
Introduksjon til ensembleteknikker
Ensemble learning er en teknikk i maskinlæring som tar hjelp av flere basismodeller og kombinerer deres utdata for å produsere en optimalisert modell. Denne typen maskinlæringsalgoritmer hjelper til med å forbedre den generelle ytelsen til modellen. Her er basismodellen som er mest brukt, beslutnings treklassifiseringen. Et beslutnings tre fungerer i utgangspunktet etter flere regler og gir en prediktiv utgang, der reglene er knutepunktene og deres beslutninger vil være deres barn og bladknutene vil utgjøre den endelige beslutningen. Som vist i eksemplet på et avgjørelsestre.
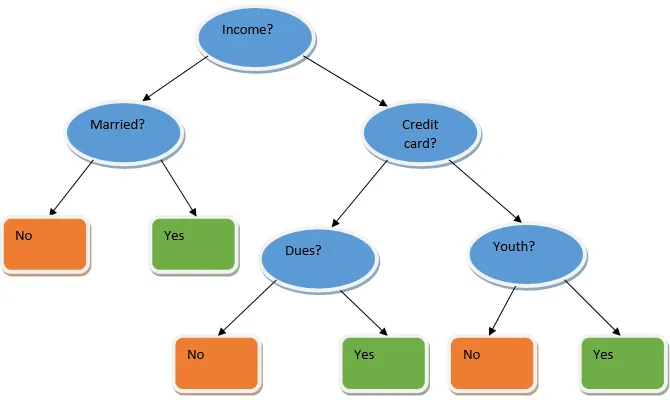
Ovennevnte beslutnings tre snakker i utgangspunktet om hvorvidt en person / kunde kan få et lån eller ikke. En av reglene for låneberettigelse ja er at hvis (inntekt = Ja && Gift = Nei) Da lån = Ja, så dette er hvordan en avgjørelse tre klassifiserer fungerer. Vi vil innlemme disse klassifiseringene som en modell med flere baser og kombinere utdataene for å bygge en optimal prediktiv modell. Figur 1.b viser helhetsbildet av en ensemble-læringsalgoritme.
Typer ensembles teknikker
Ulike typer ensembler, men hovedfokuset vårt vil være på de to følgende typene:
- bagging
- Styrking
Disse metodene hjelper til med å redusere variansen og skjevheten i en maskinlæringsmodell. La oss prøve å forstå hva som er skjevhet og varians. Bias er en feil som oppstår på grunn av uriktige forutsetninger i algoritmen vår; en høy skjevhet indikerer at modellen vår er for enkel / underfit. Varians er feilen som skyldes modellens følsomhet for svært små svingninger i datasettet; en høy varians indikerer at modellen vår er svært kompleks / overfit. En ideell ML-modell skal ha en riktig balanse mellom skjevhet og varians.
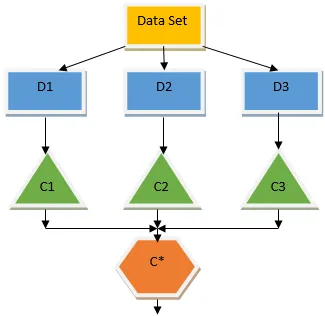
Bootstrap Aggregating / Bagging
Bagging er en ensembleteknikk som hjelper til med å redusere variansen i modellen vår og dermed unngår overmontering. Bagging er et eksempel på den parallelle læringsalgoritmen. Bagging fungerer basert på to prinsipper.
- Bootstrapping: Fra det originale datasettet blir forskjellige utvalgspopulasjoner vurdert som erstatning.
- Aggregering: Gjennomsnitt av resultatene fra alle klassifiserere og gi enkel utgang, for dette bruker den flertallstemme når det gjelder klassifisering og gjennomsnitt i tilfelle regresjonsproblemet. En av de berømte maskinlæringsalgoritmene som bruker begrepet bagging er en tilfeldig skog.
Tilfeldig skog
I tilfeldig skog fra den tilfeldige prøven trukket fra befolkningen med erstatning, og en undergruppe av funksjoner velges fra settet med alle funksjonene et beslutnings tre er bygget. Fra disse undergruppene med funksjoner, hvilken funksjon som gir best splitt, velges som roten til beslutnings-treet. Funksjonens undergruppe må velges tilfeldig for enhver pris, ellers vil vi ende opp med å produsere bare korrelert lokk og variansen til modellen blir ikke forbedret.
Nå har vi bygget modellen vår med prøvene tatt fra populasjonen, spørsmålet er hvordan validerer vi modellen? Siden vi vurderer prøvene med erstatning, og derfor vil ikke alle prøvene bli vurdert, og noe av det vil ikke bli inkludert i noen pose. Disse kalles for poseprøver. Vi kan validere modellen vår med denne OOB-prøven. De viktige parametrene som skal vurderes i en tilfeldig skog er antall prøver og antall trær. La oss betrakte 'm' som delmengde av funksjoner, og 'p' er det komplette settet med funksjoner, nå som en tommelfingerregel, er det alltid ideelt å velge
- m as√ og en minimum nodestørrelse som 1 for et klassifiseringsproblem.
- m som P / 3 og minimum nodestørrelse til å være 5 for et regresjonsproblem.
M og p bør behandles som innstillingsparametere når vi håndterer et praktisk problem. Treningen kan avsluttes når OOB-feilen stabiliseres. En ulempe med den tilfeldige skogen er at når vi har 100 funksjoner i datasettet vårt og bare et par funksjoner er viktig, vil denne algoritmen fungere dårlig.
Styrking
Boosting er en sekvensiell læringsalgoritme som hjelper med å redusere skjevhet i vår modell og varians i noen tilfeller av veiledet læring. Det hjelper også med å konvertere svake elever til sterke elever. Boosting fungerer etter prinsippet om å plassere de svake elevene i rekkefølge, og det tillegger en vekt til hvert datapunkt etter hver runde; mer vekt tillegges det feilklassifiserte datapunktet i forrige runde. Denne sekvensiell vektede metoden for å trene datasettet vårt er nøkkelforskjellen til bagging.
Fig3.a viser den generelle tilnærmingen i boosting
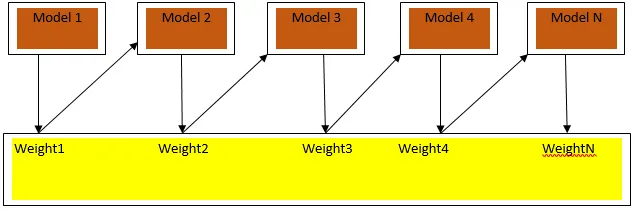
De endelige prediksjonene er kombinert basert på vektet flertall ved klassifisering og vektet sum i tilfelle regresjon. Den mest brukte boostingalgoritmen er adaptiv boosting (Adaboost).
Adaptiv boosting
Trinnene som er involvert i Adaboost-algoritmen er som følger:
- For de gitte n datapunktene definerer vi målgruppen og initialiserer alle vektene til 1 / n.
- Vi passer klassifisatorene til datasettet, og vi velger klassifiseringen med den minst vektede klassifiseringsfeilen
- Vi tildeler vekter for klassifiseringen ved hjelp av en tommelfingerregel basert på nøyaktighet, hvis nøyaktigheten er mer enn 50% så er vekten positiv og omvendt.
- Vi oppdaterer vekten til klassifisatorene på slutten av iterasjonen; oppdaterer vi mer vekt for det feilklassifiserte punktet, slik at vi i neste iterasjon klassifiserer det riktig.
- Etter all iterasjonen får vi det endelige prediksjonsresultatet basert på flertallets stemme / vektet gjennomsnitt.
Adaboosting jobber effektivt med svake (mindre komplekse) elever og med klassiske klassifiserere med høy skjevhet. De største fordelene med Adaboosting er at det er raskt, det er ingen innstillingsparametere som ligner på tilfelle av bagging, og vi gjør ikke noen forutsetninger for svake elever. Denne teknikken klarer ikke å gi et nøyaktig resultat når
- Det er flere outliers i våre data.
- Datasettet er utilstrekkelig.
- De svake elevene er svært sammensatte.
De er også utsatt for støy. Avgjørelsetrærne som produseres som et resultat av forsterkning vil ha begrenset dybde og høy nøyaktighet.
Konklusjon
Ensemble læringsteknikker er mye brukt for å forbedre modellens nøyaktighet; vi må bestemme hvilken teknikk vi skal bruke basert på datasettet. Men disse teknikkene foretrekkes ikke i noen tilfeller der tolkbarhet er viktig, da vi mister tolkbarhet på bekostning av ytelsesforbedring. Disse har enorm betydning i helsevesenet der en liten forbedring av ytelsen er svært verdifull.
Anbefalte artikler
Dette er en guide til Ensemble Techniques. Her diskuterer vi introduksjonen og to hovedtyper av ensembleteknikker. Du kan også gå gjennom andre relaterte artikler for å lære mer-
- Steganografiteknikker
- Maskinlæringsteknikker
- Lagbyggingsteknikker
- Data Science algoritmer
- Mest brukte teknikker for læring av ensemble