
Introduksjon til forsterkningslæring
Forsterkningslæring er en type maskinlæring, og derfor er det også en del av kunstig intelligens. Når de brukes på systemer, utfører systemene trinn og lærer basert på utfallet av trinn for å oppnå et komplekst mål som er satt for at systemet skal oppnå.
Forstå forsterkningslæring
La oss prøve å arbeide for forsterkende læring ved hjelp av to enkle tilfeller:
Sak nr. 1
Det er en baby i familien og hun har nettopp begynt å gå og alle er ganske glade for det. En dag prøver foreldrene å sette seg et mål, la oss babyen komme i sofaen og se om babyen er i stand til det.
Resultat av sak 1: Babyen når vellykket sofaen og dermed er alle i familien veldig glade for å se dette. Den valgte banen kommer nå med en positiv belønning.
Poeng: Belønning + (+ n) → Positiv belønning.
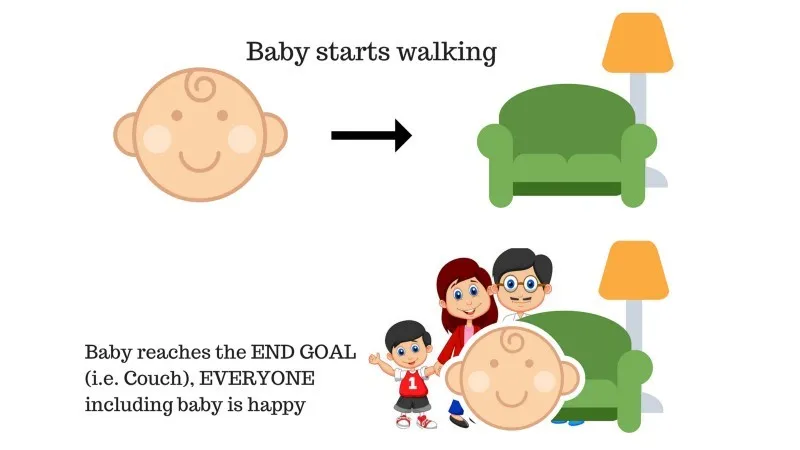
Kilde: https://images.app.goo.gl/pGCXJ1N1bzLAer126
Sak nr. 2
Babyen klarte ikke å nå sofaen, og babyen har falt. Det gjør vondt! Hva kan muligens være grunnen? Det kan være noen hindringer i veien til sofaen, og babyen hadde falt for hindringer.
Resultat av sak 2: Babyen faller på noen hindringer, og hun gråter! Å, det var ille, lærte hun, for ikke å falle i hinderfellen neste gang. Den valgte banen kommer nå med en negativ belønning.
Poeng: Belønning + (-n) → Negativ belønning.
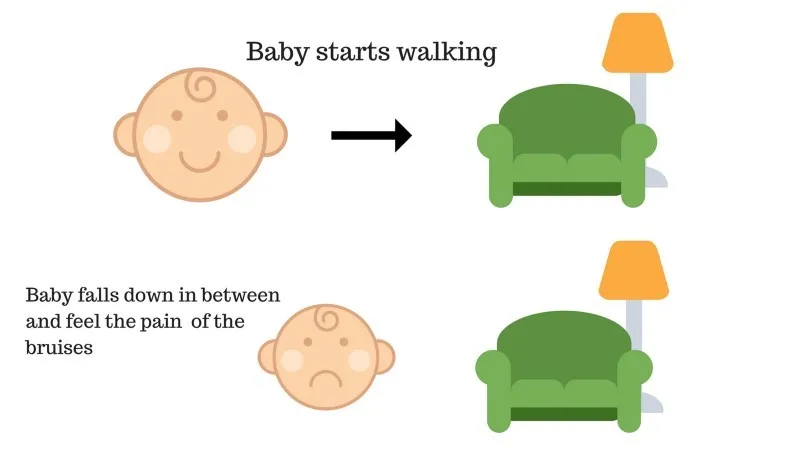
Kilde: https://images.app.goo.gl/FRfd8cUqrQRLe6sZ7
Dette har vi nå sett tilfeller 1 og 2, forsterkningslæring, i konsept, gjør det samme bortsett fra at det ikke er menneskelig, men i stedet utføres beregningsmessig.
Bruk av armering trinnvis
La oss forstå forsterkningsinnlæringen ved å bringe et forsterkningsagent på en trinnvis måte. I dette eksemplet er vår forsterkende læringsagent Mario, som vil lære å spille på egen hånd:
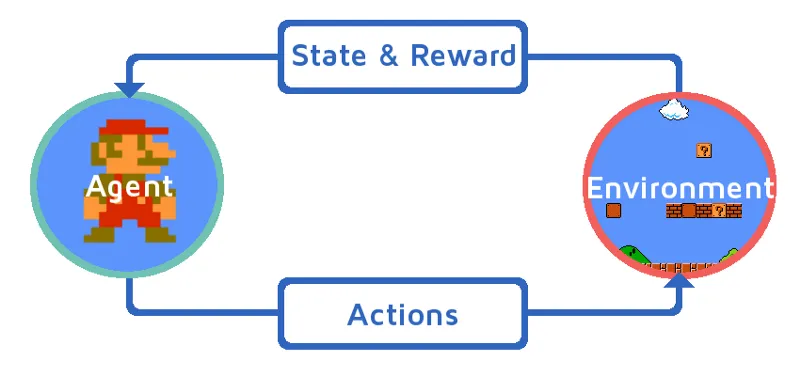
Kilde: https://images.app.goo.gl/Kj44uvBzWzMw1QzE9
- Den nåværende tilstanden til Mario-spillmiljøet er S_0. Fordi spillet ennå ikke har startet, og Mario er på sin plass.
- Deretter starter spillet og Mario beveger seg, Mario dvs. RL-agenten tar og handler, la oss si A_0.
- Nå er spillmiljøets tilstand blitt S_1.
- Også RL-agenten, dvs. Mario er nå tildelt et positivt belønningspunkt, R_1, sannsynligvis fordi Mario fremdeles er i live og det ikke var noen fare.
Nå vil ovennevnte sløyfe fortsette å løpe til Mario er endelig død eller Mario når sitt mål. Denne modellen vil kontinuerlig gi ut handlingen, belønningen og tilstanden.
Maksimal belønning
Målet med forsterkningslæring er å maksimere gevinsten ved å ta hensyn til visse andre faktorer som belønningsrabatten; vi vil kort forklare hva som menes med rabatten ved hjelp av en illustrasjon.
Den kumulative formelen for rabatterte belønninger er som:
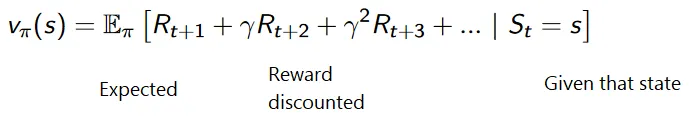
Rabattbelønning
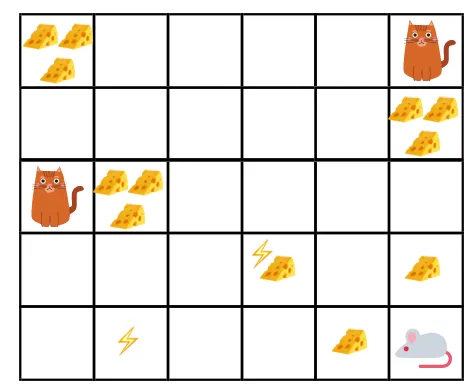
La oss forstå dette gjennom et eksempel:
- I den gitte figuren er målet, musen i spillet må spise like mye ost før den blir spist av en katt eller uten å bli elektrosjokket.
- Nå kan vi anta at jo nærmere vi er katten eller den elektriske fellen, jo større sannsynlighet for at musen blir spist eller sjokkert.
- Dette innebærer, selv om vi har full ost nær den elektriske støtblokken eller i nærheten av katten, jo mer risikabelt det er å dra dit, er det bedre å spise osten som er i nærheten for å unngå risiko.
- Så selv om vi har en "blokk1" med ost som er full og er langt fra katten og elektrosjokkblokken og den andre en "blokk2", som også er full, men enten er i nærheten av katt eller elektrisk støtblokk, den senere osteblokken, dvs. “block2”, vil være mer diskontert i belønning enn den forrige.
Kilde: https://images.app.goo.gl/8QrH78FjmRVs5Wxk8
Kilde: https://cdn-images-1.medium.com/max/800/1*l8wl4hZvZAiLU56hT9vLlg.png.webp
Typer forsterkningslæring
Nedenfor er de to typene forsterkningslæring med fordeler og ulemper:
1. Positiv
Når styrken og hyppigheten av atferden økes på grunn av forekomsten av en viss oppførsel, er det kjent som Positive Reinforcement Learning.
Fordeler: Ytelsen maksimeres, og endringen gjenstår i lengre tid.
Ulemper: Resultatene kan bli redusert hvis vi har for mye forsterkning.
2. Negativt
Det er styrking av atferd, mest på grunn av at det negative begrepet forsvinner.
Fordeler: Atferden økes.
Ulemper: Bare minimumsatferden til modellen kan nås ved hjelp av læring om negativ forsterkning.
Hvor forsterkningslæring skal bruke?
Ting som kan gjøres med forsterkningslæring / eksempler. Følgende er områdene der styrking læring brukes i disse dager:
- Helsevesen
- utdanning
- spill
- Datamaskin syn
- Bedriftsledelse
- Robotics
- Finansiere
- NLP (Natural Language Processing)
- Transport
- Energi
Karrierer innen forsterkningslæring
Det er faktisk en rapport fra jobbsiden, ettersom RL er en gren av maskinlæring, ifølge rapporten er maskinlæring den beste jobben i 2019. Nedenfor er øyeblikksbildet av rapporten. I henhold til dagens trender, kommer en maskinlæringsingeniør med en enorm gjennomsnittslønn på $ 146.085 og med en vekstrate på 344 prosent.
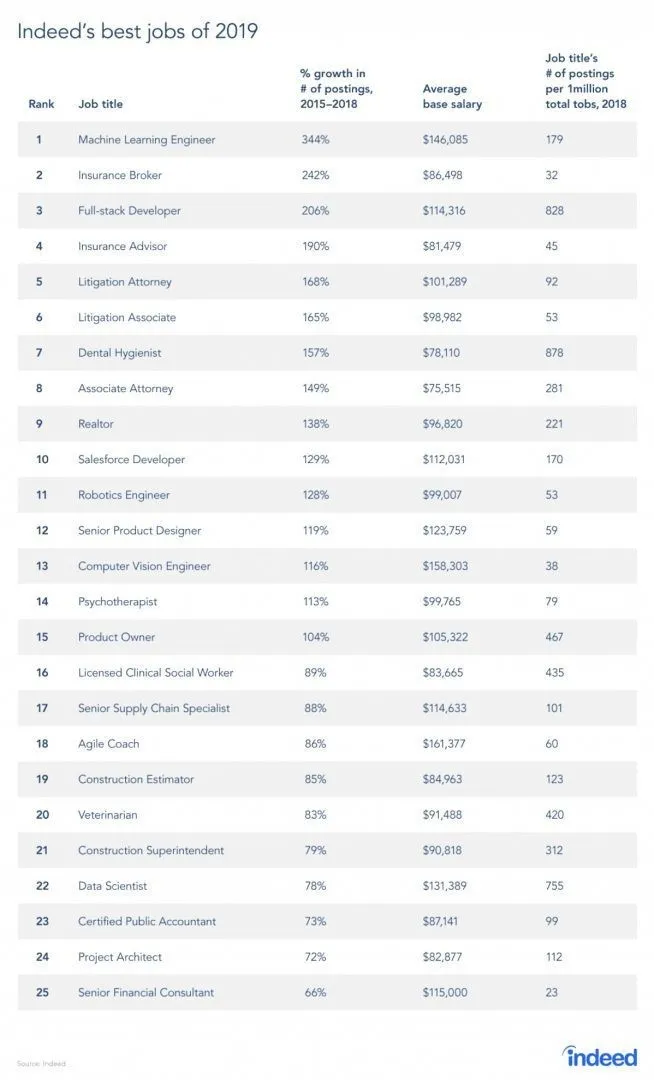
Kilde: https://i0.wp.com/www.artificialintelligence-news.com/wp-content/uploads/2019/03/indeed-top-jobs-2019-best.jpg.webp?w=654&ssl=1
Ferdigheter for forsterkningslæring
Nedenfor er ferdighetene som trengs for forsterkningslæring:
1. Grunnleggende ferdigheter
- Sannsynlighet
- Statistikk
- Datamodellering
2. Programmeringsferdigheter
- Grunnleggende om programmering og informatikk
- Design av programvare
- Kunne anvende Machine Learning-biblioteker og algoritmer
3. Programmeringsspråk for maskinlæring
- Python
- R
- Selv om det også er andre språk der Machine Learning-modeller kan utformes som Java, C / C ++, men Python og R er de mest foretrukne språkene som brukes.
Konklusjon
I denne artikkelen startet vi med en kort introduksjon om forsterkningslæring, og deretter dykket dypt ned i arbeidet med RL og ulike faktorer som er involvert i arbeidet med RL-modeller. Da hadde vi satt noen eksempler fra den virkelige verden for å forstå enda bedre om emnet. Mot slutten av denne artikkelen skal man ha god forståelse for arbeidet med forsterkningslæring.
Anbefalte artikler
Dette er en guide til Hva er forsterkningslæring? Her diskuterer vi funksjonen og ulike faktorer som er involvert i utviklingen av Reinforcement Learning-modeller, med eksempler. Du kan også gå gjennom andre relaterte artikler for å lære mer -
- Typer maskinlæringsalgoritmer
- Introduksjon til kunstig intelligens
- Kunstig intelligensverktøy
- IoT-plattformen
- Topp 6 maskinlæring programmeringsspråk