
Introduksjon til Hadoop YARN Architecture
MapReduce ble brukt til å utføre både ressursstyring og prosessering i den tidligere Hadoop versjonen 1.0. Her utførte Job Tracker ressursfordeling, planlegging og overvåking av jobber ved å tilordne kart og redusere oppgaver til Task Tracker. Dette resulterte i problemer som skalerbarhet, ineffektiv ressursutnyttelse. Ettersom Hadoop-rammeverket har gjennomgått flere endringer gjennom årene; vi kan se at den kan brukes til å utføre mye mer enn bare å kjøre MapReduce-jobbene. YARN står for Yet Another Resource Negotiator som kalles klyngestyringssystemet til Hadoop som ble introdusert med Hadoop 2.0 for å støtte distribuert databehandling som også forbedrer implementeringen av MapReduce. I YARN er ressurssjefen og planleggere eksterne for rammen. Så i YARN, selv om vi har datanoder, er det ikke lenger Task Trackers eller Job Trackers. Også med YARN kan vi ha ressursstyring så vel som generisk planlegging. I dette emnet skal vi lære om den forskjellige arkitekturen til YARN
Forklar Hadoop YARN Architecture med diagram
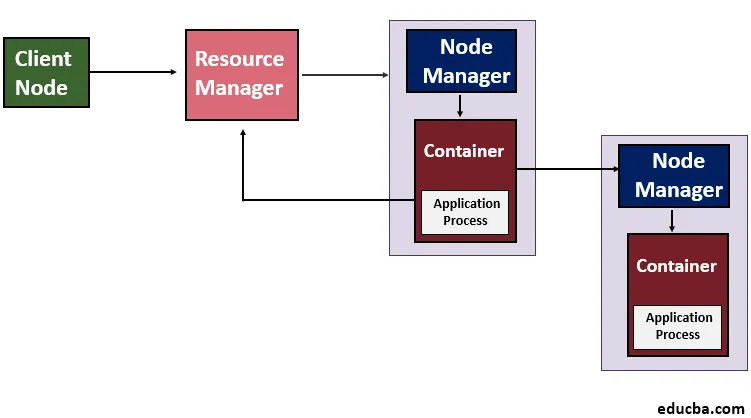
(Arkitektur av Hadoop YARN)
YARN introduserer konseptet med en ressurssjef og en applikasjonsmester i Hadoop 2.0. Ressurssjefen ser bruken av ressursene på tvers av Hadoop-klyngen, mens livssyklusen til applikasjonene som kjører på en bestemt klynge overvåkes av Application Master. I utgangspunktet kan vi si at for klyngeressurser forhandler Application Master med ressurssjefen. Denne oppgaven utføres av containerne som har bestemte minnebegrensninger. Deretter brukes disse containerne til å kjøre de applikasjonsspesifikke prosessene, og også disse beholderne overvåkes av Node Managers som kjører på noder i klyngen. Dette vil bekrefte at ikke mer enn de tildelte ressursene brukes av applikasjonen.
Ulike komponenter av YARN
Nedenfor er de forskjellige komponentene i YARN.
1) Ressurssjef
YARN fungerer gjennom en ressursbehandling som er en per node og Node Manager som kjører på alle nodene. Ressurssjefen administrerer ressursene som brukes over klyngen, og Node Manager lunsjer og overvåker containerne. Scheduler og Application Manager er to komponenter i Resource Manager.
- Planlegger : Planlegging utføres basert på kravet til ressurser fra applikasjonene. YARN gir få planleggere å velge mellom, og de er rettferdig og kapasitetsplanlegger. I tilfelle maskinvare- eller applikasjonssvikt, sørger ikke planleggeren for å starte de mislykkede oppgavene på nytt. Planlegger tildeler også ressurser til de kjørende applikasjonene basert på kapasitet og kø.
- Application Manager : Den klarer driften av Application Master i en klynge og på feilen av Application Master Container, hjelper det med å starte den på nytt. Det bærer også ansvaret for å akseptere innlevering av jobbene.
2) Node Manager
Node Manager er ansvarlig for utførelsen av oppgaven i hver datanode. Node Manager i YARN sender som standard et hjerteslag til Resource Manager som bærer informasjonen om de kjørende containere og angående tilgjengeligheten av ressurser for de nye containerne. Det er ansvarlig for å sørge for nodene i klyngen individuelt og administrere arbeidsflyten og brukerjobbene på en spesifikk node. I hovedsak administrerer den applikasjonsbeholderne som er tildelt av ressurssjefen. Node Manager starter beholderne med å opprette containerprosessene som etterspørres, og den dreper også containerne som anmodet av ressurssjefen.
3) Beholdere
Beholderne er satt av ressurser som RAM, CPU og minne osv. På en enkelt node, og de er planlagt av Resource Manager og overvåket av Node Manager. Container Life Cycle administrerer YARN-containerne ved å bruke container lanseringskontekst og gir tilgang til applikasjonen for den spesifikke bruken av ressurser i en bestemt vert.
4) Søknad Master
Den overvåker utførelsen av oppgaver og administrerer også livssyklusen til applikasjoner som kjører på klyngen. En individuell applikasjonsmester blir tilknyttet en jobb når den sendes inn i rammen. Hovedansvaret er å forhandle om ressursene fra ressurssjefen. Det fungerer med Node Manager for å overvåke og utføre oppgavene.
For å kjøre en applikasjon gjennom YARN, utføres trinnene nedenfor.
- Klienten kontakter ressursbehandleren som ber om å kjøre søknadsprosessen, dvs. at den sender inn YARN-applikasjonen.
- Neste trinn er at Ressursbehandleren søker etter en Node Manager som igjen vil starte applikasjonsmesteren i en container.
- Application Master kan enten kjøre utførelsen i beholderen som den kjører for øyeblikket og gi resultatet til klienten, eller den kan be om flere containere fra resource manager som kan kalles distribuert databehandling.
- Klienten kontakter deretter ressursbehandleren for å overvåke statusen til applikasjonen.
Med MapReduce i Hadoop versjon 1.0 (MRV1) ble antall kart og reduserte spor definert per node. Også i en Hadoop-klynge, da maskinvarefunksjonene varierte og antall oppgaver på en spesifikk node måtte begrenses manuelt. Men med YARN overvinnes denne mangelen fordi her ressursbehandler vet om kapasiteten til hver node når den kommuniserer med Node Manager som kjører på hver node.
Konklusjon - Hadoop YARN Architecture
YARN hjelper med å overvinne skalerbarhetsproblemet til MapReduce i Hadoop 1.0 når det deler jobben til Job Tracker, både av jobbplanlegging og overvåking av fremdriften for oppgavene. Spørsmålet om tilgjengelighet blir også overvunnet som tidligere i Hadoop 1.0 Job Tracker-feilen førte til at oppgavene ble startet på nytt. YARN kom med mange ekstra bonuser som bedre ressursutnyttelse, da det ikke er noen faste spor for oppgaver, da det gir sentral ressursstyring. Så med YARN blir mange av problemene i den tidligere versjonen av Hadoop overvunnet, da det hjelper med å skille databehandlingen fra planlegging og ressursstyring. Med YARN er det mulig å kjøre interaktive spørsmål uavhengig, samt gi bedre sanntidsanalyse.
Anbefalte artikler
Dette har vært en guide til Hadoop YARN Architecture. Her diskuterer vi de forskjellige komponentene i YARN som inkluderer Ressurssjef, Node Manager og Containers sammen med Arkitekturen. Du kan også gå gjennom andre foreslåtte artikler for å lære mer -
- Apache Hadoop økosystem
- Hadoop økosystemkomponenter
- Hadoop-komponenter
- Hadoop økosystem