

Introduksjon til svinekommandoer
Apache Pig et verktøy / plattform som brukes til å analysere store datasett og utføre lange serier med dataoperasjoner. Gris brukes sammen med Hadoop. Alle svineskript internt blir konvertert til kartreduserende oppgaver og blir deretter utført. Den kan håndtere strukturerte, semistrukturerte og ustrukturerte data. Gris lagrer, resultatet til HDFS. I denne artikkelen lærer vi flere typer svinekommandoer.
Her er noen egenskaper ved gris:
- Selvoptimalisering: Gris kan optimalisere utførelsesjobber, brukeren har frihet til å fokusere på semantikk.
- Ease to Program: Pig gir språk / dialekt på høyt nivå kjent som Pig Latin, som er lett å skrive. Pig Latin gir mange operatører, som programmerer kan bruke til å behandle dataene. Programmereren har også fleksibiliteten til å skrive sine egne funksjoner.
- Extensible: Pig forenkler opprettelsen av tilpasset funksjon som kalles UDF's (Brukerdefinerte funksjoner), som gjør programmerere i stand til å oppnå ethvert behandlingskrav raskt og enkelt. Grismanus kjører på et skall kjent som gryntet.
Hvorfor svinekommandoer?
Programmerere som ikke har det bra med Java, sliter vanligvis med å skrive programmer i Hadoop, dvs. å skrive kartreduserende oppgaver. For dem er svin-latin som er ganske som SQL-språk en velsignelse. Sin tilnærming til flere spørsmål reduserer lengden på koden.
Så totalt sett sin konsise og effektive måte å programmere på. Svinekommandoer kan påkalle kode på mange språk som JRuby, Jython og Java.
Arkitekturen til Pig Commands
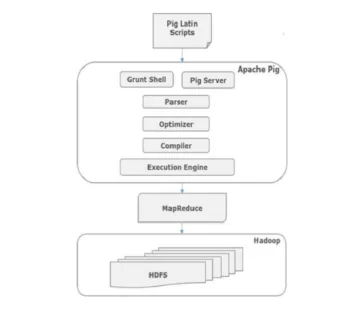
Alle skriptene som er skrevet i gris-latin over grynt skall, går til analysøren for å sjekke syntaks og andre diverse kontroller skjer også. Utgangen til analysatoren er en DAG. Denne DAG-en blir deretter overført til Optimizer, som deretter utfører logisk optimalisering som projeksjon og skyver ned. Deretter følger kompilatoren den logiske planen til MapReduce-jobber. Til slutt blir disse MapReduce-jobbene sendt til Hadoop i sortert rekkefølge. Disse jobbene blir utført og gir ønskede resultater.
Pig-Latin datamodell er fullstendig nestet, og den tillater komplekse datatyper som kart og tuple.
Enhver verdi av Latin-grisen (uavhengig av datatype) er kjent som Atom.
Grunnleggende svinekommandoer
La oss ta en titt på noen av Basic Pig-kommandoene som er gitt nedenfor: -
1. Fs: Dette viser alle filene i HDFS
grynt> fs –ls
2. Clear: Dette vil fjerne det interaktive Grunt-skallet.
grynt> klart
3. Historie:
Denne kommandoen viser kommandoene som er utført så langt.
grynt> historie
4. Lesing av data: Forutsatt at dataene ligger i HDFS, og vi må lese data til Pig.
grunt> college_students = LOAD 'hdfs: // localhost: 9000 / pig_data / college_data.txt'
BRUKE PigStorage (', ')
som (id: int, fornavn: chararray, etternavn: chararray, telefon: chararray,
by: chararray);
PigStorage () er funksjonen som laster inn og lagrer data som strukturerte tekstfiler.
5. Lagring av data: Lagre operatør brukes til å lagre behandlet / lastet data.
grynt> STORE college_students INTO 'hdfs: // localhost: 9000 / pig_Output /' USING PigStorage (', ');
Her er “/ pig_Output /” katalogen der forholdet må lagres.
6. Dump Operator: Denne kommandoen brukes til å vise resultatene på skjermen. Det hjelper vanligvis i feilsøking.
grynt> Dump college_studenter;
7. Beskriv operatør: Det hjelper programmereren å se skjemaet for forholdet.
grynt> beskriv college_studenter;
8. Forklar: Denne kommandoen hjelper deg med å gjennomgå de logiske, fysiske og kartreduserende utførelsesplanene.
grynt> forklar college_studenter;
9. Illustrer operatøren: Dette gir trinnvis utførelse av uttalelser i svinekommandoer.
grynt> illustrer college_studenter;
Mellomliggende grisekommandoer
1. Gruppe: Denne grisen-kommandoen fungerer mot gruppering av data med samme nøkkel.
grynt> gruppe_data = GROUP college_studenter ved fornavn;
2. SAGROUP: Det fungerer på samme måte som gruppeoperatøren. Hovedforskjellen mellom Group & Cogroup-operatøren er den gruppeoperatøren som vanligvis brukes med ett forhold, mens cogroup brukes med mer enn ett forhold.
3. Bli med: Dette brukes til å kombinere to eller flere relasjoner.
Eksempel: For å utføre selvforbindelse, la oss si at "kunde" lastes fra HDFS tp svinekommandoer i to relasjonskunder1 og kunder2.
grynt> kunder3 = BLI MED i kunder1 AV ID, kunder2 BY ID;
Bli med kunne være selv-med, indre-bli, ytre-bli.
4. Kors: Denne svinekommandoen beregner kryssproduktet av to eller flere forhold.
grynt> cross_data = CROSS kunder, bestillinger;
5. Union: Det fusjonerer to forhold. Betingelsen for sammenslåing er at både forholdets kolonner og domener må være identiske.
grynt> student = UNION student1, student2;
Avanserte svinekommandoer
La oss ta en titt på noen av de avanserte grisekommandoene som er gitt nedenfor:
1. Filter: Dette hjelper med å filtrere tuple ut av forhold, basert på visse forhold.
filter_data = FILTER college_students BY city == 'Chennai';
2. Distinct: Dette hjelper deg med å fjerne overflødige tuples fra forholdet.
grynt> distinkt data = DISTINCT college_studenter;
Denne filtreringen vil opprette nytt relasjonsnavn "distinkt data"
3. Foreach: Dette hjelper med å generere datatransformasjon basert på kolonnedata.
grynt> foreach_data = FOREACH student_detaljer GENERATE id, alder, by;
Dette vil få ID, alder og byverdier for hver student fra forholdet studentdetaljer, og dermed lagre det i et annet forhold som heter foreach_data.
4. Ordre etter: Denne kommandoen viser resultatet i en sortert rekkefølge basert på ett eller flere felt.
grunt> order_by_data = BESTILL college_studenter etter alder DESC;
Dette vil sortere forholdet “college_students” i synkende rekkefølge etter alder.
5. Begrensning: Denne kommandoen blir begrenset nei. av tupler fra forholdet.
grynt> limit_data = LIMIT student_detaljer 4;
Tips og triks
Nedenfor er de forskjellige tipsene og triksene til svinekommandoer: -
1. Aktiver komprimering på input og output:
angi input.compression.enabled true;
sett output.compression.enabled sant;
Ovennevnte kodelinjer må være i begynnelsen av Skriptet, slik at Pig-kommandoer kan lese komprimerte filer eller generere komprimerte filer som utdata.
2. Bli med flere forhold:
For å utføre venstre sammenføyning på si tre forhold (input1, input2, input3), må man velge SQL. Det er fordi ytre sammenføyning ikke støttes av gris på mer enn to bord.
Snarere opptrer du til venstre for å delta i to trinn som:
data1 = JOIN input1 BY- tast VENSTRE, input2 BY- tast;
data2 = JOIN data1 BY input1 :: key LEFT, input3 BY key;
Dette betyr to kartreduserende jobber.
For å utføre oppgaven ovenfor mer effektivt, kan man velge “Cogroup”. Cogroup kan delta i flere relasjoner. Cogroup blir som standard ytre sammen.
Konklusjon
Gris er et prosedyrespråk, vanligvis brukt av dataforskere for å utføre ad-hoc-behandling og rask prototyping. Det er et flott ETL og stor databehandlingsverktøy. Grisskripter kan påberopes av andre språk og omvendt. Derfor kan svinekommandoer brukes til å bygge større og komplekse applikasjoner.
Anbefalte artikler
Dette har vært en guide til svinekommandoer. Her har vi diskutert grunnleggende så vel som avanserte svinekommandoer og noen umiddelbare svinekommandoer. Du kan også se på følgende artikkel for å lære mer -
- Adobe Photoshop-kommandoer
- Tableau kommandoer
- Juksark SQL (kommandoer, gratis tips og triks)
- VBA-kommandoer - etterbehandling
- Ulike operasjoner relatert til tuples