
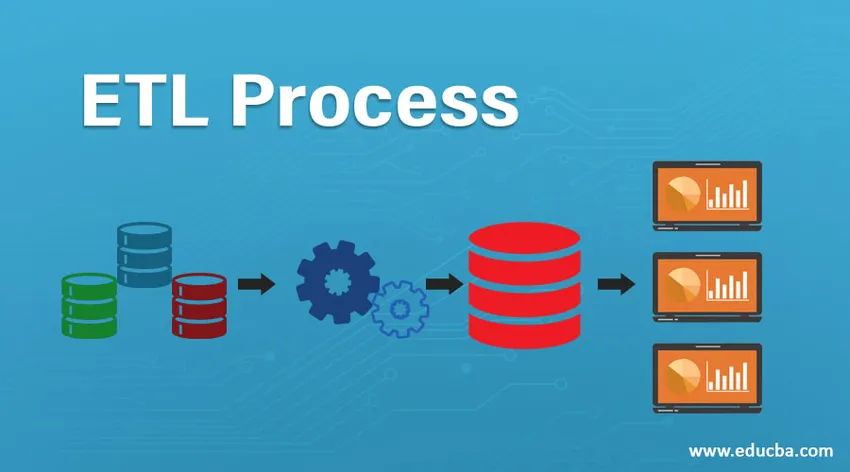
Introduksjon av ETL-prosessen
ETL er en av de viktige prosessene som kreves av Business Intelligence. Business Intelligence er avhengig av dataene som er lagret i datavarehus hvor mange analyser og rapporter blir generert som hjelper til med å bygge mer effektive strategier og fører til taktiske og operasjonelle innsikter og beslutninger.
ETL viser til Extract, Transform and Load prosessen. Det er et slags dataintegrasjonstrinn der data som kommer fra forskjellige kilder blir hentet ut og sendt til datavarehus. Data utvinnes fra forskjellige ressurser og blir først transformert for å konvertere dem til et spesifikt format i henhold til forretningskrav. Ulike verktøy som hjelper til med å utføre disse oppgavene er -
- IBM DataStage
- Abinitio
- Informatica
- Tableau
- Talend
ETL-prosess
Hvordan virker det?
ETL-prosessen er en 3-trinns prosess som starter med å trekke ut dataene fra forskjellige datakilder og deretter gjennomgår rå data forskjellige transformasjoner for å gjøre dem egnet for lagring i datavarehus og laste dem inn i datavarehus i ønsket format og gjøre den klar for analyse.
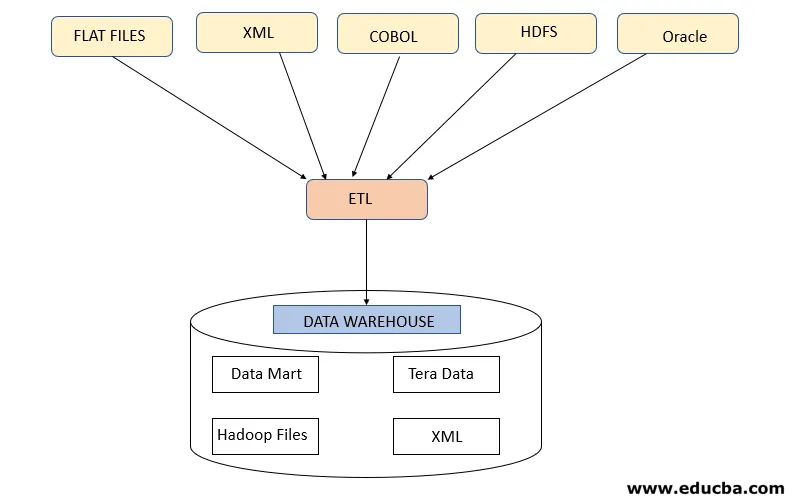
Trinn 1: Pakk ut
Dette trinnet refererer til å hente de nødvendige dataene fra forskjellige kilder som er til stede i forskjellige formater som XML, Hadoop-filer, Flat Files, JSON, etc. De ekstraherte dataene er lagret i iscenesettelsesområdet der ytterligere transformasjoner blir utført. Dermed blir data sjekket grundig før de flyttes til datavarehus ellers vil det bli en utfordring å tilbakestille endringene i datavarehus.
Det kreves et riktig datakart mellom kilde og mål før datautvinning skjer, ettersom ETL-prosessen trenger å samhandle med forskjellige systemer som Oracle, Hardware, Mainframe, sanntidssystemer som ATM, Hadoop, etc. mens henting av data fra disse systemene .
Merk - Men man må passe på at disse systemene må forbli upåvirket under utvinning.
Strategier for utvinning av data
- Full utvinning: Dette følges når hele data fra kilder blir lastet inn i datavarehusene som viser at enten datavarehus blir befolket første gang eller det ikke er laget noen strategi for datautvinning.
- Delvis utvinning (med oppdateringsvarsel): Denne strategien er også kjent delta, der bare dataene som endres blir hentet ut og oppdatere datavarehus
- Delvis utvinning (uten varsel om oppdatering): Denne strategien refererer til å trekke ut spesifikke nødvendige data fra kilder i henhold til belastning i datavarehusene i stedet for å trekke ut hele data.
Trinn 2: Transformer
Dette trinnet er det viktigste trinnet til ETL. I dette trinnet utføres mange transformasjoner for å gjøre data klare for lasting i datavarehus ved å bruke transformasjoner nedenfor:
A. Grunnleggende transformasjoner: Disse transformasjonene brukes i alle scenarier ettersom de er grunnleggende behov mens du laster inn dataene som er hentet fra forskjellige kilder, i datavarehusene
- Rengjøring eller berikning av data: Det refererer til rengjøring av uønskede data fra iscenesettelsesområdet slik at feil data ikke blir lastet inn fra datavarehusene.
- Filtrering: Her filtrerer vi ut nødvendige data fra en stor mengde data som er til stede i henhold til forretningskrav. For å generere salgsrapporter trenger man for eksempel bare salgsoppføringer for det aktuelle året.
- Konsolidering: Utpakket data blir samlet i ønsket format før de lastes inn i datavarehusene.4.
- Standardiseringer: Datafelt transformeres for å bringe det i samme påkrevde format for f.eks. Datafeltet må spesifiseres som MM / DD / ÅÅÅÅ.
B. Avanserte transformasjoner: Disse typer transformasjoner er spesifikke for virksomhetens krav.
- Bli med: I denne operasjonen kombineres data fra to eller flere kilder t genererer data med bare ønskede kolonner med rader som er relatert til hverandre
- Valideringskontroll av dataterskel: Verdier som er til stede i forskjellige felt blir sjekket om de er korrekte eller ikke, for eksempel ikke null bankkontonummer i tilfelle bankdata.
- Bruk oppslag for å slå sammen data: Ulike flate filer eller andre filer brukes til å trekke ut den spesifikke informasjonen ved å utføre oppslagshandling på den.
- Bruker hvilken som helst kompleks datavalidering: Mange komplekse valideringer brukes for å trekke ut gyldige data bare fra kildesystemene.
- Beregnede og avledede verdier: Ulike beregninger brukes for å transformere dataene til litt nødvendig informasjon
- Duplisering: Dupliserte data som kommer fra kildesystemene blir analysert og fjernet før de lastes inn i datavarehusene.
- Nøkkelomlegging: Ved innhenting av sakte skiftende data, må det genereres forskjellige surrogatnøkler for å strukturere dataene i ønsket format.
Merk - MPP-Massive Parallel Processing brukes noen ganger for å utføre noen grunnleggende operasjoner som filtrering eller rensing av data i iscenesettelsesområdet for å behandle en stor datamengde raskere.
Trinn 3: Last inn
Dette trinnet refererer til å laste de transformerte dataene inn i datavarehuset hvor de kan brukes til å generere mange analysebeslutninger samt rapportering.
1. Innledende belastning: Denne typen belastning oppstår mens du laster inn data i datavarehus for første gang.
2. Trinnvis belastning: Dette er den typen belastning som gjøres for å oppdatere datavarehuset med jevne mellomrom med endringer som skjer i kildesystemdata.
3. Full Refresh: Denne typen belastning refererer til situasjonen når komplette data i tabellen blir slettet og lastet med ferske data.
Datavarehuset tillater da OLAP- eller OLTP-funksjoner.
Ulemper ved ETL-prosessen
- Øke data - Det er en grense for data som blir hentet fra forskjellige kilder av ETL-verktøyet og skyvet til datavarehus. Med økningen av data blir det derfor tungvint å jobbe med ETL-verktøyet og datavarehusene.
- Tilpasning - Dette refererer til de raske og effektive løsningene eller svarene på dataene som genereres av kildesystemer. Men å bruke ETL-verktøyet her bremser denne prosessen.
- Dyrt - Å bruke et datavarehus for å lagre en økende mengde data som genereres med jevne mellomrom er en høy kostnad en organisasjon trenger å betale.
Konklusjon - ETL-prosess
ETL-verktøyet består av pakke-, transformasjons- og lastprosesser der det hjelper til med å generere informasjon fra dataene samlet inn fra forskjellige kildesystemer. Dataene fra kildesystemet kan komme i alle formater og kan lastes i hvilket som helst ønsket format i datavarehus, og ETL-verktøyet må derfor støtte tilkobling til alle typer av disse formatene.
Anbefalte artikler
Dette er en guide til en ETL-prosess. Her diskuterer vi introduksjonen, Hvordan fungerer det ?, ETL-verktøy og ulemper. Du kan også gå gjennom de andre foreslåtte artiklene våre for å lære mer–
- Informatica ETL-verktøy
- ETL-testverktøy
- Hva er ETL?
- Hva er ETL-testing?