

Splunk Intervju Spørsmål og svar - Introduksjon
Så du har endelig funnet drømmejobben din i Splunk, men lurer på hvordan du kan knekke Splunk-intervjuet, og hva som kan være de sannsynlige Splunk-intervjuspørsmålene for 2018. Hvert intervju er forskjellig, og omfanget av en jobb er også annerledes. Med dette i bakhodet har vi designet de vanligste spørsmålene og svarene om Splunk-intervju for 2018 for å hjelpe deg med å få suksess i intervjuet.Nedenfor er de mest nyttige Splunk Interview Questions and Answer. Disse toppspørsmålene er delt inn i to deler er som følger:
Del 1 - Splunk Interview Interview (Basic)
Denne første delen dekker grunnleggende Splunk-intervjuspørsmål og svar.
1. Hva er Splunk? Hvorfor brukes Splunk for å analysere maskindata?
Svar:
Et av de mest brukte analyseverktøyene der ute er Microsoft Excel, og ulempen med det er at Excel bare kan laste opp til 1048576 rader og maskindataene er generelt store. Splunk er praktisk når det gjelder å håndtere maskingenererte data (big data), dataene fra servere, enheter eller nettverk kan enkelt lastes inn i Splunk og kan analyseres for å sjekke om trussel er synlig, overholdelse, sikkerhet osv., Det kan også brukes for applikasjonsovervåking.
2. Forklar hvordan Splunk fungerer
Svar:
Dette er de vanlige Splunk-intervjuspørsmålene som stilles i et intervju. Data lastes inn i Splunk ved hjelp av speditøren som fungerer som et grensesnitt mellom Splunk-miljøet og omverdenen, deretter blir disse dataene videresendt til en indekser hvor dataene enten lagres lokalt eller på en sky. Indeksøren indekserer maskindataene og lagrer dem på serveren. Search Head er GUI som leveres av Splunk for å søke og analysere (søker, visualiserer, analyserer og utfører forskjellige andre funksjoner) dataene.
Distribusjonsserver administrerer alle komponentene i Splunk som indekser, speditør og søkehode i Splunk-miljøet. 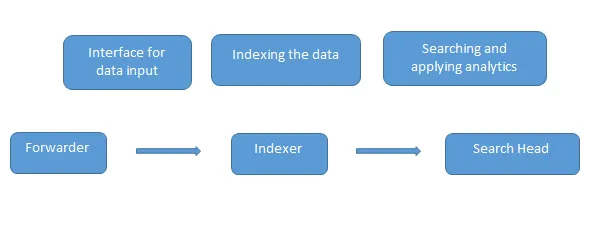
3. Hva er vanlige portnumre brukt av Splunk?
Svar :
Vanlige portnumre som tjenester kjøres til (som standard) er:
| Service | Portnummer |
| Management / REST API | 8089 |
| Søkehode / indekser | 8000 |
| Søk på hodet | 8065, 8191 |
| Indexer cluster peer node / Search head cluster member | 9887 |
| Indexer | 9997 |
| Indexer / Transportør | 514 |
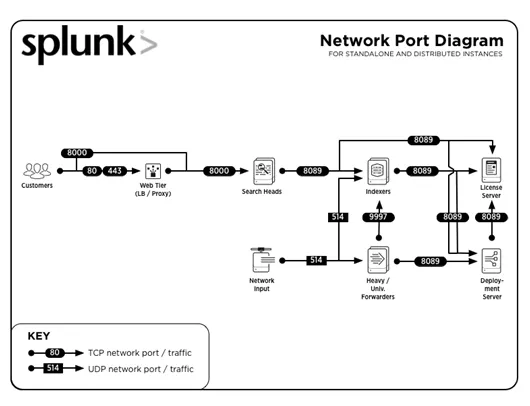
La oss gå til de neste spørsmålene om Splunk-intervju.
4. Hvorfor bare bruke Splunk?
Svar:
Det er mange alternativer for Splunk som gir mye konkurranse om det. Noen av dem er som nedenfor:
• ELK / Logstash (åpen kildekode)
Elasticsearch brukes til å søke, det er som søkehodet i Splunk, Log stash er for datainnsamling som ligner på speditøren som brukes i Splunk, og Kibana brukes til datavisualisering (søkehodet gjør det samme i Splunk)
• Graylog (åpen kildekode med kommersiell versjon)
Graylog er enda et verktøy som ble navnet i fjor med lanseringen 1.0. I likhet med ELK-stacken har Graylog også forskjellige komponenter den bruker Elasticsearch som sin kjernekomponent, men dataene lagres i Mongo DB og bruker Apache Kafka. Den har to versjoner, en kjerneversjon som er tilgjengelig gratis og bedriftsversjonen som kommer med funksjoner som arkivering.
• Sumo Logic (skytjeneste)
Så det som gjør Splunk best blant alle, er at Splunk kommer som en enkelt pakke med datainnsamleren, lagring og analyseverktøyet som er innebygd. Splunk er også skalerbar og gir støtte / profesjonell hjelp til sin bedriftsutgave.
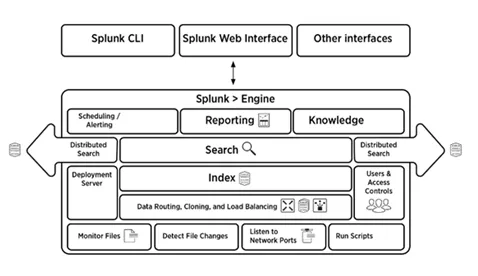
5. Forklar kortfattet arkitektur
Svar:
Bildet nedenfor gir en kort oversikt over Splunk-arkitekturen og dens komponenter.
Del 2 - Splunk intervjuspørsmål (Avansert)
La oss nå se på de avanserte spørsmålene om Splunk-intervju.
6. Hva er komponentene i Splunk-arkitektur?
Svar:
Det er fire komponenter i Splunk-arkitekturen. De er:
- Indekser : Indekserer maskindata
- Speditør: Videresender logger for å indeksere
- Søkehode: Tilbyr GUI for søk
- Distribusjonsserver: Administrerer Splunk-komponentene (indekser, speditør og søkehode) i et distribuert miljø
7. Gi noen få tilfeller av kunnskapsobjekter.
Svar :
Dette er de ofte stilte Splunk-intervjuspørsmålene i et intervju. Kunnskapsobjekter kan brukes i mange domener. Få eksempler er:
Applikasjonsovervåking: Dette kan brukes til å overvåke applikasjoner i sanntid med konfigurerte varsler som vil varsle administratorer / brukere når et program krasjer.
Fysisk sikkerhet: I tilfelle flom / vulkan osv. Kan dataene brukes til å trekke innsikt hvis organisasjonen har å gjøre med slike data.
Nettverkssikkerhet: Du kan skape et sikkert miljø ved å svarteliste IP-en til ukjente enheter og dermed redusere datalekkasjer i enhver organisasjon.
Medarbeiderledelse: Ansattes utmattelse er en av utfordringene som enhver organisasjon står overfor, og i løpet av oppsigelsestiden kan arbeidstakers aktivitet spores for å beskytte organisasjonens data og derved overvåke deres aktivitet og begrense enhver annen ansatt i oppsigelsesperioden til ikke å gjøre det samme .
8.Explain Search Factor (SF) & Replication Factor (RF)
Svar:
Dette er terminologiene som brukes i Splunk-klyngeteknikker. Indexer cluster er en spesielt konfigurert gruppe av Splunk Enterprise indeksere som replikerer eksterne data og brukes til gjenoppretting av katastrofer.
Når det gjelder Splunk-dokumentasjonssøket, kan faktoren beskrives som “Antall søkbare kopier av data som en indeksklynge opprettholder. Standardverdien for søkefaktoren er 2 ”mens replikasjonsfaktoren er definert som antall kopier med data som klyngen opprettholder.
Indexer-klyngen har både en søkefaktor og en replikasjonsfaktor, mens søkehodeklyngen bare har en søkefaktor
La oss gå til de neste spørsmålene om Splunk-intervju.
9. Hva er Splunk bøtter? Forklar bøttens livssyklus.
Svar:
Katalogene der de indekserte dataene er lagret i, kalles Splunk-bøtter, og disse har hendelser i den bestemte perioden. Livssyklusen til Splunk bøtte inkluderer fire etapper varme, varme, kalde, frosne og tine.
- Hot - Denne bøtta inneholder de nylig indekserte dataene og er åpen for skriving.
- Varm - Etter at dataene har falt i varm bøtte, avhengig av datapolitikk, flyttes de til varme bøtter
- Kald - Neste trinn etter varm er det kalde stadiet der dataene ikke kan redigeres.
- Frozen - Som standard sletter indekseren dataene fra frosne bøtter, men disse kan også arkiveres.
- Opptint - Innhenting av informasjon fra arkiverte filer (frossen bøtte) er kjent som tining.
10. Hvorfor skal vi bruke Splunk Alert? Hva er de forskjellige alternativene mens du setter opp varsler?
Svar:
Tilstanden for å være på vakt for eventuelle feil er kjent som varsling, og i Splunk kan miljøvarsler oppstå på grunn av eventuelle tilkoblingssvikt eller sikkerhetsbrudd eller brudd på brukeropprettede regler.
For eksempel sende varsler eller en rapport fra brukerne som ikke har logget seg på etter å ha brukt sine tre forsøk i en portal til applikasjonsadministratoren.
Ulike alternativer som er tilgjengelige under konfigurering av varsler, er:
- Det kan opprettes en nettkrok for å skrive varslene til hipchat eller GitHub.
- Legg til resultater, .csv eller pdf eller i tråd med meldingens hoveddel, slik at grunnårsaken til varselet kan identifiseres.
- Billetter kan opprettes og varsler kan strupes fra en maskin eller en IP.
Anbefalt artikkel
Dette har vært en guide til Liste over Splunk Intervju Spørsmål og svar, slik at kandidaten lett kan slå sammen disse Splunk Intervju Spørsmål og svar. Du kan også se på følgende artikkel for å lære mer -
- SAS System Interview Questions - Topp 10 nyttige spørsmål
- 10 utmerkede spørsmål om Tableau-intervju du må vite
- 15 mest vellykkede spørsmål og svar på Oracle-intervju
- Spørsmål om nettverkssikkerhetsintervju - Topp og mest stilte
- Splunk vs Nagios