

Oversikt over Data Mining Architecture
Data mining er måten å finne og utforske mønstrene grunnleggende eller avansert nivå i et komplisert sett med store datasett som involverer metodene plassert i skjæringspunktet mellom statistikk, maskinlæring og også databasesystemer. Det kan sies å være et tverrfaglig felt av statistikk og informatikk der målet er å trekke ut informasjonen ved hjelp av intelligente metoder og teknikker fra et bestemt datasett ved hjelp av utvinning og derved transformere dataene. Datahåndteringsaktiviteter og databehandlingsaktiviteter sammen med inferenshensyn blir også tatt i betraktning. I denne artikkelen vil vi dykke dypt inn i arkitekturen for data mining.
Data Mining Architecture
Data mining er teknikken for å hente ut interessant kunnskap fra et sett med enorme mengder data som deretter lagres i mange datakilder som filsystemer, datavarehus, databaser. De viktigste komponentene i databearbeidingsarkitekturen involverer -
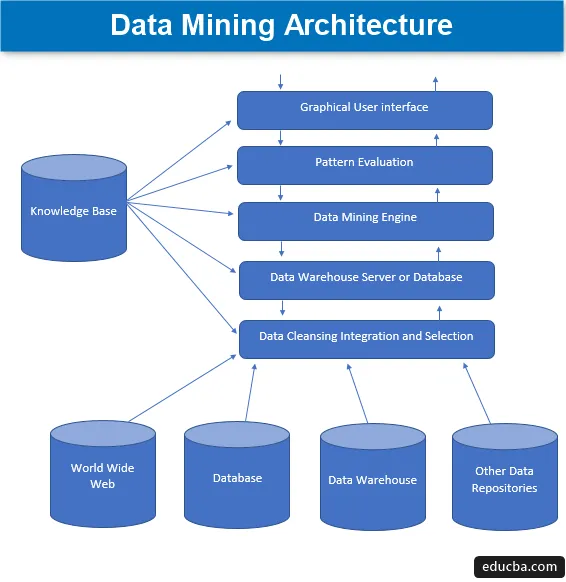
1. Datakilder
Et stort utvalg av nåværende dokumenter som datavarehus, database, www eller populært kalt en verdensweb som blir de faktiske datakildene. Oftest kan det også være slik at dataene ikke er til stede i noen av disse gyldne kildene, men bare i form av tekstfiler, vanlige filer eller sekvensfiler eller regneark, og da må dataene behandles i en veldig på samme måte som behandlingen ville bli gjort på data mottatt fra gyldne kilder. Det meste av det store antallet data i dag mottas fra internett eller world wide web, ettersom alt som finnes på internett i dag er data i en eller annen form som danner en form for informasjonslagringsenheter.
Før dataene blir behandlet fremover, involverer de forskjellige prosessene de går igjennom datarensing, integrering og valg før endelig dataene blir sendt videre til databasen eller noen av EDW-serverne (enterprise data warehouse). Den største utfordringen som til tider ligger med dette datasettet, er forskjellige nivåer av kilder og et bredt utvalg av dataformater som danner datakomponenter. Derfor kan ikke dataene brukes direkte til behandling i sin naive tilstand, men behandles, transformeres og lages på en mye mer brukbar måte. Slik sikres også påliteligheten og fullstendigheten av dataene. Så det primære trinnet involverer datainnsamling, rengjøring og integrering, og legg inn at bare de relevante dataene sendes videre. All denne aktiviteten utgjør en del av et eget sett med verktøy og teknikker.
2. Data Warehouse Server eller Database
Databaseserveren er det faktiske rommet der dataene er inneholdt når de er mottatt fra forskjellige antall datakilder. Serveren inneholder det faktiske settet med data som blir klar til å behandles, og derfor administrerer serveren datainnsamlingen. All denne aktiviteten er basert på forespørselen om data mining av personen.
3. Data Mining Engine
Når det gjelder data mining, utgjør motoren kjernekomponenten og er den viktigste delen, eller for å si den drivende kraften som håndterer alle forespørsler og administrerer dem og brukes til å inneholde et antall moduler. Antall tilstedeværende moduler inkluderer gruveoppgaver som klassifiseringsteknikk, assosiasjonsteknikk, regresjonsteknikk, karakterisering, prediksjon og klynging, tidsserieanalyse, naive Bayes, støttevektormaskiner, ensemblemetoder, boosting og bagging teknikker, tilfeldige skoger, beslutningstrær, etc.
4. Mønsterevalueringsmoduler
Denne evalueringsteknikken for modulene er hovedsakelig ansvarlig for å måle interessantheten til alle de mønstrene som blir brukt for å beregne det grunnleggende nivået av terskelverdien, og brukes også til å samhandle med data mining-motoren for å koordinere i evalueringen av andre moduler. Alt i alt er hovedformålet med denne komponenten å se opp og søke etter alle interessante og anvendelige mønstre som kan gjøre dataene av relativt bedre kvalitet.
5. Grafisk brukergrensesnitt
Når dataene kommuniseres med motorene og blant forskjellige mønsterevalueringer av moduler, blir det en nødvendighet å samhandle med de forskjellige komponentene som er til stede og gjøre dem mer brukervennlige slik at effektiv og effektiv bruk av alle de nåværende komponentene kan gjøres og derfor oppstår behovet for et grafisk brukergrensesnitt populært kjent som GUI.
Dette brukes til å etablere en følelse av kontakt mellom brukeren og data mining-systemet, og dermed hjelpe brukerne til å få tilgang til og bruke systemet effektivt og enkelt for å holde dem blottet for enhver kompleksitet som har oppstått i prosessen. Dette er en form for abstraksjon der bare de relevante komponentene vises for brukerne og alle kompleksitetene og funksjonalitetene som er ansvarlige for å bygge systemet er skjult for enkelhets skyld. Hver gang brukeren sender inn en forespørsel, samhandler modulen deretter med det samlede settet for et data mining-system for å produsere en relevant utgang som lett kan vises for brukeren på en mye mer forståelig måte.
6. Kunnskapsbase
Dette er komponenten som danner grunnlaget for den generelle data mining-prosessen, da den hjelper til med å lede søket eller i evalueringen av interessen til de dannede mønstrene. Denne kunnskapsbasen består av brukeroppfatninger og også data hentet fra brukeropplevelser som igjen er nyttige i data mining-prosessen. Motoren kan få sitt sett med innganger fra den opprettede kunnskapsbasen og gir dermed mer effektive, nøyaktige og pålitelige resultater.
Data mining er en av de viktigste teknikkene i dag som omhandler databehandling og databehandling som danner ryggraden i enhver organisasjon. Analyse av data i enhver organisasjon vil gi fruktbare resultater. Hver komponent i teknikken og arkitekturen for data mining har sin egen måte å utføre ansvar og også for å fullføre data mining effektivt. De forskjellige modulene er nødvendige for å samhandle riktig for å produsere et verdifullt resultat og fullføre den komplekse prosedyren for data mining, ved å gi riktig sett med informasjon til virksomheten.
Anbefalte artikler
Dette har vært en guide til Data Mining Architecture. Her diskuterer vi de primære komponentene i databearbeidingsarkitekturen. Du kan også gå gjennom andre foreslåtte artikler for å lære mer -
- Data Mining Tool
- Fordeler med data mining
- Hva er Clustering i datamining?
- HTML5 intervjuspørsmål og svar
- Mest brukte teknikker for læring av ensemble
- Algoritmer av modeller i datamining