

Introduksjon til BFS-algoritme
For å få tilgang til og administrere dataene effektivt, kan de lagres og organiseres i et spesielt format kjent som datastrukturen. Det er mange datastrukturer som stabel, matrise, koblet liste, køer, trær og grafer osv. I lineære datastrukturer, for eksempel stabel, matrise, koblet liste og kø, er dataene organisert i lineær rekkefølge mens, i ikke- lineære datastrukturer som trær og grafer, er data organisert hierarkisk ikke i en sekvens. Grafen er en ikke-lineær datastruktur som har noder og kanter. Noder i graf kan også bli referert til som vertikater som er begrensede i antall og kanter er forbindelseslinjene mellom to noder.
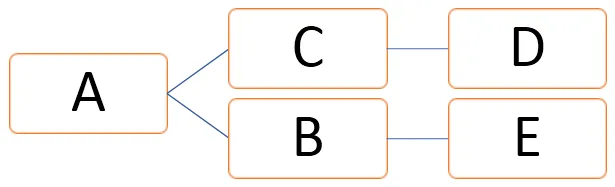
I grafen over kan vertices være representert som V = (A, B, C, D, E) og kanter kan defineres som
E = (AB, AC, CD, BE)
Hva er BFS-algoritmen?
Det er vanligvis to algoritmer som brukes til å krysse av en graf. De er algoritmer BFS (Breadth-First Search) og DFS (Depth First Search). Traversal of the Graph besøker nøyaktig en gang hver toppunkt eller node og kant, i en veldefinert rekkefølge. Det er også veldig viktig å følge med på toppunktene som har blitt besøkt, slik at det samme toppunktet ikke blir krysset to ganger. I Breath First Search-algoritmen starter traverseringen fra en valgt node eller kildeknute og gjennomgangen fortsetter gjennom nodene som er direkte koblet til kildeknuten. Enkelt sagt skal man i BFS-algoritmen først bevege seg horisontalt og krysse det gjeldende laget, hvoretter det skal flyttes til neste lag.
Hvordan fungerer BFS-algoritme?
La oss ta eksempelet på grafen nedenfor.
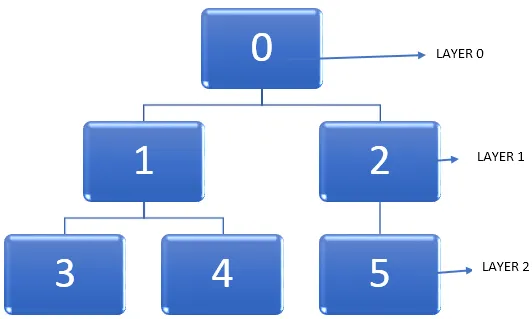
Den viktige oppgaven for hånden er å finne den korteste banen i en graf mens du krysser nodene. Når vi går gjennom en graf, går toppunktet fra uoppdaget tilstand til oppdaget tilstand og blir til slutt fullstendig oppdaget. Det skal bemerkes at det er mulig å sitte fast på et tidspunkt mens du går gjennom en graf og en node kan besøkes to ganger. Så vi kan bruke en metode for å merke noder etter at den endrer tilstanden til å være uoppdaget til å bli fullstendig oppdaget.
Vi kan se i bildet under at nodene kan markeres i grafene når de blir fullstendig oppdaget ved å merke dem med svart. Vi kan starte ved kildeknuten, og når traversalen går gjennom hver node, kan de merkes for å bli identifisert.
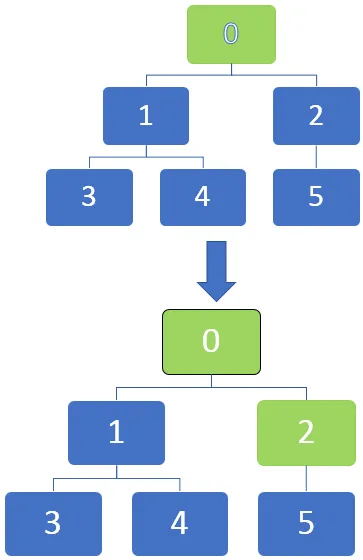
Traversalen starter fra et toppunkt og reiser deretter til utgående kanter. Når en kant går til et uoppdaget toppunkt, markeres det som oppdaget. Men når en kant går til et helt oppdaget eller oppdaget toppunkt, blir det ignorert.
For en rettet graf besøkes hver kant en gang, og for ikke-rettet graf besøkes den to ganger, dvs. en gang mens du besøker hver node. Algoritmen som skal brukes, avgjøres på bakgrunn av hvordan de oppdagede toppunktene lagres. I BFS-algoritmen brukes køen der den eldste toppunktet oppdages først og deretter forplanter seg gjennom lagene fra startpunktet.
Trinn utføres for en BFS-algoritme
Trinnene nedenfor utføres for en BFS-algoritme.
- I en gitt graf, la oss starte fra et toppunkt, dvs. i diagrammet ovenfor er det node 0. Nivået, der dette toppunktet er til stede, kan betegnes som lag 0.
- Neste trinn er å finne alle de andre toppunktene som ligger i tilknytning til startpunktet, dvs. node 0 eller umiddelbart tilgjengelig fra den. Så kan vi markere disse tilstøtende toppunktene for å være til stede på lag 1.
- Det er mulig å komme til samme toppunkt på grunn av en løkke i grafen. Så vi bør bare reise til de hjørnene som skal være til stede i samme lag.
- Deretter markeres foreldre toppunktet til det nåværende toppunktet som vi befinner oss på. Det samme skal utføres for alle toppunktene i lag 1.
- Så er neste trinn å finne alle de verticiene som ligger i en kant fra alle toppunktene som er i lag 1. Dette nye settet med toppunktene ligger på lag 2.
- Ovennevnte prosess blir gjentatt til alle nodene er krysset.
Eksempel:
La oss ta eksempelet på grafen nedenfor og forstå hvordan BFS-algoritmen fungerer. Generelt, i en BFS-algoritme, brukes en kø til å stille køene i kø mens du krysser nodene.
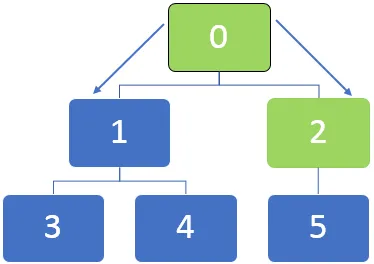
I grafen over skal først noden 0 besøkes, og denne noden blir satt i kø til underkøen:

Etter å ha besøkt noden 0, ligger naboteknoden 0, 1 og 2 i kø. Køen kan representeres som nedenfor: 
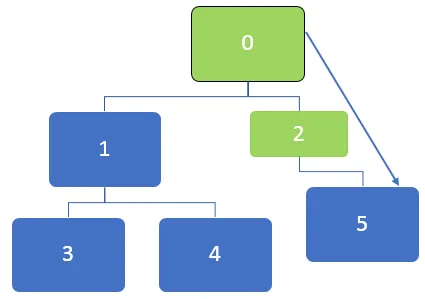
Da vil den første noden i køen som er 2 bli besøkt. Etter at node 2 er besøkt, kan køen bli representert som nedenfor:

Etter å ha besøkt noden 2, vil 5 være i kø, og da det ikke er noen ikke-oppsatte nærliggende noder for node 5, fremdeles om 5 er i kø, men det vil ikke bli besøkt to ganger.
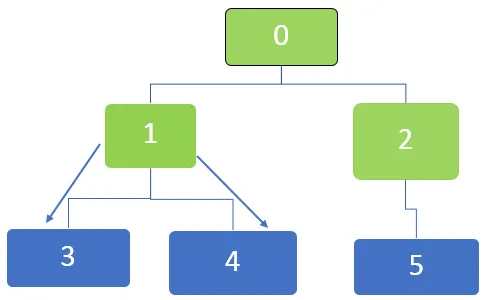
Deretter er den første noden i køen 1 som vil bli besøkt. Naboområdene 3 og 4 står i kø. Køen er representert som nedenfor

Dernest er den første noden i køen 5, og for denne noden er det ikke flere usynlige naboknuter. Det samme gjelder nodene 3 og 4 som det ikke er flere usynlige naboknuter også for.
Så alle nodene er krysset og til slutt blir køen tom.

Konklusjon
Breddsøkealgoritme har noen store fordeler å anbefale den. En av de mange applikasjonene til BFS-algoritmen er å beregne den korteste veien. Den brukes også i nettverk for å finne nabolandene og kan bli funnet på nettsteder med sosiale nettverk, kringkasting av nettverk og søppelinnsamling. Brukerne må forstå kravet og datamønsteret for å bruke det for bedre ytelse.
Anbefalte artikler
Dette har vært en guide til BFS-algoritmen. Her diskuterer vi konseptet, arbeid, trinn og eksempel på ytelse i BFS Algoritme. Du kan også gå gjennom andre foreslåtte artikler for å lære mer -
- Hva er en grådig algoritme?
- Ray Tracing Algoritm
- Digital signaturalgoritme
- Hva er Java Hibernate?
- Kryptografi av digital signatur
- BFS VS DFS | Topp 6 forskjeller med infografikk