

Hva er datamining?
Før vi forstår, Data Mining Concepts and Techniques, vil vi først studere data mining. Data mining er en funksjon i konvertering av data til noe kunnskapsrik informasjon. Dette refererer til prosessen med å få litt ny informasjon ved å se på en stor mengde tilgjengelige data. Ved hjelp av forskjellige teknikker og verktøy kan man forutsi informasjonen som kreves fra dataene, bare hvis fremgangsmåten som følges er korrekt. Dette er nyttig i forskjellige bransjer for å hente ut nødvendig informasjon for fremtidig analyse ved å gjenkjenne noen mønstre i eksisterende data i databaser, datavarehus, etc.
Typer av data i datamining
Følgende er typer data som data mining kan utføres på:
- Relasjonsdatabaser
- Datavarehus
- Avanserte DB- og informasjonsdatabaser
- Objektorienterte og objektrelasjonelle databaser
- Transaksjonelle og romlige databaser
- Heterogene databaser og arv
- Multimedia og streaming database
- Tekstdatabaser
- Tekst gruvedrift og nettverksdrift
Databehandling
Nedenfor er poengene for data mining prosess:
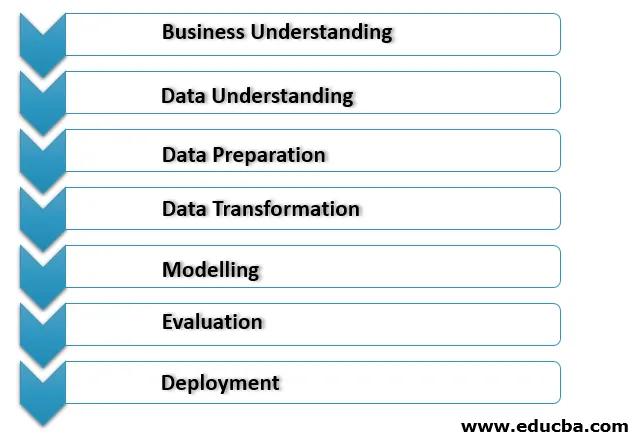
1. Forståelse av virksomheten
Dette er den første fasen av implementeringen av data mining, der alle behov og klientens mål om virksomhet er klart forstått. Riktige mål for data mining er satt slik at man ser på det aktuelle scenariet i virksomheten og andre faktorer som ressurser, forutsetninger, begrensninger. En skikkelig data mining-plan skal være i detalj og må oppfylle våre forretnings- og data mining-mål.
2. Forståelse av data
Denne fasen fungerer som en tilsynelatende sjekk av dataene som er samlet inn fra forskjellige ressurser for data mining prosesser. Først alle dataene fra de forskjellige kildene er samlet relatert til organisasjonsforretningsscenariet som kan være i de forskjellige databasene, flatfiler osv. De innsamlede dataene sjekkes at de stemmer riktig, da de kan være upålitelige.
Noen ganger må også metadata sjekkes for å redusere feilene i data mining prosessene. Forskjellige data mining-spørsmål brukes til analyse av riktige data og basert på resultatene kan datakvaliteten kontrolleres. Det hjelper også til å analysere om data mangler eller ikke.
3. Forberedelse av data
Denne prosessen bruker maksimal tid på prosjektet. Dette ansiktet inkluderer en prosess som kalles datarensing for å rense dataene som er samlet inn under prosessen med å forstå data. Datarensingsprosessen brukes til å rense dataene for å ekskludere feil støyende data for dataene med manglende verdier.
4. Datatransformasjon
I den neste tilstanden utføres datatransformasjonsoperasjoner som brukes til å endre dataene for å gjøre dem nyttige for implementeringen av data mining. Her transformasjon som aggregering, generaliseringer, normalisering eller attributtkonstruksjon for å gjøre dataene klare for datamodelleringsprosessen.
5. Modellering
Dette er fasen i data mining hvor riktig teknikk brukes til å bestemme datamønster. De forskjellige scenariene må lages for å sjekke kvaliteten og gyldigheten av denne modellen og for å avgjøre om målene som er definert i forretningsforståelsesprosessen blir oppfylt etter implementering av disse teknikkene. Mønsteret som er funnet i denne prosessen evalueres videre og sendes for distribusjon til forretningsdriften, slik at det kan bidra til å forbedre organisasjonenes forretningspolitikk.
6. Evaluering
I denne fasen blir den riktige evalueringen av data mining-funnene gjort for å gi den et forsøk på å implementere i forretningsprosessene. En riktig sammenligning blir gjort med funnene og den eksisterende forretningsdriftsplanen for å evaluere endringen for informasjonen som er funnet, må legges til den nåværende forretningsdriften.
7. Distribusjon
I denne fasen blir informasjonen som er avsluttet ved bruk av data mining prosesser transformert togforståelig form for ikke-tekniske interessenter. For denne prosessen opprettes en riktig distribusjonsplan som inkluderer forsendelse, vedlikehold og overvåking av informasjonen som er funnet. På denne måten blir riktig prosjektrapport laget sammen med erfaringene og erfaringene under prosessen for å overlate funnene om data mining til forretningsdriftsteamet.
Derfor hjelper denne prosessen til å forbedre en virksomhets politikk.
Dataminingsteknikker
Nedenfor kan teknikker og teknologier bidra til å anvende data mining-funksjonen på sin mest effektive måte:
1. Spor mønsterene
Å gjenkjenne mønstrene i datasettet ditt er en av de grunnleggende teknikkene i data mining. Dataene blir observert med jevne mellomrom for gjenkjennelse av noe avvik. For eksempel kan det sees om en bestemt person reiser rundt i forskjellige land, så vil den personen måtte bestille billetter med jevne mellomrom, og dermed kan et spesielt kredittkort tilbys.
2. Klassifisering
Det er en av de komplekse teknikkene for data mining, der vi trenger å lage forskjellige kategorier som kan skilles med forskjellige attributter i eksisterende data. Disse kategoriene er med på å nå ulike konklusjoner for vår fremtidige bruk. Mens du for eksempel analyserer dataene for trafikk i byen, kan områdets trafikk klassifiseres under lav, middels og tung. Dette vil hjelpe de reisende til å forutsi trafikken før tiden.
3. Forening
Denne teknikken ligner på mønstersporingsteknikken, men her er den relatert til de avhengige koblede variablene. Det betyr at mønsteret for relaterte data blir funnet som er koblet til eksisterende data. Hendelsesrelatert til den andre hendelsen spores, og de spesielle mønstrene finnes i disse dataene. For eksempel filsporingsdata for trafikken i en bestemt by man også kan spore, de mest besøkte stedene i en by. Dette kan også bidra til å spore kjente steder som skal besøkes i byen.
4. Oppdagelse tidligere
Denne teknikken er relatert til ekstraksjon av anomalier i datamønsteret. For eksempel gir salget av et kjøpesenter et godt overskudd i løpet av de 11 månedene av året, men i løpet av den siste måneden synker salget så mye at det fører til tap. I disse tilfellene må vi finne ut hva som var faktoren som gjorde reduksjonen i salget slik at man kan unngå det neste gang. Teknikken for å finne en slik distraksjon i det vanlige mønsteret er del av Outlier-deteksjonsteknikken.
5. Clustering
Denne teknikken ligner klassifisering, bare forskjellen ligger i at den velger gruppen av data som har noen likheter, setter dem i en enkelt gruppe. For eksempel å gruppere forskjellige målgrupper på en kino på grunnlag av frekvens som hvor ofte de kommer for show, hvilken timing de kommer for oftest og hvilken sjanger av film de kommer for.
6. Regresjon
Denne teknikken hjelper til med å trekke forholdet mellom de to variablene en analyse kan være avhengig av. Her prøver vi å finne ut mønsteret med endring i variabelen ved å fikse de andre avhengige variablene. Hvis vi for eksempel trenger å finne ut mønsteret i salg av et produkt i et kjøpesenter, avhengig av tilgjengeligheten, sesongen, etterspørselen osv. Dette kan føre til at eieren må fastsette prisen for å selge det.
7. Prediksjon
Den viktigste funksjonen ved data mining er å redusere fremtidige risikoer og øke fortjenesten for organisasjonen ved å studere eksisterende og historiske mønstre for salgs- og kredittrisiko. Her hjelper denne typen teknologi oss til å ta fremtidige beslutninger avhengig av mønsteret som finnes i historiske og nåværende data og holde markedets endring og risiko i tankene. Denne teknikken er mest nyttig for data mining.
Verktøy for datautvinning
Man trenger ikke de nyeste nyeste teknologiene for å utføre data mining. Det kan gjøres ved hjelp av de nyeste databasesystemene, og enkle verktøy som er lett tilgjengelig i enhver organisasjon. Man kan også lage sitt eget verktøy når det aktuelle verktøyet mangler. Det mest populære verktøyet er mye brukt i bransjen er gitt nedenfor:
1. R-språk
Dette er et åpen kildekodeverktøy som brukes til statistisk databehandling og grafikk. Dette verktøyet hjelper deg med effektiv håndtering av data og lagringsanlegg, og disse funksjonene er på grunn av teknikkene nedenfor:
- statistisk
- Klassiske statistiske tester
- Tidsserie-analyse
- Klassifisering
- Grafiske teknikker
2. Oracle Data Mining
Dette verktøyet er populært kjent som ODM, det er en del av Oracle Advanced Analytics-databasen. Dette verktøyet hjelper til med å analysere data i datavarehus og genererer detaljert innsikt som hjelper deg videre med å komme med forutsigelser. Disse tingene hjelper til med å studere kundeatferd, produkter etterspør annonser og hjelper dermed i trinn på salgsmuligheter.
Utfordringer som blir møtt med implementeringen av Data mine:
- Dyktige eksperter er nødvendige for å lage komplekse data mining-spørsmål.
- Nåværende modeller passer kanskje ikke i fremtidens statlige databaser. Det kan hende at de ikke passer til fremtidige stater.
- Vanskeligheter med å håndtere store databaser.
- Det kan være behov for å endre forretningspraksis for å bruke informasjon som er avdekket.
- Heterogene databaser og informasjon som kommer globalt, kan resultere i kompleks integrert informasjon.
- Data mining har en forutsetning om at data må være mangfoldig, ellers kan resultatene være unøyaktige.
Konklusjon-data gruvedrift konsepter og teknikker
- Data mining er en måte å spore tidligere data og foreta fremtidige analyser ved å bruke dem.
- Det er det samme som å trekke ut den informasjonen som kreves for analyse fra eiendeler til forrige dato som allerede er til stede i databasene.
- Data mining kan gjøres på forskjellige typer databaser som romlig datagrunnlag, RDBMS, datavarehus, flere databaser, etc.
- Hele gruveprosessen inkluderer forretningsforståelse, forståelse av data, forberedelse av data, modellering, utvikling, distribusjon.
- Ulike data mining-teknikker er tilgjengelige for å gjøre data mining arbeid på en effektiv måte som klassifisering, regresjonsassosiasjon, etc. Bruk avhenger av scenariet.
- De mest effektive data mining-verktøyene er R-språk og Oracle Data.
- Den største ulempen med data mining er den vanskeligheten som trener eksperter i å operere denne analyseprogramvaren.
- Det er forskjellige bransjer som bruker data mining for sitt analyseformål som bank, industri, supermarkeder, detaljhandelsleverandører, etc.
Anbefalte artikler
Dette er en guide til Data Mining Concepts and Techniques. Her diskuterer vi prosessen, teknikkene og verktøyene i Data Mining. Du kan også gå gjennom andre relaterte artikler for å lære mer-
- Fordeler med data mining
- Hva er datamining?
- Databehandling
- Datavitenskapsteknikker
- Clustering in Machine Learning
- Hvordan generere testdata?
- Guide to Models in Data Mining