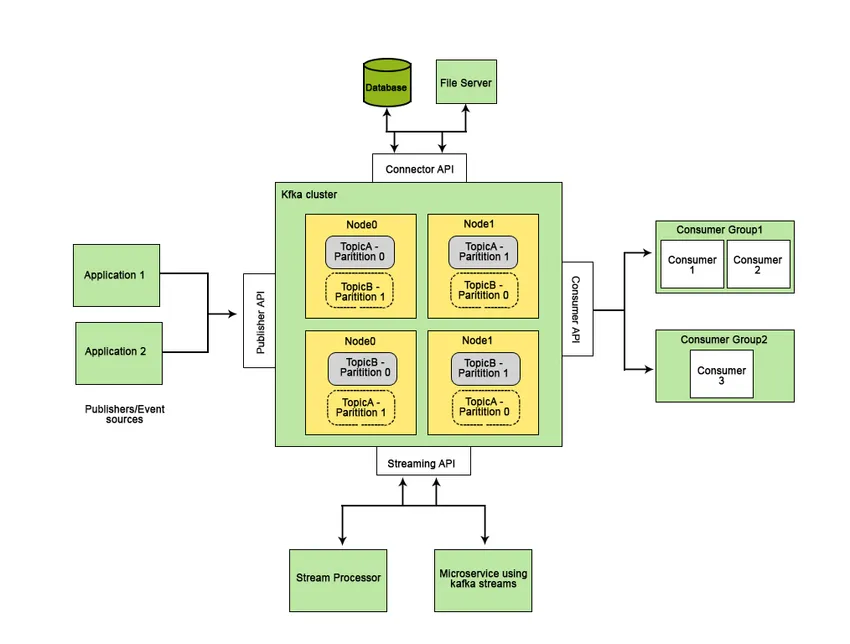
Topp Kafka-applikasjoner
I denne delen av artikkelen vil vi se noen populære og vidt implementerte brukssaker og se noen realistiske implementeringer av Kafka.
Virkelige applikasjoner
1. Twitter: Stream prosesseringsaktivitet
Twitter er en plattform for sosialt nettverk som bruker Storm-Kafka (open source stream-prosesseringsverktøy) som en del av deres strømprosesseringsinfrastruktur, der inngangsdata (tweets) forbrukes for aggregering, transformasjoner og berikelse for videre forbruk eller oppfølging behandlingsaktiviteter.
2. LinkedIn: Stream Processing & Metrics
LinkedIn bruker Kafka for å streame data og for operativ metrisk aktivitet. LinkedIn bruker Kafka for sine tilleggsfunksjoner som Newsfeed for å konsumere meldinger og utføre analyse av mottatte data.
3. Netflix: Sanntidsovervåking og strømbehandling
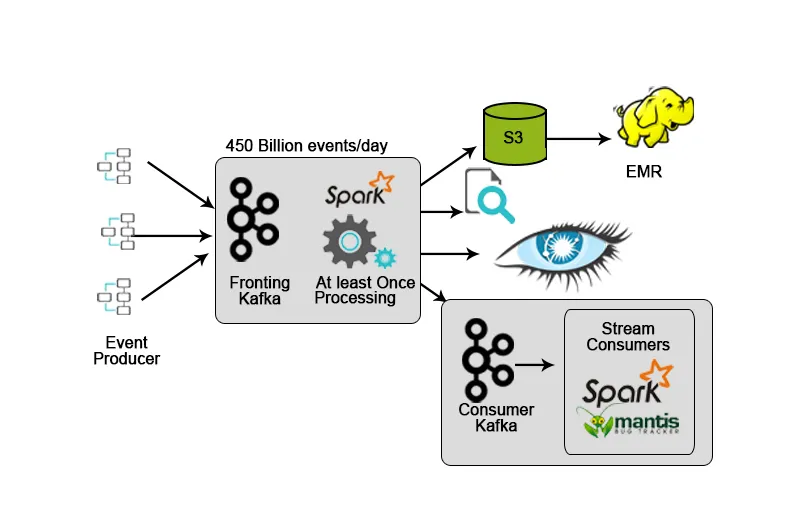
Netflix har et eget inntaksrammeverk som dumper inndata i AWS S3 og bruker Hadoop til å kjøre analyser av videostrømmer, UI-aktiviteter, hendelser for å forbedre brukeropplevelsen og Kafka for sanntid inntak av data via APIer.
4. Hotstar: Streambehandling
Hotstar introduserte sin egen datastyringsplattform - Bifrost der Kafka brukes til datastrømming, overvåking og målsporing. På grunn av sin skalerbarhet, tilgjengelighet og lave latensfunksjoner, var Kafka et ideelt valg å håndtere dataene som hotstar-plattformen genererer på daglig basis eller ved en spesiell anledning (direkteavspilling av konserter, eller hvilken som helst live sport-kamp osv.) Der datamengden øker betydelig.
Apache Kafka brukes for det meste som en byggestein for å utvikle strømningsdataarkitektur. Denne typen arkitektur brukes i applikasjoner som en samling av produkt- / serverlogger, analyse av klikkstrøm og stammer informasjon fra maskingenererte data.
Men sammen med Kafka må vi bruke flere ressurser eller verktøy for å konvertere datastrømmen som er oppnådd til meningsfulle data som hjelper til med å få innsikt som kan brukes i datastyrte beslutninger. For eksempel kan det hende vi må generere innsikt fra rå data hentet fra IoT-enheter, eller data innhentet fra sosiale medieplattformer i sanntid og utføre en analyse eller behandling og vise dem for virksomheten for å ta bedre beslutninger eller hjelpe dem med å forbedre ytelsen til deres tjenester.
For denne typen brukstilfeller ønsker vi å streame inndata / rå data til en datasjø, hvor vi kan lagre dataene våre og sikre datakvalitet uten å hindre ytelsen.
En annen situasjon, kanskje vi leser data direkte fra Kafka, er når vi trenger ekstremt lav ende til ende latenstid, som å mate data til sanntidsapplikasjoner.
Kafka legger ut visse funksjoner for sine brukere:
- Publiser og abonner på data.
- Lagre data i den rekkefølgen de ble generert effektivt.
- Sanntids / On-the-fly-behandling av data.
Kafka brukes mest av:
- Implementering av on-the-fly streaming-datastrørledninger som pålitelig får data mellom to enheter i systemet.
- Implementere on-the-fly streaming applikasjoner som transformerer eller manipulerer eller behandler datastrømmene.
Bruk tilfeller
Nedenfor er noen tilfeller av omfattende implementering av Kafka-applikasjonen:
1. Meldinger
Kafka fungerer bedre enn andre tradisjonelle meldingssystemer som ActiveMQ, RabbitMQ osv. Til sammenligning tilbyr Kafka bedre gjennomstrømming, innebygd partisjonsinnretning, replikering og feiltoleranse, noe som gjør det til et bedre meldingssystem for store prosesseringsbehandlingsapplikasjoner .
2. Sporing av nettstedets aktivitet
Brukeraktiviteter (sidevisninger, søk eller utførte handlinger) kan spores og mates for overvåking eller analyse i sanntid via Kafka eller bruke Kafka til å lagre denne typen data i Hadoop eller datavarehus for senere behandling eller manipulering. Aktivitetssporing genererer en enorm mengde data som må overføres til ønsket sted uten noen form for tap av data.
3. Logg-aggregering
Logg aggregering er en prosess for å samle / slå sammen fysiske loggfiler fra forskjellige servere i en applikasjon til et enkelt depot (filserver eller HDFS) for behandling. Kafka tilbyr god ytelse, lavere ende til ende latenstid sammenlignet med Flume.

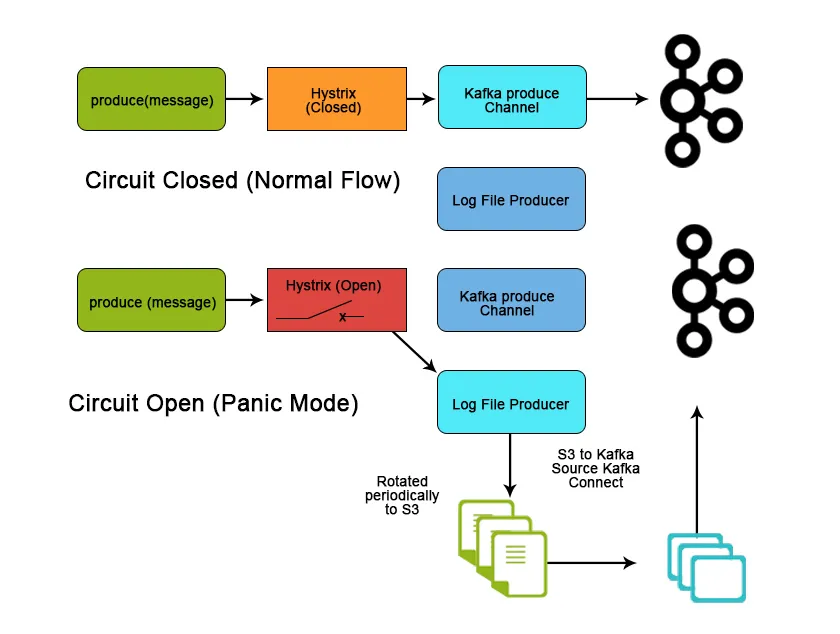
Konklusjon
Kafka brukes tungt i stordataområdet som en måte å innta og flytte store datamengder veldig raskt på grunn av ytelsesegenskaper og funksjoner som hjelper med å oppnå skalerbarhet, pålitelighet og bærekraft. I denne artikkelen diskuterte vi Apache Kafka dens funksjoner, brukstilfeller og applikasjoner og hva som gjør det til et bedre verktøy for strømming av data.
Anbefalte artikler
Dette er en guide til Kafka Applications. Her diskuterer vi hva som er Kafka sammen med topp applikasjoner av Kafka som inkluderer vidt implementerte brukssaker og noen realistiske implementeringer. Du kan også se på følgende artikler for å lære mer-
- Hva er Kafka?
- Hvordan installere Kafka?
- Kafka intervjuspørsmål
- Apache Kafka vs Flume
- Topp 8 enheter av IoT du burde vite
- Kafka vs Kinesis | Forskjeller med Infographics
- Ulike typer Kafka-verktøy med komponenter
- Lær de beste forskjellene på ActiveMQ vs Kafka