
Forskjellen mellom BFS VS DFS
Breadth-First Search (BFS) og Depth First Search (DFS) er to viktige algoritmer som brukes til å søke. Breadth-First Search starter søket fra den første noden og beveger seg deretter over nivåene som er nærmere rotnoden mens Dybde First Search-algoritmen starter med den første noden og deretter fullfører banen til sluttnoden til den respektive banen. Begge algoritmene går gjennom hver node under søket. Ulike koder er skrevet for de to algoritmene for å utføre prosessen med å krysse. De blir også sett på som viktige søkealgoritmer i kunstig intelligens.
I dette emnet skal vi lære om BFS VS DFS.
Hvordan fungerer BFS og DFS?
Arbeidsmekanismen til begge algoritmene blir forklart nedenfor med eksempler. Henvis til dem for en bedre forståelse av tilnærmingen som brukes.
Eksempel på bredde-første søk
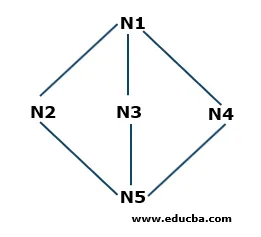
- Trinn 1: N1 er rotnoden, så den vil starte herfra. N1 er koblet til tre noder N2, N3 og N4. Alle tre nodene er ikke besøkt ennå. Så vi starter fra N2 og lagrer den i køen. Så køen som heter Q inneholder bare N2.
Q: N2
- Trinn 2: Neste node som er koblet til N1 er N3. Siden vi gikk over eller besøkte noden, vil vi lagre den i køen. Så den oppdaterte køen er
Q: N3, N2
- Trinn 3: Neste node som er koblet til rotnoden er N4. Vi vil lagre den i køen.
Q: N4, N3, N2
- Trinn 4: Alle nodene som er koblet til N1, lagres i køen. Nå fjerner vi N2 fra køen i henhold til First in First Out-prinsippet (FIFO) og finner noder som er koblet til N2 dvs. N5. N5 er ikke besøkt en gang, så vi vil lagre den i køen.
Q: N5, N4, N3
- Trinn 5: Alle toppunktene blir besøkt, så vi fortsetter å fjerne nodene fra køen til den er tom.
Eksempel på dybde første søk
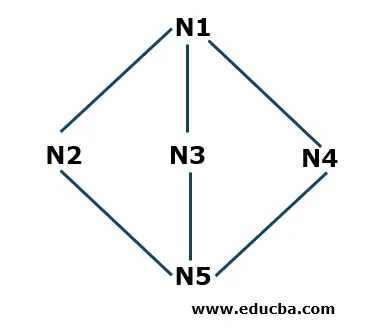
- Trinn 1: Vi starter med N1 som startnode og lagrer den i en stabel S. N1 er koblet til tre naboknuter N2, N3 og N4. Fra og med N2 (du kan starte alfabetisk eller numerisk), legger vi dette i bunken.
S: N2 (topp), N1
- Trinn 2: Nå, de nærliggende nodene til N2 er N1 og N5. Siden N1 allerede er til stede i bunken, betyr det at den blir besøkt, så vi tar N5 og legger den i bunken S.
S: N5 (topp), N2, N1
- Trinn 3: Nå, de nærliggende nodene til N5 er N3 og N4. Vi starter vil N3 og legger den i bunken.
S: N3 (topp), N5, N2, N1
Nå er N3 koblet til N5 og N1 som allerede er til stede i bunken som betyr at de blir besøkt, så vi vil fjerne N3 fra bunken i henhold til Last in First Out-prinsippet (LIFO) -prinsippet.
S: N5 (topp), N2, N1
- Trinn 4: Nå legger vi den siste noden som vi ikke kom over i hele krysset i N4 og la den i bunken.
S: N4 (topp), N5, N2, N1
- Trinn 5: Nå blir vi ikke utelatt med noen andre noder, så vi sjekker inn stabelen om det er noen noder koblet til de respektive noder som er til stede i den som ikke blir besøkt. Hvis alle de tilkoblede nodene blir besøkt, fjerner vi nodene som finnes i stabelen. For eksempel har N4 ingen tilkoblingsnoder som vi ikke sjekket, så vi vil fjerne den fra stabelen. På samme måte kan vi se etter andre noder. Algoritmen stopper når stabelen er tom.
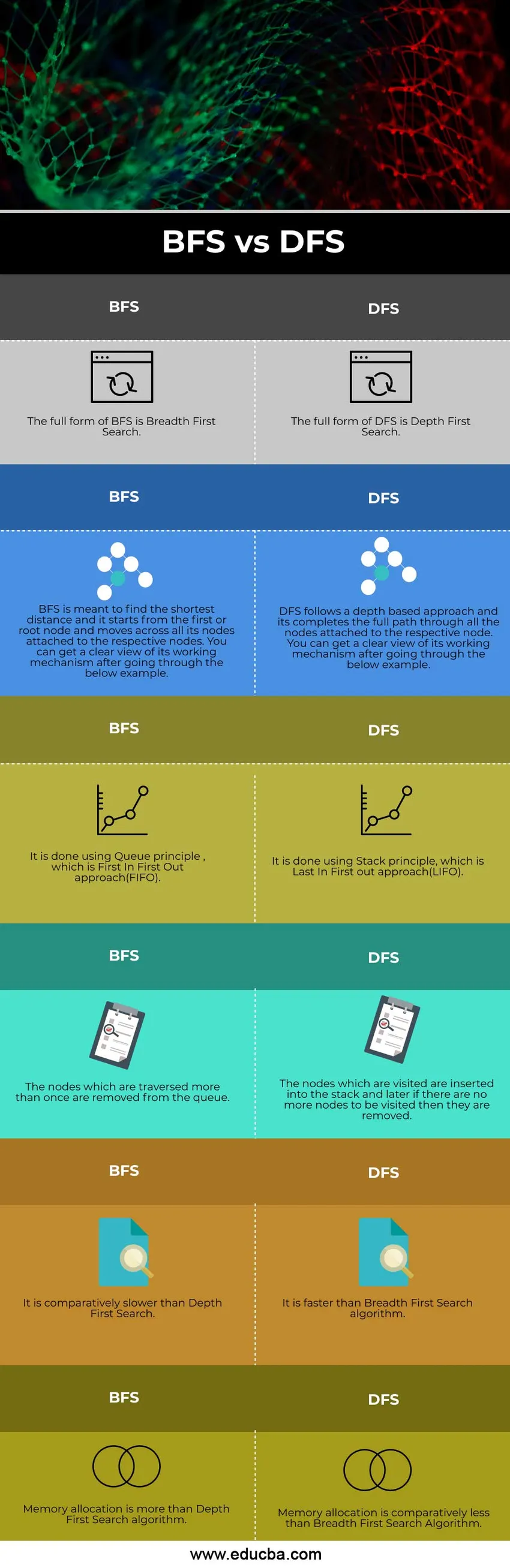
Sammenligning fra topp til hodet mellom BFS VS DFS (Infographics)
Nedenfor er de topp 6 forskjellene mellom BFS VS DFS
Viktige forskjeller mellom BFS og DFS
La oss diskutere noen av de viktigste viktige forskjellene mellom BFS vs DFS
- Breadth-First Search (BFS) starter fra rotnoden og besøker alle respektive noder som er knyttet til den, mens DFS starter fra rotnoden og fullfører hele banen som er knyttet til noden.
- BFS følger tilnærmingen til Queue mens DFS følger tilnærmingen til Stack.
- Tilnærmingen som brukes i BFS er optimal, mens prosessen som brukes i DFS ikke er optimal.
- Hvis vårt mål er å finne den korteste veien, er BFS å foretrekke fremfor DFS.
Sammenligningstabell for BFS og DFS
La oss diskutere topp sammenligningen mellom BFS vs DFS
| BFS | DFS |
| Den fullstendige formen for BFS er Breadth-First Search. | Den fullstendige formen for DFS er Depth First Search |
| BFS er ment å finne den korteste avstanden, og den starter fra den første eller rotnoden og beveger seg over alle noder som er festet til de respektive nodene. Du kan få et oversikt over arbeidsmekanismen etter å ha gått gjennom eksemplet nedenfor. | DFS følger en dybdebasert tilnærming og den fullfører hele banen gjennom alle nodene festet til den respektive noden. Du kan få et oversikt over arbeidsmekanismen etter å ha gått gjennom eksemplet nedenfor. |
| Det gjøres ved hjelp av Queue-prinsippet, som er First In First Out-tilnærmingen (FIFO). | Det gjøres ved å bruke Stack-prinsippet, som er Last In First out-tilnærmingen (LIFO). |
| Knutepunktene som krysses mer enn en gang, fjernes fra køen. | Knutepunktene som blir besøkt settes inn i stabelen, og hvis det ikke er flere noder som skal besøkes, fjernes de senere. |
| Det er relativt tregere enn Depth First Search. | Det er raskere enn Breadth-First Search-algoritmen. |
| Minnetildeling er mer enn Deepth First Search-algoritmen. | Minneallokering er relativt mindre enn bredde-første søkealgoritmen |
Konklusjon
Det er mange applikasjoner der de ovennevnte algoritmene brukes som maskinlæring eller for å finne kunstige intelligensrelaterte løsninger osv. De brukes hovedsakelig i grafer for å finne om det er bipartitt eller ikke, for å oppdage sykluser eller komponenter som er tilkoblet. De blir også sett på som viktige algoritmer for å finne banen eller for å finne den korteste avstanden. Avhengig av kravene til virksomheten, kan vi bruke to algoritmer. Imidlertid anses Breadth-First Search for å være en optimal måte i stedet for Deepth First Search-algoritmen.
Anbefalte artikler
Dette er en guide til BFS VS DFS. Her diskuterer vi BFS VS DFS viktige forskjeller med infografikk og sammenligningstabell. Du kan også se på følgende artikler for å lære mer -
- BFS-algoritme
- TeraData vs Oracle
- Big Data vs Data Warehouse
- Big Data vs Apache Hadoop: Topp 4 sammenligning du må lære