

Introduksjon til RDBMS intervjuspørsmål og svar
Så hvis du forbereder deg til et jobbintervju i RDBMS. Jeg er sikker på at du vil vite de vanligste RDBMS-intervjuet i 2019 Spørsmål og svar som vil hjelpe deg med å knekke RDBMS-intervjuet med letthet. Nedenfor er listen over de beste RDBMS intervjuspørsmål og svar til unnsetning.
Derfor har vi en tendens til å legge til toppen 2019 RDBMS intervjuspørsmål som blir stilt mest i et intervju
1.Hva er forskjellige funksjoner i en RDBMS?
Svar:
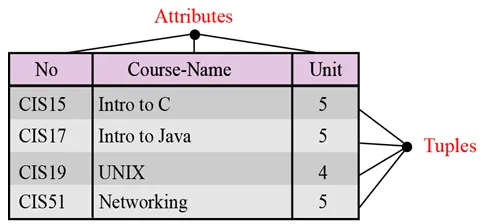
Navn. Hver relasjon i en relasjonsdatabase skal ha et navn som er unikt blant alle andre relasjoner.
Attributter. Hver kolonne i en relasjon kalles et attributt.
Tupler. Hver rad i en relasjon kalles en tuple. En tupel definerer en samling attributtverdier.
2.Forklar ER-modell?
Svar:
ER-modell er en enhet for forhold. ER-modellen er basert på en reell verden som består av enheter og relasjonsobjekter. Enheter er illustrert i en database med et sett attributter.
3. Definer objektorientert modell?
Svar:
Objektorientert modell er basert på samlinger av objekter. Et objekt rommer verdier som er lagret i forekomstvariabler inne i objektet. Objekter som har en identisk type verdier og nøyaktig de samme metodene er gruppert sammen i klasser.
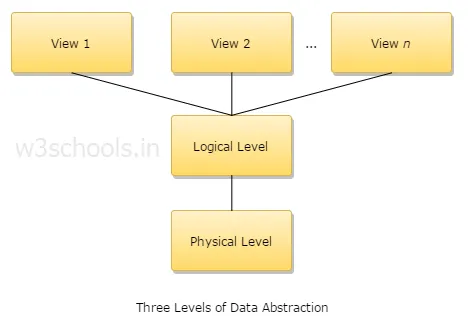
4. Forklar tre nivåer av datainnsamling?
Svar:
1. Fysisk nivå: Dette er det laveste abstraksjonsnivået, og det beskriver hvordan data lagres.
2. Logisk nivå: Det neste nivået av abstraksjon er logisk, det beskriver hvilken type data som er lagret i en database og hva som er forholdet mellom disse dataene.
3. Visningsnivå: Det høyeste abstraksjonsnivået, og det beskriver bare hele databasen.
 https://www.w3schools.in/dbms/data-schemas/
https://www.w3schools.in/dbms/data-schemas/
5.Hva er forskjellige Codds 12 regler for relasjonsdatabase?
Svar:
Codds 12 regler er et sett på tretten regler (nummerert null til tolv) foreslått av Edgar F. Codd.
Codds regler: -
Regel 0: Systemet må kvalifisere som relasjonelt, som en database, og også som et styringssystem.
Regel 1: Informasjonsregelen: Hver informasjon i databasen skal representeres unikt, hovedsakelig navnverdier i kolonneposisjoner i en annen rad i en tabell.
Regel 2: Den garanterte tilgangsregelen: Alle data må være inntrengende. Den sier at hver skalærverdi i databasen må være korrekt / logisk adresserbar.
Regel 3: Systematisk behandling av nullverdier: DBMS må la hver enkelt tupel forbli null.
Regel 4: Aktiv online katalog (databasens struktur) basert på den relasjonsmodellen: Systemet må støtte en online, relasjonell osv. Struktur som er inngripende for tillatte brukere ved hjelp av deres vanlige spørsmål.
Regel 5: Den omfattende datasettspråket: Systemet må hjelpe minst ett relasjonsspråk som:
1.Har en lineær syntaks
2.Den som kan brukes både interaktivt og i applikasjonsprogrammer,
3.It støtter datadefinisjonsoperasjoner (DDL), datamanipulasjonsoperasjoner (DML), sikkerhets- og integritetsbegrensninger og transaksjonsadministrasjonsoperasjoner (begynn, begå og tilbakeføring).
Regel 6: Visningsoppdateringsregelen: Alle visninger som teoretisk forbedrer, må oppgraderes av systemet.
Regel 7: Sett inn, oppdater og slett på høyt nivå: Systemet må støtte innsats, oppdatering og sletting av operatører.
Regel 8: Uavhengighet av fysisk data: Endre det fysiske nivået (hvordan dataene lagres, ved bruk av matriser eller koblede lister osv.) Må ikke kreve endring av et program.
Regel 9: Uavhengighet av logisk data: Endre det logiske nivået (tabeller, kolonner, rader osv.) Må ikke kreve endring av et program.
Regel 10: Integritetsuavhengighet: Integritetsbegrensninger må identifiseres individuelt fra applikasjonsprogrammer og lagres i katalogen.
Regel 11: Distribusjonsuavhengighet: Distribusjonen av deler av en database til forskjellige steder skal ikke være synlig for brukere av databasen.
Regel 12: Nonsubversjonsregelen: Hvis systemet gir et grensesnitt på lavt nivå (dvs. poster), kan ikke dette grensesnittet brukes til å undergrave systemet.
6.Hva er normalisering? og hva som forklarer forskjellige normaliseringsformer.
Svar:
Normalisering av databaser er en prosess for å organisere data for å minimere dataredundans. Noe som igjen sikrer datakonsistens. Det er mange problemer forbundet med dataredundans som diskplasssvinn, datainkonsekvens, DML-spørsmål (Data Manipulation Language) blir trege. Det er forskjellige normaliseringsformer: - 1NF, 2NF, 3NF, BCNF, 4NF, 5NF, ONF, DKNF.
1. 1NF: - Dataene i hver kolonne skal være atomenummer flere verdier atskilt med komma. Tabellen inneholder ingen repeterende kolonnegrupper. Identifiser hver post unikt ved å bruke den primære tasten.
2. 2NF: - Tabellen skal samsvare med alle betingelsene til 1NF og flytte overflødige data til separat tabell. Dessuten skaper det et forhold mellom disse tabellene ved bruk av utenlandske nøkler.
3. 3NF: - for et 3NF-bord skal oppfylle alle vilkårene for 1NF og 2NF. 3NF inneholder ikke attributter som er delvis avhengig av primærnøkkel.
7. Definer primærnøkkel, fremmednøkkel, kandidatnøkkel, supernøkkel?
Svar:
Primærnøkkel: Primærnøkkel er nøkkelen som ikke tillater dupliserte verdier og nullverdier. En primærnøkkel kan defineres på kolonnivå eller tabellnivå. Bare en primærnøkkel per tabell er tillatt.
Fremmednøkkel: fremmednøkkel tillater bare verdiene som er tilstede i den refererte kolonnen. Det tillater dupliserte eller nullverdier. Det kan defineres som kolonnivå eller tabellnivå. Den kan referere til en kolonne med en unik / primær nøkkel.
Kandidatnøkkel: En kandidatnøkkel er minimum supernøkkel, det er ingen ordentlig undergruppe av kandidatnøkkelattributter kan være en supernøkkel.
Supernøkkel : En supernøkkel er et sett med attributter for et relasjonsskjema som alle attributtene til skjemaet er delvis avhengige av. Ingen to rader kan ha samme verdi som supernøkkelattributter.
8.Hva er en annen type indekser?
Svar:
Indeksene er: -
Clustered index: - Det er indeksen som data lagres fysisk på disken. Derfor kan bare en gruppert indeks opprettes til en databasetabell.
Ikke-gruppert indeks: - Den definerer ikke fysiske data, men den definerer en logisk rekkefølge. Vanligvis opprettes B-tre eller B + tre for dette formålet.
9.Hva er fordelene med RDBMS?
Svar:
• Kontrollere redundans.
• Integritet kan håndheves.
• Inkonsekvens kan unngås.
• Data kan deles.
• Standard kan håndheves.
10.Navn noen undersystemer av RDBMS?
Svar:
Input-output, Security, Language Processing, Storage Management, Logging and Recovery, Distribution Control, Transaction Control, Memory Management.
11.Hva er Buffer Manager?
Svar:
Buffer Manager klarer å samle inn data fra disklagring til hovedminne og bestemme hvilke data som skal være i hurtigminnet for raskere behandling.
Anbefalt artikkel
Dette har vært en guide til Liste over RDBMS intervjuspørsmål og svar, slik at kandidaten enkelt kan slå sammen disse RDBMS intervjuspørsmål. Du kan også se på følgende artikler for å lære mer -
- De viktigste intervjuspørsmålene til Data Analytics
- 13 Fantastiske database testing intervju spørsmål og svar
- Topp 10 Designmønster Intervju Spørsmål og svar
- 5 Nyttige SSIS-intervjuspørsmål og svar