

Forskjellen mellom Big Data og Apache Hadoop
Alt er på internett. Internett har mye data. Derfor er alt Big Data. Vet du at 2, 5 Quintillion Bytes Data opprettes hver dag og hoper seg opp som Big Data? De daglige aktivitetene våre som kommentarer, likes, innlegg osv. På sosiale medier som Facebook, LinkedIn, Twitter og Instagram legger opp som en Big Data. Det antas at innen 2020 skal det opprettes nesten 1, 7 megabyte med data hvert sekund, for hver person på jorden. Du kan forestille deg og vurdere hvor mye data som blir generert forutsatt av hver eneste person på jorden. I dag er vi koblet og deler livene våre på nettet. De fleste av oss er koblet på nettet. Vi bor i et smart hjem og bruker smarte kjøretøyer og alle er koblet til smarte telefoner. Har du noen gang forestilt deg hvordan disse enhetene blir smarte? Jeg vil gjerne gi deg veldig enkelt svar, det er på grunn av å analysere den veldig store datamengden, dvs. Big Data. I løpet av fem år vil det være over 50 milliarder smarte tilkoblede enheter i verden, alle utviklet for å samle inn, analysere og dele data for å gjøre livene våre mer komfortable.
Følgende er introduksjonene til Big Data vs Apache Hadoop
Vi introduserer Term Big Data
Hva er Big Data? Hvilken størrelse på data anses for å være stor og vil bli betegnet som Big Data? Vi har mange relative forutsetninger for begrepet Big Data. Det er mulig at datamengden sier at 50 terabyte kan betraktes som big data for oppstart, men det er kanskje ikke Big Data for selskapene som Google og Facebook. Det er fordi de har infrastruktur for å lagre og behandle datamengden. Jeg vil definere begrepet Big Data som:
- Big Data er datamengden like utenfor teknologiens mulighet til å lagre, administrere og behandle effektivt.
- Big Data er data hvis omfang, mangfold og kompleksitet krever ny arkitektur, teknikker, algoritmer og analyser for å håndtere dem og hente ut verdi og skjult kunnskap fra den.
- Big data er informasjonsmidler med høyt volum og høy hastighet og høy variasjon som krever kostnadseffektive, innovative former for informasjonsbehandling som muliggjør forbedret innsikt, beslutninger og prosessautomatisering.
- Big Data refererer til teknologier og initiativer som involverer data som er for mangfoldig, raskt endrende eller massiv til at konvensjonelle teknologier, ferdigheter og infrastruktur kan adressere effektivt. Sagt annerledes er volumet, hastigheten eller variasjonen av data for stort.
3 V av Big Data
- Volum: Volum refererer til mengden / mengden som data skapes som hver time Wal-Mart-kundenes transaksjoner gir selskapet omtrent 2, 5 petabyte med data.
- Velocity: Velocity refererer til hastigheten som data beveger seg som Facebook-brukere i gjennomsnitt sender 31, 25 millioner meldinger og ser på 2, 77 millioner videoer hvert minutt hver eneste dag over internett.
- Variasjon: Variasjon refererer til forskjellige formater av data som er opprettet som strukturerte, semistrukturerte og ustrukturerte data. Som å sende e-postmeldinger med vedlegget på Gmail er ustrukturerte data, mens innlegg av kommentarer med noen eksterne lenker også betegnes som ustrukturerte data. Deling av bilder, lydklipp, videoklipp er en ustrukturert form for data.
Å lagre og behandle dette enorme volumet, hastigheten og mangfoldigheten av data er et stort problem. Vi må tenke på annen teknologi enn RDBMS for Big Data. Det er fordi RDBMS bare er i stand til å lagre og behandle strukturerte data. Så her kommer Apache Hadoop som en redning.
Vi presenterer Term Apache Hadoop
Apache Hadoop er et programvare med åpen kildekode for lagring av data og kjøring av applikasjoner på klynger av maskinvare. Apache Hadoop er et programvareramme som gjør det mulig å distribuere behandlingen av store datasett på tvers av datamaskiner med enkle programmeringsmodeller. Den er designet for å skalere opp fra enkle servere til tusenvis av maskiner, som hver tilbyr lokal beregning og lagring. Apache Hadoop er et rammeverk for lagring og behandling av Big Data. Apache Hadoop er i stand til å lagre og behandle alle formater av data som strukturerte, semistrukturerte og ustrukturerte data. Apache Hadoop er åpen kildekode og råvaremaskinvare brakt revolusjon til IT-bransjen. Det er lett tilgjengelig for alle nivåer av selskaper. De trenger ikke å investere mer for å sette opp Hadoop-klyngen og på annen infrastruktur. Så la oss se den nyttige forskjellen mellom Big Data og Apache Hadoop i detalj i dette innlegget.
Apache Hadoop rammeverk
Apache Hadoop-rammeverket er delt inn i to deler:
- Hadoop Distribuert filsystem (HDFS): Dette laget er ansvarlig for lagring av data.
- MapReduce: Dette laget er ansvarlig for å behandle data på Hadoop Cluster.
Hadoop Framework er delt inn i master- og slavearkitektur. Hadoop Distribution File System (HDFS) lag Navn Node er hovedkomponent mens Data Node er Slave-komponent mens i MapReduce-laget er Job Tracker master-komponent mens task tracker er slave-komponent. Nedenfor er diagrammet for rammeverk av Apache Hadoop.
Hvorfor er Apache Hadoop viktig?
- Mulighet for å lagre og behandle enorme mengder av alle slags data, raskt
- Datakraft: Hadoops distribuerte datamodell behandler big data raskt. Jo flere databehandlingsnoder du bruker, jo mer prosessorkraft har du.
- Feiltoleranse: Data- og applikasjonsbehandling er beskyttet mot maskinvarefeil. Hvis en node går ned, blir jobber automatisk omdirigert til andre noder for å sikre at den distribuerte databehandlingen ikke mislykkes. Flere kopier av alle data lagres automatisk.
- Fleksibilitet: Du kan lagre så mye data du vil og bestemme hvordan du skal bruke dem senere. Dette inkluderer ustrukturerte data som tekst, bilder og videoer.
- Lave kostnader: Open-source rammeverket er gratis og bruker råvaremaskinvare til å lagre store datamengder.
- Skalerbarhet: Du kan enkelt utvide systemet ditt til å håndtere mer data bare ved å legge til noder. Lite administrasjon er nødvendig
Sammenligning fra topp mot hodet mellom Big Data vs Apache Hadoop (Infographics)
Nedenfor er Topp 4-sammenligningen mellom Big Data vs Apache Hadoop
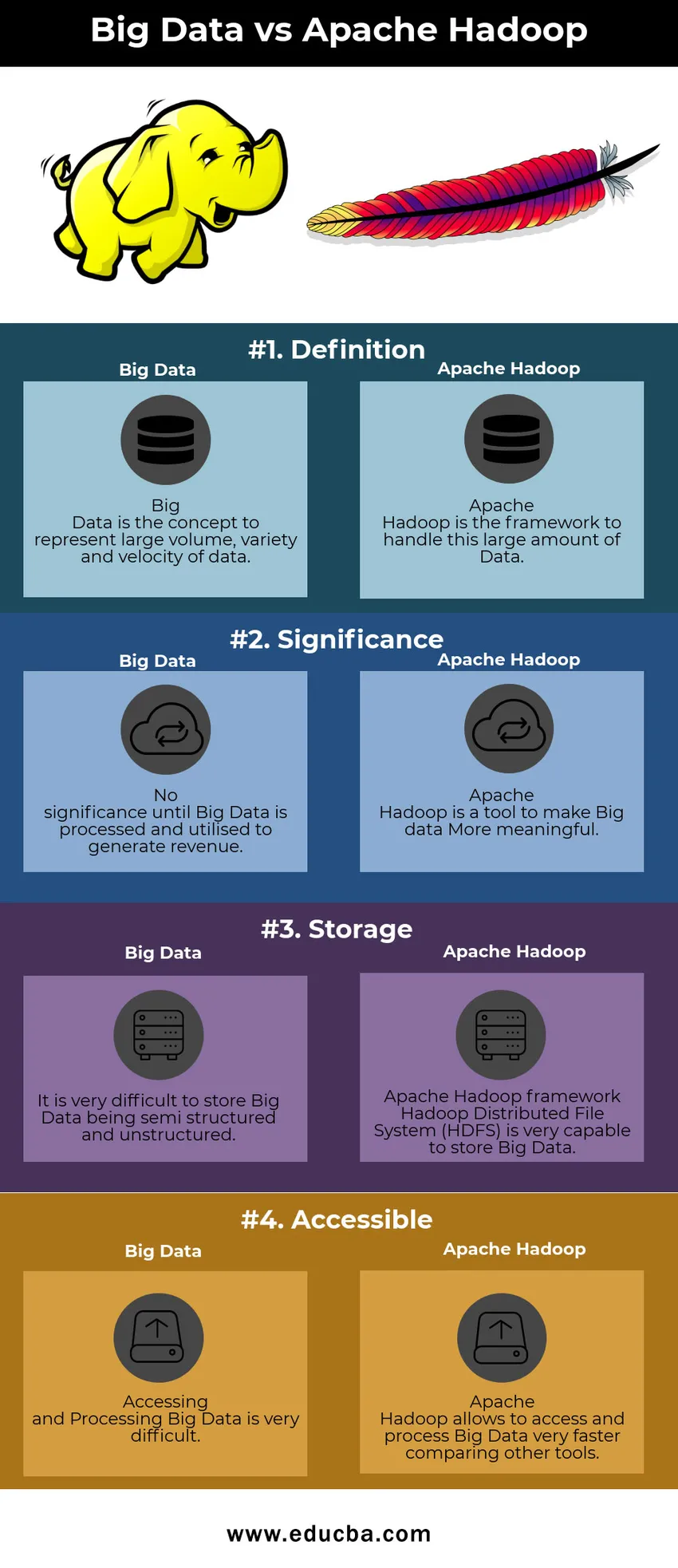
Big Data vs Apache Hadoop sammenligningstabell
Jeg diskuterer store gjenstander og skiller mellom Big Data vs Apache Hadoop
| Stor Data | Apache Hadoop | |
| Definisjon | Big Data er konseptet for å representere stort volum, variasjon og hastighet på data | Apache Hadoop er rammene for å håndtere denne store datamengden |
| Betydning | Ingen betydning før Big Data er behandlet og brukt til å generere inntekter | Apache Hadoop er et verktøy for å gjøre Big data mer meningsfylt |
| Oppbevaring | Det er veldig vanskelig å lagre Big Data som halvstrukturert og ustrukturert | Apache Hadoop-rammeverket Hadoop Distribuerte Filsystem (HDFS) er veldig i stand til å lagre Big Data |
| Tilgjengelig | Det er veldig vanskelig å få tilgang til og behandle Big Data | Apache Hadoop gir tilgang til og behandler Big Data veldig raskere sammenligning av andre verktøy |
Konklusjon - Big Data vs Apache Hadoop
Du kan ikke sammenligne Big Data og Apache Hadoop. Det er fordi Big Data er et problem mens Apache Hadoop er løsning. Siden datamengden øker eksponentielt i alle sektorene, så det er veldig vanskelig å lagre og behandle data fra et enkelt system. Så for å behandle denne store datamengden, trenger vi distribuert behandling og lagring av data. Derfor kommer Apache Hadoop på løsningen med å lagre og behandle en veldig stor datamengde. Til slutt vil jeg konkludere at Big Data er en stor mengde komplekse data, mens Apache Hadoop er en mekanisme for å lagre og behandle Big Data veldig effektivt og smidig.
Anbefalt artikkel
Dette har vært en guide til Big Data vs Apache Hadoop, deres betydning, sammenligning mellom hodet og hodet, viktige forskjeller, sammenligningstabell og konklusjon. denne artikkelen består av all nyttig forskjell mellom Big Data og Apache Hadoop. Du kan også se på følgende artikler for å lære mer -
- Big Data vs Data Science - Hvordan er de forskjellige?
- Topp 5 big data trender som selskaper vil måtte mestre
- Hadoop vs Apache Spark - Interessante ting du trenger å vite
- Apache Hadoop vs Apache Spark | Topp 10 sammenligninger du må vite!