

Forskjellen mellom Apache Nifi og Apache Spark
Inntil lenge, da det var et tungt arbeid som måtte fullføres, stolte folk på hester for å trekke tunge lass, opprettholde hastigheten eller noe annet derimellom. Imidlertid var ikke alle hester skikket til alle oppgaver. Det samme er teknologien i dag. Når nye teknologier kommer inn hver dag, blir det ekstremt viktig å kjenne deres virkelige applikasjoner. To slike teknologier er Apache Nifi og Apache Spark, og vi skal studere om dem i dette innlegget.
Apache Spark er et kildekodet rammeverk med åpen kildekode som tar sikte på å gi et grensesnitt for å programmere hele settet med klynger med implisitt feiltoleranse og dataparallellitet. Den benytter seg av RDD-er (Resilient Distribuerte datasett) og behandler dataene i form av Diskretiserte strømmer som videre blir brukt til analytiske formål.
Apache Nifi (som er den korte formen for NiagaraFiles) er et annet programvareprosjekt som tar sikte på å automatisere dataflyten mellom programvaresystemer. Designet er basert på flytbasert programmeringsmodell som gir funksjoner som inkluderer drift med klyngens evne. Det er et brukervennlig, pålitelig og et kraftig system for å behandle og distribuere data. Den støtter skalerbare regisserte grafer for dataruting, systemformidling og transformasjonslogikk. La oss diskutere sammenligningene mellom begge temaene.
Head to head sammenligning mellom Apache Nifi vs Apache Spark (Infographics)
Nedenfor er topp 9 sammenligning mellom Apache Nifi vs Apache Spark
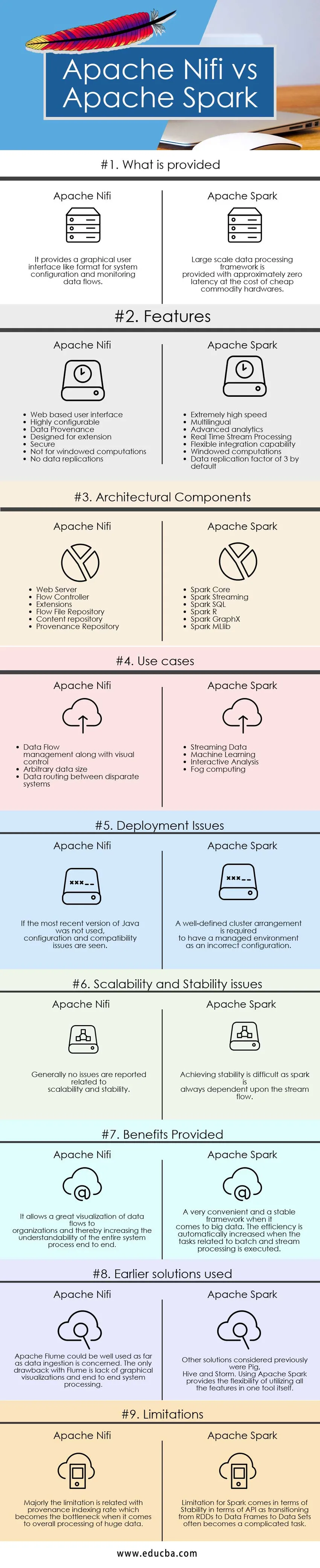
Viktige forskjeller mellom Apache Nifi vs Apache Spark
Forskjellene mellom Apache Nifi og Apache Spark er forklart i punktene presentert nedenfor:
- Apache Nifi er et datainntaksverktøy som brukes til å levere et brukervennlig, kraftig og pålitelig system, slik at behandling og distribusjon av data over ressurser blir enkelt, mens Apache Spark er en ekstremt rask klyngedateknologi som er designet for raskere beregning av effektivt å bruke interaktive spørsmål, i minnestyring og strømbehandlingsfunksjoner.
- Apache Nifi fungerer i frittstående modus og en klyngemodus, mens Apache Spark fungerer godt i lokale eller frittstående modus, Mesos, Garn og andre typer big data klyngemodus.
- Funksjonene i Apache Nifi inkluderer garantert levering av data, effektiv databuffering, Prioritert kø, Flow Specific QoS, Data Provenance, Recovery av rullebuffere, Visuell kommando og kontroll, Flow-maler, Sikkerhet, Parallel Streaming-funksjoner mens funksjoner i Apache-gnist inkluderer lynrask hastighet prosesseringsevne, flerspråklig, in-memory computing, effektiv utnyttelse av hardware maskinvaresystemer, Advanced Analytics, Effektiv integrasjonsevne.
- Apache Nifi gir bedre lesbarhet og generell forståelse av systemet ved å gi visualiseringsfunksjoner og dra og slipp-funksjoner. Dataflyten kan enkelt styres og styres ved bruk av konvensjonelle teknikker og prosesser, mens det i tilfelle Apache Spark er nødvendig for å se på disse visualiseringene et klyngestyringssystem som Ambari. Apache Spark i seg selv gir ikke visualiseringsevner og er bare bra for programmering. Det er langt et veldig praktisk og stabilt system for behandling av enorme datamengder.
- Begrensningen med Apache Nifi er relatert til hva som er dens fordel. Den eneste dra og slipp-funksjonen gir en begrensning av ikke å kunne skalere og gi robusthet når det kommer til å integrere den med andre komponenter og verktøy, mens i tilfelle Apache Spark kommer den primære begrensningen sammen med bruk av omfattende varemaskinvare og håndtering av dem blir til tider en kjedelig oppgave. Den andre rapporterte begrensningen kommer sammen med streamingfunksjonene relatert til Diskretisert strøm og Windowed eller batch-strøm, der transformasjonen av RDDer til dataramme og datasett gir en grunn til ustabilitet til tider.
Apache Nifi vs Apache Spark Comparision Table
| Grunnlag for sammenligning | Apache Nifi | Apache Spark |
| Hva er gitt | Det gir et grafisk brukergrensesnitt som et format for systemkonfigurasjon og overvåking av datastrømmer. | Rammeverk i databehandling i stor skala er utstyrt med omtrent null latenstid til bekostning av billig varevare. |
| Funksjoner |
|
|
| Arkitektoniske komponenter |
|
|
| Bruk saker |
|
|
| Problemer med distribusjon | Hvis den nyeste versjonen av Java ikke ble brukt, blir konfigurasjons- og kompatibilitetsproblemer sett | Et godt definert klyngearrangement er påkrevd for å ha et administrert miljø som en feil konfigurasjon |
| Problemer med skalerbarhet og stabilitet | Vanligvis rapporteres det ikke om problemer knyttet til skalerbarhet og stabilitet | Det er vanskelig å oppnå stabilitet, da en gnist alltid er avhengig av strømmen. |
| Fordeler gitt | Det tillater en god visualisering av datastrømmer til organisasjoner og derved øker forståelsen av hele systemprosessen ende til ende | Et veldig praktisk og stabilt rammeverk når det gjelder big data. Effektiviteten økes automatisk når oppgavene relatert til batch- og strømbehandling utføres. |
| Tidligere løsninger brukt | Apache Flume kan brukes godt når det gjelder inntak av data. Den eneste ulempen med Flume er mangel på grafiske visualiseringer og systembehandling til ende | Andre løsninger som ble vurdert tidligere var Pig, Hive og Storm. Å bruke Apache Spark gir fleksibiliteten til å bruke alle funksjonene i et verktøy selv. |
| begrensninger | I hovedsak er begrensningen relatert til proveniens indekseringsrate som blir flaskehalsen når det kommer til generell behandling av enorme data | Begrensning for gnist kommer i form av stabilitet når det gjelder API, da overgang fra RDD-er til datarammer til datasett ofte blir en komplisert oppgave. |
Konklusjon - Apache Nifi vs Apache Spark
For å avslutte innlegget, kan det sies at Apache Spark er en tung krigshest mens Apache Nifi er en kvikk løpshest. Begge har sine egne fordeler og begrensninger som skal brukes på sine respektive områder. Du må bestemme riktig verktøy for virksomheten din. Følg med på bloggen vår for flere artikler relatert til nyere teknologi for big data.
Anbefalt artikkel
Dette har vært en guide til Apache Nifi vs Apache Spark, deres betydning, sammenligning mellom hodet og hodet, nøkkelforskjeller, sammenligningstabell og konklusjon. Du kan også se på følgende artikler for å lære mer -
- Apache Hadoop vs Apache Spark | Topp 10 sammenligninger du må vite!
- Apache Storm vs Apache Spark - Lær 15 nyttige forskjeller
- 7 viktige ting om Apache Spark (guide)
- De 15 beste tingene du trenger å vite om MapReduce vs Spark