

Introduksjon til Hive-kommandoer
Hive-kommando er et datavarehusinfrastrukturverktøy som sitter på toppen Hadoop for å oppsummere Big data. Den behandler strukturerte data. Det gjør datasøket og analysen enklere. Hive-kommandoen kalles også som "skjema for lesing;" Hive verifiserer ikke data når de er lastet inn, bekreftelse skjer bare når det blir gitt en spørring. Denne egenskapen til Hive gjør det raskt for første gangs lasting. Det er som å kopiere eller bare flytte en fil uten å sette noen begrensninger eller sjekker. Hiven ble først utviklet av Facebook. Apache Software Foundation tok det opp senere og utviklet det videre.
Her er komponentene i Hive-kommandoen:
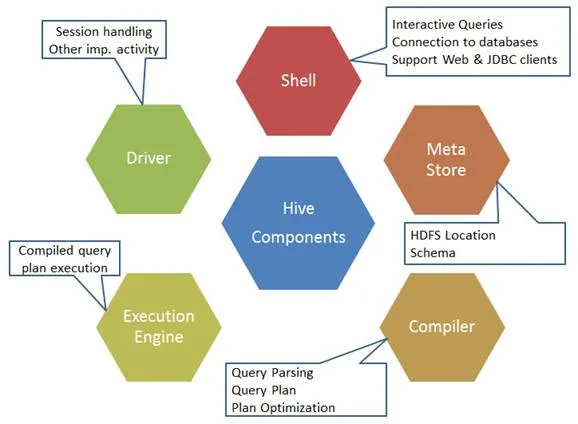
Fig. 1. Komponenter fra Hive
https://www.developer.com/
Her er kommandoene Funksjoner av Hive listet nedenfor:
- Hive-butikker er rå og behandlet datasett i Hadoop.
- Den er designet for OnLine Transaction Processing (OLTP). OLTP er systemene som letter data med høyt volum på veldig kortere tid uten å stole på én server.
- Det er raskt, skalerbart og pålitelig.
- SQL-typen spørringsspråk som gis her kalles HiveQL eller HQL. Dette gjør ETL-oppgaver og annen analyse enklere.
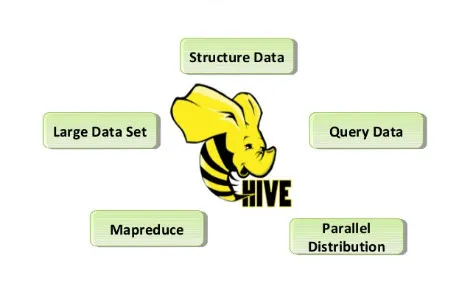
Fig 2. Hiveegenskaper
Kilder bilder: - Google
Det er få begrensninger av Hive-kommandoen også, som er listet nedenfor:
- Hive støtter ikke underspørsmål.
- Hive støtter sikkert overskriving, men dessverre støtter det ikke sletting og oppdateringer.
- Hive er ikke designet for OLTP, men den brukes til den.
For å gå inn i Hive's interaktive skall:
$ HIVE_HOME / bin / bikube
Grunnleggende bikube-kommandoer
-
Skape
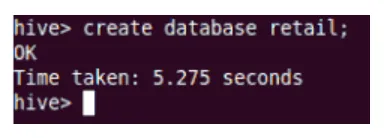
Dette vil opprette den nye databasen i Hive.
-
Miste
Dråpen vil fjerne et bord fra Hive
-
Endre
Alter kommando vil hjelpe deg med å gi nytt navn til tabellen eller tabellkolonnene.
For eksempel:
bikube> ALTER TABELL ansatt RENAME TIL ansatt1;
-
Forestilling
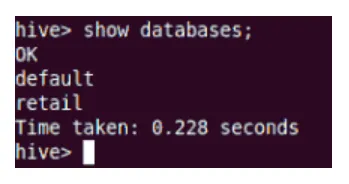
Vis kommando vil vise alle databasene som er bosatt i Hive.
-
Beskrive
Beskriv kommando vil hjelpe deg med informasjonen om skjemaet i tabellen.
Midlertidige Hive-kommandoer
Hive deler en tabell i forskjellige relaterte partisjoner basert på kolonner. Ved å bruke disse partisjonene blir det lettere å spørre data. Disse partisjonene blir videre delt inn i bøtter, for å kjøre spørringen effektivt videre til data.
Med andre ord, bøtter distribuerer data i settet med klynger ved å beregne hasjkoden til nøkkelen som er nevnt i spørringen.
-
Legger til partisjon
Legge til partisjon kan oppnås ved å endre tabellen. Si at du har tabellen “EMP”, med felt som ID, navn, lønn, avd., Betegnelse og yoj.
bikube> ALTER TABELL-ansatt
> LEGG TIL PARTISJON (år = '2012')
beliggenhet '/ 2012 / del2012';
-
Gi nytt navn til partisjon
bikube> ALTER TABELL MEDARBEIDERDELING (år = '1203')
RENAME TO PARTITION (Yoj = '1203');
-
Drop Partition
bikube> ALTERBORD DROP AV MEDARBEIDER (HVIS EKSISTER)
> PARTISJON (år = '1203');
-
Relasjonsoperatører
Relasjonsoperatører består av et visst sett av operatører, som hjelper med å hente relevant informasjon.
For eksempel: Si at "EMP" -tabellen din ser slik ut:
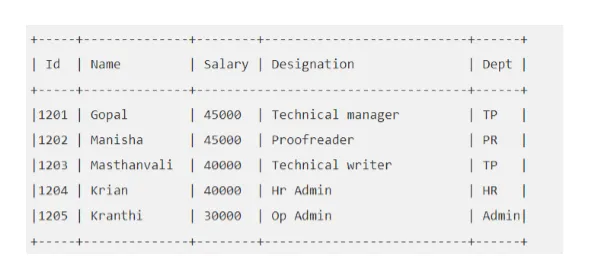
La oss utføre Hive-spørring som vil hente oss den ansatte hvis lønn er større enn 30000.
bikube> VELG * FRA EMP HVOR Lønn> = 40000;
-
Aritmetiske operatører
Dette er operatører som hjelper til med å utføre aritmetiske operasjoner på operandene, og på sin side alltid returnerer talltyper.
For eksempel: For å legge til to tall, for eksempel 22 og 33
bikube> VELG 22 + 33 LEGG TIL FRA temp;
-
Logisk operatør
Disse operatørene skal utføre logiske operasjoner, som til gjengjeld alltid returnerer True / False.
bikube> VELG * FRA EMP HVOR Lønn> 40000 && avd. = TP;
Avanserte Hive-kommandoer
-
Utsikt
Visningskonsept i Hive er lik som i SQL. Visningen kan opprettes når du utfører en SELECT-setning.
Eksempel:
bikube> CREATE VIEW EMP_30000 AS
VELG * FRA EMP
HVOR lønn> 30000;
-
Laster data i tabellen
Hive> Last inn data lokal inpath '/home/hduser/Desktop/AllStates.csv' i tabellstater;
Her er "States" den allerede opprettede tabellen i Hive.
https://www.tutorialspoint.com/hive/
Hive har noen innebygde funksjoner som hjelper deg med å hente resultatet ditt på en bedre måte.
Som runde, gulv, BIGINT osv.
-
Bli med
Forbindelsesklausul kan hjelpe til med å bli sammen med to tabeller basert på samme kolonnenavn.
Eksempel:
bikube> VELG c.ID, c.NAME, c.AGE, o.AMOUNT
FRA KUNDER c BLI MED PÅ ORDRE o
ON (c.ID = o.CUSTOMER_ID);
Alle slags sammenføyninger støttes av Hive: Venstre ytre skjøt, høyre ytre skjøt, full ytre sammenføyning.
Tips og triks for å bruke bikubekommandoer
Hive gjør databehandling så enkel, grei og utvidbar, slik at brukerne legger mindre vekt på å optimalisere Hive-spørsmålene. Men å være oppmerksom på få ting mens du skriver Hive-spørring, vil sikkert gi stor suksess med å håndtere arbeidsmengden og spare penger. Nedenfor er noen tips angående det:
- Partisjoner og bøtter: Hive er et dataverktøy som kan spørres på store datasett. Å skrive spørringen uten å forstå domenet kan imidlertid gi store partisjoner i Hive.
Hvis brukeren er klar over datasettet, kan relevante og høyt brukte kolonner grupperes i samme partisjon. Dette vil hjelpe til med å kjøre spørringen raskere og ineffektiv måte.
Til syvende og sist nei. av kartleggings- og I / O-operasjoner vil også bli redusert.
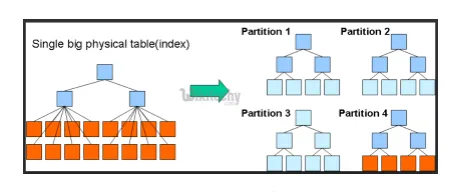
Fig. 3. Partisjonering
Kilder bilder: Google image
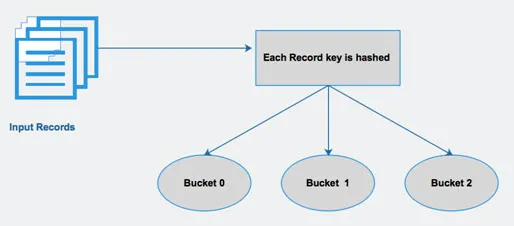
Fig 4 Bucketing
Kilder bilder: - Google-bilde
- Parallell kjøring: Hive kjører spørringen i flere trinn. I noen tilfeller kan disse stadiene avhenge av andre stadier, og kan derfor ikke komme i gang når forrige trinn er fullført. Uavhengige oppgaver kan imidlertid løpe parallelt for å spare total kjøretid. Slik aktiverer du parallellkjøringen i Hive:
sett hive.exec.parallel = true;
Dermed vil dette forbedre klyngebruken.
- Blokkering av prøvetaking: Prøvetaking av data fra en tabell tillater utforskning av spørsmål om data.
Til tross for bucking, ønsker vi heller å prøve datasettet mer tilfeldig. Blokkprøvetaking kommer med forskjellige kraftige syntaks, som hjelper til med å sampling av dataene på en annen måte.
Prøvetaking kan brukes til å finne ca. info fra datasettet som den gjennomsnittlige avstanden mellom opprinnelse og destinasjon.
Forespørsel 1% av big data vil gi nær det perfekte svaret. Utforsking blir mye enklere og effektiv.
Konklusjon - Hive-kommandoer
Hive er et abstraksjon på høyere nivå på toppen av HDFS, som gir fleksibelt spørringsspråk. Det hjelper med å spørre og behandle data på en enklere måte.
Hive kan kobles sammen med andre Big data-elementer for å utnytte funksjonaliteten på en fullverdig måte.
Anbefalte artikler
Dette har vært en guide til Hive-kommandoer. Her har vi diskutert grunnleggende så vel som avanserte Hive-kommandoer og noen umiddelbare Hive-kommandoer. Du kan også se på følgende artikkel for å lære mer -
- Spørsmål om Hive-intervju
- Hive VS nyanse - Topp 6 nyttige sammenligninger
- Tableau kommandoer
- Adobe Photoshop-kommandoer
- Bruke ORDER BY-funksjon i Hive
- Last ned og installer Hive trinnvis