
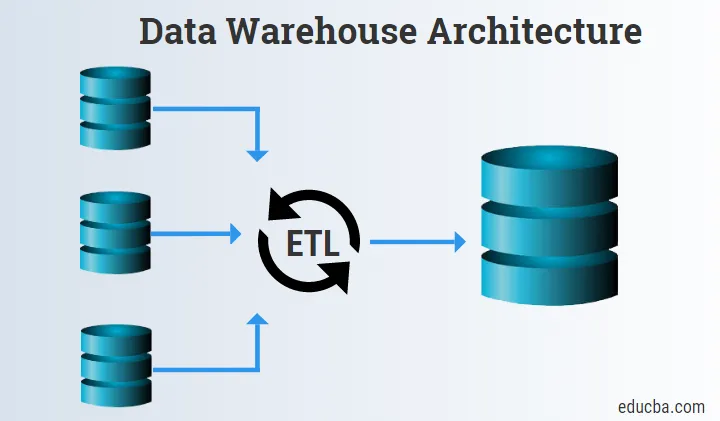
Introduksjon til datavarehusarkitektur
- Et datavarehus er et lagringssted som inneholder samlinger av flere forskjellige typer data hentet fra flere typer kilder.
- Hele prosessen der eksterne datakilder er anskaffet, behandlet, lagret og analysert til brukbar informasjon, foregår innenfor et sett av systemer som er samlet av et enkelt skjema kjent som Data Warehouse Architecture.
Datavarehusarkitektur

Data Warehouse Architecture består vanligvis av tre nivåer.
- Toppsjiktet
- Midttrinn
- Nederste nivå
Toppsjiktet
- Top Tier består av klientsiden foran enden av arkitekturen.
- Den transformerte og logiske anvendte informasjonen som er lagret i datavarehuset vil bli brukt og anskaffet til forretningsformål i dette nivået.
- Flere verktøy for rapportgenerering og analyse er til stede for generering av ønsket informasjon.
- Data mining som har blitt en stor trend i disse dager gjøres her.
- Alle krav til analysedokument, kostnad og alle funksjoner som bestemmer en gevinstbasert forretningsavtale gjøres basert på disse verktøyene som bruker Data Warehouse-informasjonen.
Midttrinn
- The Middle Tier består av OLAP-serverne
- OLAP er online analytisk prosesseringsserver
- OLAP brukes til å gi informasjon til forretningsanalytikere og ledere
- Ettersom den ligger i mellomtrinnet, samhandler den rettmessig med informasjonen som finnes i bunnnivået og videreformidler innsikten til Top Tier-verktøyene som behandler tilgjengelig informasjon.
- For det meste brukes Relational eller MultiDimensional OLAP i datavarehusarkitektur.
Nederste nivå
Bunnnivået består hovedsakelig av datakilder, ETL-verktøy og datavarehus.
1. Datakilder
Datakildene består av kildedataene som er anskaffet og gitt til Staging og ETL-verktøyene for videre prosess.
2. ETL-verktøy
- ETL-verktøy er veldig viktige fordi de hjelper til med å kombinere Logic, Raw Data og Schema til ett og laster inn informasjonen til Data Warehouse eller Data Marts.
- Noen ganger laster ETL dataene inn i datamarkene, og deretter lagres informasjonen i Data Warehouse. Denne tilnærmingen er kjent som Bottom Up-tilnærmingen.
- Tilnærmingen der ETL laster informasjon til Data Warehouse direkte, er kjent som Top-down Approach.
Forskjellen mellom ovenfra og ned-tilnærming
| Topp-ned tilnærming | Bottom-Up tilnærming |
| Gir et klart og konsistent syn på informasjonen ettersom informasjon fra datavarehuset brukes til å lage datamarkeringer | Rapporter kan genereres enkelt når datamark blir opprettet først, og det er relativt enkelt å samhandle med datamark. |
| Sterk modell og følgelig foretrukket av store selskaper | Ikke like sterkt, men datavarehus kan utvides og antall datamark kan opprettes |
| Tid, kostnader og vedlikehold er høy | Tid, kostnader og vedlikehold er lav. |
Datamars
- Data Mart er også en lagringskomponent som brukes til å lagre data om en bestemt funksjon eller del relatert til et selskap av en individuell myndighet.
- Datamart samler informasjonen fra Data Warehouse, og derfor kan vi si at datamart lagrer delmengden av informasjon i Data Warehouse.
- Data Marts er fleksible og små i størrelse.
3. Datavarehus
- Data Warehouse er den sentrale komponenten i hele Data Warehouse Architecture.
- Det fungerer som et depot for å lagre informasjon.
- Store datamengder lagres i datavarehuset.
- Denne informasjonen brukes av flere teknologier som Big Data som krever analyse av store undergrupper av informasjon.
- Data Mart er også en modell av Data Warehouse.
Ulike lag med datavarehusarkitektur
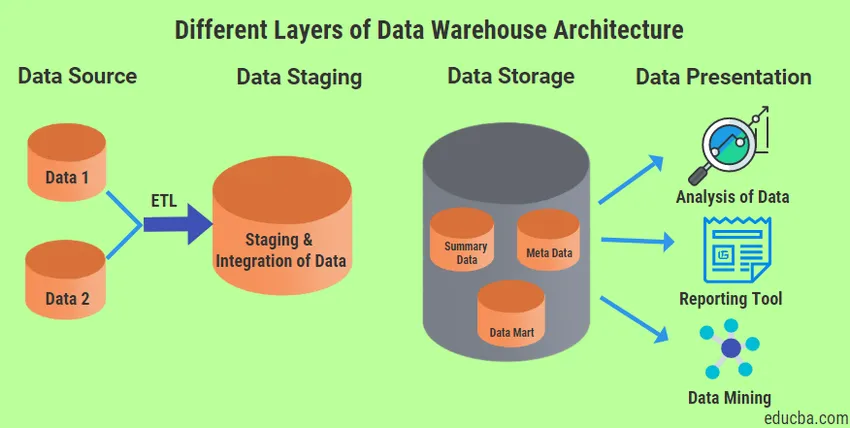
Det er fire forskjellige typer lag som alltid vil være til stede i Data Warehouse Architecture.
1. Datakildelag
- Datakildelaget er laget der dataene fra kilden blir funnet og deretter sendt til de andre lagene for ønsket handling.
- Dataene kan være av hvilken som helst type.
- Kildedataene kan være en database, et regneark eller andre typer tekstfiler.
- Kildedataene kan være av et hvilket som helst format. Vi kan ikke forvente å få data med samme format med tanke på at kildene er veldig forskjellige.
- I det virkelige liv kan noen eksempler på kildedata være
- Logg filer av hver spesifikk applikasjon eller jobb eller oppføring av arbeidsgivere i et selskap.
- Kartleggingsdata, børsdata, etc.
- Nettleserdata og mange flere.
2. Lagring av data
Følgende trinn finner sted i Data Staging Layer.
1. Datautvinning
Dataene mottatt av kildelaget føres inn i iscenesettingslaget der den første prosessen som foregår med innhentet data er utvinning.
2. Landingsdatabase
- De ekstraherte dataene lagres midlertidig i en landingsdatabase.
- Den henter dataene når dataene er hentet ut.
3. Iscenesettelsesområde
- Dataene i landingsdatabasen blir tatt og flere kvalitetskontroller og iscenesettelsesoperasjoner utføres i iscenesettelsesområdet.
- Strukturen og skjemaet blir også identifisert og justeringer blir gjort til data som ikke er ordnet, og prøver å få til en fellestrekk blant dataene som er anskaffet.
- Å ha et sted eller konfigurert for dataene like før transformasjon og endringer er en ekstra fordel som gjør Staging-prosessen veldig viktig.
- Det gjør databehandlingen enklere.
4. ETL
- Det er en utvinning, transformasjon og belastning.
- ETL-verktøy brukes til integrering og prosessering av data der logikk brukes på ganske rå, men noe bestilte data.
- Disse dataene blir trukket ut i henhold til den analytiske naturen som er nødvendig og transformert til data som anses for å være lagret i Data Warehouse.
- Etter transformasjon blir dataene eller rettere sagt en informasjon endelig lastet inn i datavarehuset.
- Noen eksempler på ETL-verktøy er Informatica, SSIS, etc.
3. Lagring av data
- De behandlede dataene lagres i Data Warehouse.
- Disse dataene blir renset, transformert og utarbeidet med en bestemt struktur og gir dermed muligheter for arbeidsgivere til å bruke data etter behov fra virksomheten.
- Avhengig av tilnærmingen til arkitekturen, vil dataene bli lagret i Data Warehouse så vel som Data Marts. Data Marts vil bli diskutert i de senere stadier.
- Noen inkluderer også en operasjonell datalager.
4. Lag for datapresentasjon
- Dette laget hvor brukerne får samhandle med dataene som er lagret i datavarehuset.
- Spørsmål og flere verktøy vil bli brukt for å få forskjellige typer informasjon basert på dataene.
- Informasjonen når brukeren gjennom grafisk fremstilling av data.
- Rapporteringsverktøy brukes for å få forretningsdata, og forretningslogikk brukes også for å samle flere typer informasjon.
- Metadatainformasjon og systemoperasjoner og ytelse opprettholdes og sees i dette laget.
Konklusjon
Et viktig poeng med Data Warehouse er effektiviteten. For å lage et effektivt datavarehus konstruerer vi et rammeverk kjent som forretningsanalyserammen. Det er fire typer visninger når det gjelder utformingen av et datavarehus.
1. Topp-ned-visning: Denne visningen lar bare spesifikk informasjon som trengs for et datavarehus, velges.
2. Datakildevisning: Denne visningen viser all informasjonen fra datakilden til hvordan den transformeres og lagres.
3. Datavarehusvisning: Denne visningen viser informasjonen som finnes i datavarehuset gjennom faktatabeller og dimensjonstabeller.
4. Business Query View: Dette er en visning som viser dataene fra brukerens synspunkt.
Anbefalte artikler
Dette har vært en guide til Data Warehouse Architecture. Her diskuterte vi de forskjellige typene visninger, lag og nivåer av datavarehusarkitektur. Du kan også gå gjennom andre foreslåtte artikler for å lære mer -
- Karriere innen datalagring
- Slik fungerer JavaScript
- Datavarehus Intervjuespørsmål
- Hva er Pandas