

Lær om forskjellen mellom statistikk og maskinlæring
Læring av maskiner brukes effektivt innen forskjellige felt som funn av svindel, søkeresultater på nettet, sanntidsannonser på websider og mobile enheter, tekstbasert sentimentanalyse, kredittscore og de nest beste tilbudene, prediksjon av utstyrsfeil, nye prismodeller, nettverksinntrengingsdeteksjon, mønster og bildegjenkjenning, og spamfiltrering via e-post blant andre felt. Statistikk er definert som studiet av innsamling, analyse, tolkning, presentasjon og organisering av data. Når statistikk brukes på et vitenskapelig, industrielt eller samfunnsmessig problem, begynner prosessen vanligvis med å bestemme en statistisk populasjon eller en statistisk modellprosess.
Statistikk vs maskinlæring -
Data endres og utvikles kontinuerlig. Men det er veldig viktig å tilpasse seg disse endringene fordi data er et kritisk aspekt av veksten til selskaper over hele kloden.
Data er definert som vanlige fakta og statistikk som samles inn under den daglige driften av et merke / selskap. Mens nesten alle typer selskaper samler inn data, er det veldig viktig at merkevarer gir mening om den forstanden.
Uten å kunne utlede noen innsikt og kunnskap fra dataene, blir det helt ubrukelig. Det er grunnen til at selv om selskaper har mye informasjon og data, taper de noen ganger fordi de ikke er i stand til å forstå noe av det.
Siden etableringen samler selskaper mye informasjon og data om forskjellige ting som kundeinformasjon, høydepunkter fra produktene, partnerproblemer og tilbakemeldinger fra ansatte.
Denne informasjonen og informasjonen kan effektivt brukes til å registrere og måle et omfattende spekter av forretningsfunksjoner, enten det er eksternt eller internt. På egne data er ikke veldig informativ, men det er et grunnlag som selskaper kan ta fremtidige beslutninger og utvikle vellykkede strategier også.
Kunder er grunnlaget for hvilke merkevarer som bygde navn og verdi i markedet. Derfor er kundedata ekstremt viktig, ettersom de lar merkevarer forbedre og forstå kundene sine på en rekke forskjellige måter.
Data er derfor den eneste måten selskaper forstår mange aspekter ved selskapets funksjoner som en rekke henvendelser, mottatte inntekter, blant annet utgifter.
Data er derfor viktig for at merkevarer skal forstå kundenes tankesett og forventninger. Alt i alt er data et viktig element for å sikre fortsatt suksess og vekst for ethvert selskap, spesielt i denne konkurransedyktige tidsalder.
Artikkelen om Statistics vs Machine learning er strukturert som nedenfor -
- Statistikk vs Machine Learning Infographics
- Hva er forskjellen Statistikk kontra maskinlæring?
- Et mer dyptgående blikk på statistikk og dens betydning i samfunnet
- Et mer dyptgående blikk på maskinlæring og dens betydning i samfunnet
- Konklusjon - Statistikk vs maskinlæring
Statistikk vs Machine Learning Infographics
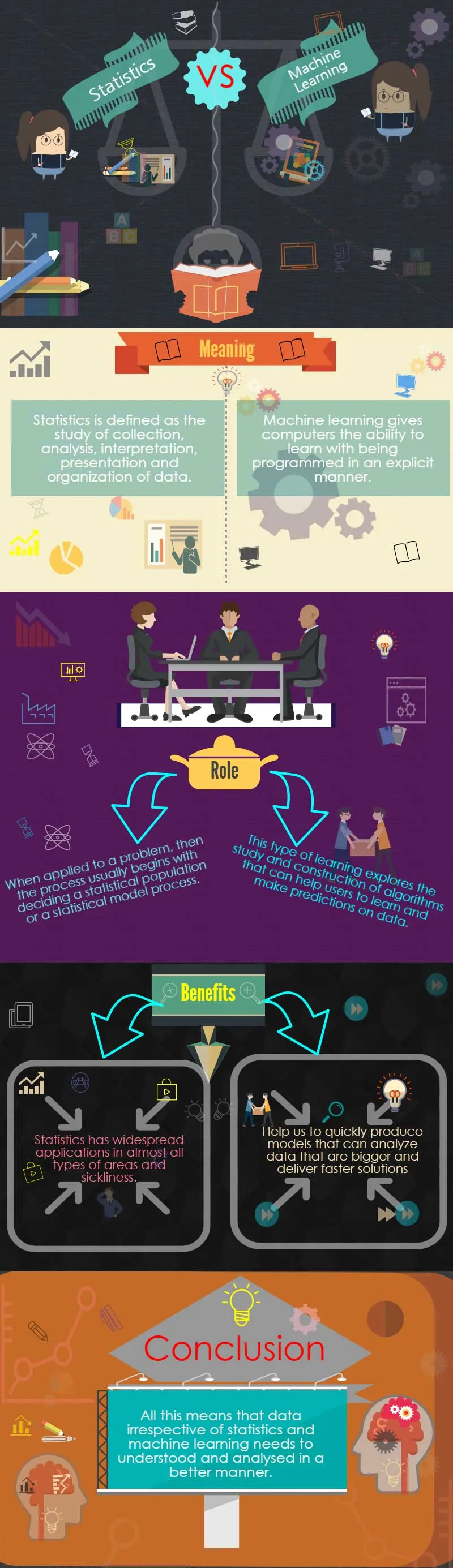
Er data og informasjon den samme? Hva er forskjellen Statistikk kontra maskinlæring?
Data og informasjon er to forskjellige ting. Mens data er rå fakta og statistikk, er informasjon de samme dataene som presenteres på en nøyaktig og tidsriktig måte.
Videre er informasjon spesifikk og organisert, generelt gjort med et formål å gi kontekst og forståelse til et bestemt aspekt av merkevarefunksjon. En annen måte informasjon er forskjellig fra data på er at det er gjennom informasjonen at merkevarer kan ta riktige beslutninger og lage kampanjer som er kreative, effektive og engasjerende.
Det er derfor informasjon er så viktig fordi den lar merkevarer ta beslutninger som kan brukes av ledelsen for å virkelig styrke seg selv.
Det er grunnen til at merkevarer streber etter å samle informasjon om kunder og kunder slik at de kan samhandle med dem på en effektiv måte. Alt dette blir sagt, er det viktig å huske at den sanne verdien av informasjon ligger i dens evne til å gi retning til selskapet.
Hvis det for eksempel mangler kundetilfredshet i henhold til informasjonen fra kundene, er det bare nyttig hvis merkevaren endrer denne oppfatningen ved å tilby bedre verdi for sine produkter og tjenester.
Kort sagt, informasjonsprosessen skal inngå i en bredere gjennomgangsprosess i selskapene, slik at den kan hjelpe dem med å produsere bedre og mer lønnsomme resultater.
Informasjon kan derfor samles inn og analyseres på forskjellige måter som er maskinlæring og statistikk.
Fra personer som bor i et land til atomer inneholdt i en krystall, kan befolkningen være av forskjellige typer. Å håndtere alle aspekter av data som planlegging av datainnsamling til eksperimenter, er statistikk et variert og omfattende felt.
Maskinlæring er derimot et underfelt i informatikk som har utviklet seg fra studiet av beregningslæringsteori innen kunstig intelligens og mønstergjenkjenning.
Arthur Samuel definerte i 1959 maskinlæring som studieretning som gir datamaskiner muligheten til å lære med å bli programmert på en eksplisitt måte.
Denne typen læring utforsker studier og konstruksjon av algoritmer som kan hjelpe brukere til å lære og komme med spådommer om data. Slike algoritmer fungerer ved en modelloppretting og brukes til å lage datadrevet prediksjon fremfor å følge statiske programinstruksjoner.
Anbefalte kurs
- Kurs om IP-ruting
- Opplæringskurs for hacking
- Kurs om RMAN
- Online sertifiseringskurs i Python

Et mer dyptgående blikk på statistikk og maskinlæring
Statistikk spiller en veldig viktig rolle i nesten alle områder av menneskelig aktivitet. Fra å hjelpe til med å bestemme per lands innbygger til sysselsettingsgrad til antall medisinske / skolefasiliteter som kreves i en region, har statistikk og maskinlæring en veldig viktig rolle i det menneskelige samfunns funksjon.
I nåværende tid har statistikk en veldig viktig og kritisk posisjon på en rekke felt, inkludert handel, handel, psykologi, kjemi, botanikk, astronomi blant mange andre.
Dette fordi statistikk har et bredt bruksområde som et felt i nesten alle typer områder og sykdom. Her er noen viktige områder der statistikk og maskinlæring kan brukes til å samle bedre informasjon og innsikt.
- Virksomhet: Statistikk har en veldig viktig og kritisk rolle å spille innen forretningsområdet. Dette er fordi merkevarer og selskaper er ekstremt konkurransedyktige, noe som gjør det vanskelig for merkevarer å ligge foran kundens forventninger og ønsker. Det er derfor viktig at merkevarer tar raske beslutninger, slik at de kan ta bedre beslutninger. Statistikk kan hjelpe merkevarer til å forstå kundens forventninger og derved balansere etterspørsel og tilbud på en effektiv måte. Dette betyr at mange avgjørelsene til merket er avhengig av gode statistiske beslutninger og innsikt.
- Økonomi: Et annet viktig område der statistikk spiller en viktig rolle i økonomi. Dette fordi statistikk i stor grad avhenger av statistikk. Dette fordi nasjonalinntektskontoer er viktige indikatorer for økonomer og administratorer. Statistiske metoder brukes for utarbeidelse av disse regnskapene og til og med for innsamling og analyse av data. Forholdet mellom tilbud og krav studeres gjennom statistisk analyse, og nesten alle aspekter av økonomi krever stor og innviklet forståelse av statistikk.
- Matematikk: Statistikk er en integrert del av naturvitenskapelige og samfunnsvitenskapelige fag. Metodene for naturvitenskap er pålitelige, men konklusjonene deres er noen ganger ikke så sannsynligvis fordi de er basert på ufullstendige bevis. Statistisk hjelp til å beskrive disse målingene på en presis måte. Mange statiske metoder som sannsynlighetsgjennomsnitt, spredning, estimering er en integrert del av matematikken og brukes ofte på dette feltet.
- Banking: Et annet område der statistikk spiller en viktig rolle i bank. Bankene krever statistikk av en rekke årsaker og formål. Nesten alle banker jobber med prinsippet om at når en av kundene deres investerer litt penger i banken sin, vil de oppbevare dem i banken sin i noen tid og ikke ta ut dem. Ved å tjene fortjeneste fra disse innskuddene tjener banken overskudd, og dette er hovedkilden til inntektene. Bankfolkene bruker statistiske tilnærminger basert på sannsynlighet for å estimere antall innskytere og deres krav for en viss dag, og dermed gjøre det mulig for dem å fungere på en jevn og effektiv måte.
- Statsstyring: Statistikk er et annet område som er essensielt for vekst og utvikling av ethvert land. Dette er fordi statistikk er grunnlaget for hvilken politikk som utarbeides i landet. Det er grunnen til at statistiske data er mye brukt til å ta administrative beslutninger. For eksempel, hvis regjeringen ønsker å øke lønnsskalaene til ansatte for å hjelpe dem med å øke levestandarden, er det gjennom statistikk at regjeringen kan finne en økning i levekostnadene. I tillegg er utarbeidelsen av føderale og provinsielle regjeringsbudsjetter også avhengig av statistikk fordi det hjelper tjenestemennene å estimere forventede utgifter og inntekter fra forskjellige kilder. Så statistikk er veldig viktig for å hjelpe regjeringer med å utføre sine oppgaver på en smidig måte.

Et mer dyptgående blikk på maskinlæring og dens betydning i samfunnet
Datamaskiner og bærbare datamaskiner har tatt hele verden med storm og har drastisk endret livet til mange mennesker. La oss visualisere en situasjon i et minutt. La oss prøve å tenke på en verden uten datamaskiner.
Hvis dette skjedde, ville ikke mennesker i det medisinske feltet funnet mange botemidler mot sykdommer, fordi datamaskiner har spilt en viktig rolle i prosessen for å hjelpe medisinsk fagpersonell til å få bedre innsikt i en verden av sykdommer og helse.
Igjen, filmer som Toy Story og Jurassic Park ville ikke vært mulig uten datamaskiner fordi disse filmene har benyttet seg av datagrafikk og animasjon.
Apotek ville ha vanskelig for å holde rede på hvilke medisiner de skal gi til pasientene sine. Å telle stemmer ville være nær umulig uten datamaskiner, og enda viktigere var romutforskning fortsatt ha vært en fjern drøm for alle romentusiaster.
På grunn av datamaskinens økende betydning, har datateknologier fått en enda større rolle, og dette har resultert i maskiners mulighet til automatisk å bruke komplekse matematiske beregninger på big data i raskere og raskere tempo.
Noen av de utbredte eksemplene på applikasjoner for maskinlæring som i dag er ekstremt populære i verden, inkluderer følgende:
- Essensen av maskinlæring er den ekstremt populære Google-selvdrevne bilen
- Online anbefalingstilbud som er tilpasset plattformer som Amazon og Netflix, er et resultat av maskinlæringsapplikasjoner som nå er egnet til å forstå den daglige menneskelige oppførselen
- Å forstå kundeadferd på Twitter for merker og nå maskinlæring med språklig regeloppretting, hjelper merkevarer til å forstå og styrke kundene sine i det offentlige domene
- Frauddeteksjon er et viktig felt der maskinlæring hjelper merkevarer til å være trygge og effektive på alle plattformer
I dag er det en økende interesse for maskinlæring fordi i dag de økende volumene og variantene av tilgjengelige data, databehandling har resultert i et behov for billigere og kraftige dataanalysemetoder.
Dette betyr at maskinlæring kan hjelpe oss med å raskt produsere modeller som kan analysere større data og levere raskere løsninger som er nøyaktige og effektive, selv i stor skala.
Alt dette betyr at spådommer av høy verdi kan hjelpe økonomier og merkevarer til å ta bedre og smartere beslutninger, ikke bare uten menneskelig innblanding, men også i sanntid.
Merker trenger raskt bevegelige modelleringsstrømmer for å følge med markedets krav, og de kan gjøre dette på en effektiv måte gjennom bruk av maskinlæring.
Mens mennesker generelt kan lage en eller to gode modeller i uken, kan maskinlæring lage tusenvis av modeller i uken, noe som gjør merker mer effektive og bedre på lang sikt også.
Læring av maskiner er derfor veldig forskjellig fra datastatistikk. Enkelt sagt, mens maskinlæring bruker de samme algoritmer og teknikker, er det en stor forskjell mellom disse to statistikk og maskinlæringsteknikker.
Mens data mining oppdager tidligere ukjente mønstre og kunnskap, brukes maskinlæring for å gjengi kjente mønstre og kunnskap.
Disse mønstrene blir deretter automatisk brukt på andre data, og deretter brukes de til å hjelpe de berørte mennesker til å ta bedre beslutninger og handlinger.
Med den økte bruken av datamaskiner utvikles datateknikker og maskinlæring også raskt for å imøtekomme behovene til merkevarer og selskaper på tvers av sektorer.
Nevrale nettverk har lenge vært brukt i data mining-applikasjoner, og nå med datamaskinens kraft er det mulig å lage flere nevrale nettverk som har mange lag. I maskinlæring lingo kalles disse dype nevrale nettverk.
Konklusjon - Statistikk vs maskinlæring
Alt dette betyr at data uavhengig av statistikk kontra maskinlæring trenger å forstå og analysere på en bedre måte. Dette fordi datainnsikt er avgjørende for suksess og fiasko for merker på tvers av kategorier, og å investere dem er et av de viktigste kravene til alle typer selskaper.
Anbefalte artikler
Så her er noen artikler som vil hjelpe deg å få mer detaljert informasjon om statistikk og maskinlæring, og også om statistikk og maskinlæring, så bare gå gjennom lenken som er gitt nedenfor.
- Machine Learning vs Statistics
- Karrierer i statistikk
- Viktig trinn til investeringsbankers livsstil
- Spørsmål om statistikkintervju | Nyttig og mest spurt