

Oversikt over typer Clustering
La oss forstå hva som er Clustering i forkant av læringstyper, og hvorfor er det så viktig i maskinlæringsbransjen akkurat nå.
Hva er Clustering? Clustering er en prosess der algoritmen deler datapunktene i et angitt antall grupper basert på prinsippet om at lignende datapunkter holder seg nær hverandre og de faller inn i den samme gruppen.
Hvorfor er det så viktig nå? La oss forstå at ved å se et eksempel, for eksempel, det er en online klesbutikk, og de ønsker å forstå kundene sine bedre, slik at de kan gjøre annonseringsstrategien mer effektiv. Det er ikke mulig for dem å ha en unik type strategi for hver kunde, i stedet for dette hva de kan gjøre er å dele opp kundene i et visst antall grupper (basert på tidligere kjøp) og ha en egen strategi for separate grupper. Dette gjør virksomheten mer effektiv, dette er grunnen til at klynging er viktig i bransjen nå.
Typer Clustering
Stort sett er metoder for klyngeteknikker klassifisert i to typer, de er harde metoder og myke metoder. I Hard clustering-metoden tilhører hvert datapunkt eller observasjon bare en klynge. I den myke klyngemetoden vil hvert datapunkt ikke helt tilhøre en klynge, i stedet kan det være medlem av mer enn ett klynge, det har et sett med medlemskapskoeffisienter som tilsvarer sannsynligheten for å være i en gitt klynge.
Foreløpig er det forskjellige typer klyngemetoder som er i bruk. La oss i denne artikkelen se noen av de viktige som hierarkisk klynging, Partisjonering av klynger, Fuzzy clustering, Density-basert clustering og Distribusjonsmodellbasert clustering. La oss nå diskutere hver enkelt av disse med et eksempel:
1. Partisjonering Clustering
Partisjonering Clustering er en type klyngeteknikk som deler datasettet inn i et sett antall grupper. (For eksempel verdien av K i KNN, og den vil bli bestemt før vi trener modellen). Det kan også kalles en centroid-basert metode. I denne tilnærmingen dannes klyngesenter (centroid) slik at avstanden til datapunkter i den klyngen er minimal når den beregnes med andre klyngesentroider. Et mest populært eksempel på denne algoritmen er KNN-algoritmen. Slik ser en partisjoneringsgruppe-algoritme ut
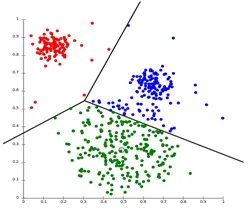
2. Hierarkisk klynging
Hierarkisk klynging er en type klyngeteknikk, som deler datasettet inn i et antall klynger, der brukeren ikke spesifiserer antall klynger som skal genereres før han trener modellen. Denne typen klyngeteknikker er også kjent som tilkoblingsbaserte metoder. I denne metoden blir ikke enkel partisjonering av datasettet ikke gjort, mens det gir oss hierarkiet til klyngene som fusjonerer med hverandre etter en viss avstand. Etter at den hierarkiske klyngen er utført på datasettet, blir resultatet en trebasert representasjon av datapunkter (Dendogram), som er delt inn i klynger. Slik ser en hierarkisk klynging ut etter trening
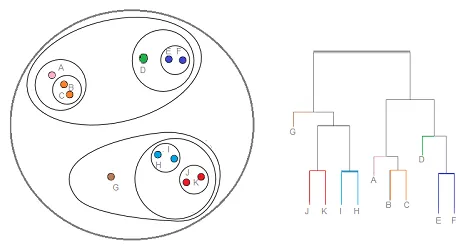
Kildelink: Hierarkisk klynging
I partisjonering av klynger og hierarkisk klynger, er en hovedforskjell vi kan legge merke til i partisjonering av klynger, vi vil forhåndsdefinere verdien av hvor mange klynger vi vil at datasettet skal deles inn i, og vi forhånds spesifiserer ikke denne verdien i hierarkisk klynge .
3. Tetthetsbasert klynging
I denne klyngen vil teknikk klynger dannes ved segregering av forskjellige tetthetsregioner basert på forskjellige tettheter i dataplanen. Density-Based Spatial Clustering and Application with Noise (DBSCAN) er den mest brukte algoritmen i denne typen teknikker. Hovedideen bak denne algoritmen er at det bør være et minimum antall poeng som inneholder i nærheten av en gitt radius for hvert punkt i klyngen. Så langt i ovennevnte klyngeteknikker, hvis du observerer grundig, kan vi merke en vanlig ting i alle teknikkene som er formen på dannede klynger, er enten sfæriske eller ovale eller konkave formede. DBSCAN kan danne klynger i forskjellige former, denne typen algoritmer er best egnet når datasettet inneholder støy eller outliers. Slik ser en tetthetsbasert romlig klynge-algoritme ut etter trening.
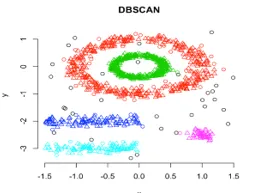
Kildelink: Tetthetsbasert klynge
4. Distribusjonsmodellbasert klynging
I denne typen klynger dannes teknikk klynger ved å identifisere med sannsynligheten for at alle datapunktene i klyngen kommer fra samme distribusjon (Normal, Gaussian). Den mest populære algoritmen i denne typen teknikker er gruppering av forventning-maksimering (EM) ved bruk av Gaussian Mixture Models (GMM).
Normale klyngeteknikker som hierarkisk klynging og partisjonering klynging er ikke basert på formelle modeller, KNN ved partisjonering av klynger gir forskjellige resultater med forskjellige K-verdier. Som KNN og KMN anser som betydningsfulle for klyngesenteret, er det ikke best egnet i noen tilfeller med gaussiske blandingsmodeller antar vi at datapunkter er gaussisk fordelt, på denne måten har vi to parametere for å beskrive formen på klyngemidlet og standardavviket. På denne måten tilordnes en Gauss-distribusjon for hver klynge, for å få de optimale verdiene for disse parametrene (gjennomsnitt og standardavvik), brukes en optimaliseringsalgoritme kalt Expectation Maximization. Slik ser EM - GMM ut etter trening.
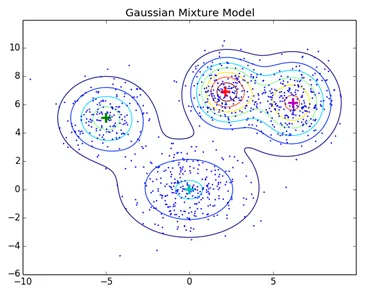
Kildelink: Distribusjonsmodellbasert Clustering
5. Fuzzy Clustering
Tilhører en gren av klyngeteknikker for myke metoder, mens alle ovennevnte klyngeteknikker tilhører hardmetodisk klyngeteknikker. I denne typen klyngeteknikker peker nær sentrum, kanskje en del av den andre klyngen i høyere grad enn punkter i kanten av den samme klyngen. Sannsynligheten for et punkt som tilhører en gitt klynge, er en verdi som ligger mellom 0 til 1. Den mest populære algoritmen i denne typen teknikk er FCM (Fuzzy C-betyr algoritme). Her beregnes centroid av en klynge som middelverdien av alle punkter, vektet av deres sannsynlighet for å tilhøre klyngen.
Konklusjon - Typer Clustering
Dette er noen av de forskjellige klyngeteknikkene som for tiden er i bruk, og i denne artikkelen har vi dekket en populær algoritme i hver klyngeteknikk. Vi må velge hvilken type teknologi vi bruker, basert på datasettet og kravene vi trenger å oppfylle.
Anbefalte artikler
Dette har vært en guide til typer Clustering. Her diskuterer vi forskjellige typer klynger med deres eksempler. Du kan også se på følgende artikler for å lære mer -
- Hierarkisk Clustering Algorithm
- Clustering in Machine Learning
- Typer maskinlæringsalgoritmer
- Typer av dataanalyseteknikker
- Hvordan bruke og fjerne hierarki i Tableau?
- Komplett guide til typer dataanalyse