
Forskjellen mellom Hadoop og Redshift
Hadoop er et open source-rammeverk utviklet av Apache Software Foundation med de viktigste fordelene med skalerbarhet, pålitelighet og distribuert databehandling. Databehandling, lagring, tilgang, sikkerhet er flere typer funksjoner som er tilgjengelige på Hadoop Ecosystem. HDFS har en høy gjennomstrømning som betyr å kunne håndtere store datamengder med parallell prosesseringsevne. Redshift er en nettsky-webtjeneste utviklet av Amazon Web Services-enheten innen Amazon.com Inc., av eksisterende tjenester levert av Amazon. Det brukes til å designe et datalager i stor skala i skyen. Redshift er en datalager-tjeneste i petabyte-skala som er fullstendig administrert og kostnadseffektiv å operere på store datasett.
La oss studere mer om Hadoop og Redshift i detalj:
Hadoop HDFS har høy feiltoleranseevne og ble designet for å kjøre på rimelige maskinvaresystemer. Hadoop kan håndtere en minimumstørrelse på TeraBytes til GigaBytes av filer i systemet. HDFS er master-slave-arkitektur som består av Navnekoder og Datakoder der Navneknuten inneholder metadata og Dataknuten inneholder reelle data som skal behandles eller opereres.
RedShift bruker forskjellige datainnlastingsteknikker som BI (Business Intelligence) rapportering, analyseverktøy og data mining. Redshift gir en konsoll for å opprette og administrere Amazon Redshift-klynger. Kjernekomponenten i Redshift Data Warehouse er en klynge.
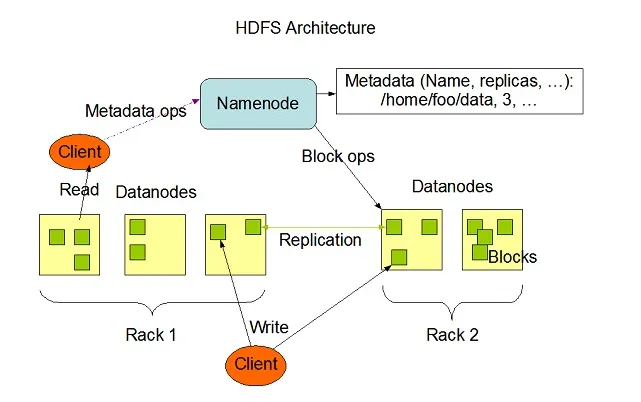
Bildekilde: Apache.org
RedShift-arkitektur:
 Bildekilde: Amazon.com
Bildekilde: Amazon.com
Sammenligning fra topp mot hodet mellom Hadoop vs Redshift (Infographics):
Nedenfor er topp 10-sammenligningen mellom Hadoop og Redshift som følger

Viktige forskjeller mellom Hadoop vs Redshift:
Nedenfor er nøkkelforskjellene mellom Hadoop vs Redshift som følger
1. Hadoop HDFS (Hadoop Distribuerte filsystem) -arkitektur har navnnoder og datakoder, mens Redshift har ledernode og beregningsnoder der Compute-noder blir delt inn som skiver.
2. Hadoop tilbyr kommandolinjegrensesnitt for å samhandle med filsystem, mens RedShift har administrasjonskonsoll for å samhandle med Amazon-lagringstjenester som S3, DynamoDB etc.,
3.Databaseoperasjonene skal konfigureres av utviklere. I Redshift automatiserer databaseoperasjonene ved å analysere utførelsesplanene.
4.Hadoop har flere tredjepartsverktøystøtter som enkelt kan integreres, mens Redshift kun støtter produktene som er utviklet av Amazon i skyen.
5. Når det gjelder Hadoop arkitektonisk design, har nettverk, lagring, sikkerhet og ytelse blitt ansett som primære elementer, mens i Redshift disse elementene enkelt og fleksibelt kan konfigureres ved bruk av Amazon cloud management konsoll.
6.Hadoop er en filsystemarkitektur basert på Java Application Programming Interfaces (API) mens Redshift er basert på Relational model Database Management System (RDBMS).
7.Hadoop kan ha integrasjoner med forskjellige leverandører og Redshift har ingen støtte i dette tilfellet der Amazon er deres eneste leverandør. Hva om en bruker er misfornøyd med tjenesten? I dette tilfellet er Hadoop en fordel.
8. De fleste av de eksisterende selskapene bruker fortsatt Hadoop, mens nye kunder velger RedShift.
9. Når det gjelder ytelse, mangler alltid Hadoop bak og Redshift vinner alltid i tilfelle utførelse av spørringer på store datamengder.
10.Hadoop bruker Map Reduce programmeringsmodell for å kjøre jobber. Amazon Redshift bruker Amazons Elastic Map Reduce.
11.Hadoop bruker Map Reduce programmeringsmodell for å kjøre jobber. Amazon Redshift bruker Amazons Elastic Map Reduce.
12.Hadoop foretrekker å kjøre batchjobber daglig som blir billigere, mens Redshift kommer billigere ut i tilfelle Online Analytical Processing (OLAP) -teknologi som finnes bak mange Business Intelligence-verktøy.
13.Hadoop er 10 ganger saktere enn Redshift når det gjelder å kjøre spørsmål på lignende måte Hadoop er 10 ganger dyrere enn Redshift, noe som resulterer i at Hadoop ble minst valgt før Redshift.
14. Når det gjelder datainnlasting, har Hadoop også stått bak Redshift når det tar timer fra systemet for å laste inn data fra lagringen i filbehandlingssystemet.
15..Hadoop kan brukes til rimelige lagringer, dataarkivering, datasjøer, datavarehus og dataanalyse, mens Redshift kommer inn under Datavarehusfunksjoner som forårsaker å begrense bruken av flere formål.
16..Hadoop-plattformen gir støtte til forskjellige eksterne leverandører og egne Apache-prosjekter som Storm, Spark, Kafka, Solr etc., og på den andre siden har Redshift begrenset integrasjonsstøtte med sine eneste Amazon-produkter
Sammenligningstabel Hadoop vs Redshift
| BASIS FOR
SAMMENLIGNING | Hadoop | rødforskyvning |
| Tilgjengelighet | Open Source Framework av Apache Projects | Prisgitte tjenester levert av Amazon |
| Gjennomføring | Levert av Hortonworks og Cloudera leverandører etc., | Utviklet og levert av Amazon |
| Opptreden | Hadoop MapReduce-jobbene går tregere | Redshift presterer raskere enn Hadoop-klyngen |
| skalerbarhet | Begrensninger i skalerbarhet | Lett være nede / oppdateres som per krav |
| Priser | Koster $ 200 per måned for å kjøre spørsmål | Pris avhenger av serverområdet og billigere enn Hadoop
F.eks: $ 20 / måned |
| Hastighet | Raskere men tregere sammenlignet med Redshift | 10 ganger raskere enn Hadoop |
| Spørringshastighet | Det tar 1491 sekunder å kjøre 1.2 TB data | 155 sekunder for å kjøre 1, 2 TB data |
| Dataintegrasjon | Fleksibel med lokalt filsystem og hvilken som helst database | Kan bare laste inn data fra Amazon S3 eller DynamoDB |
| Dataformat | Alle dataformater støttes | Strengt i dataformater som CSV-filformater |
| Brukervennlighet | Kompleks og vanskeligere å håndtere administrasjonsaktiviteter | Automatisk sikkerhetskopiering og datavarehusadministrasjon |
Konklusjon - Hadoop vs Redshift
Den endelige uttalelsen for å konkludere med den store vinneren i denne sammenligningen er Redshift som vinner med tanke på brukervennlighet, vedlikehold og produktivitet, mens Hadoop mangler når det gjelder ytelses skalerbarhet og tjenestekostnadene med den eneste fordelen av enkel integrasjon med tredjepartsverktøy og produkter. Redshift har nylig utviklet seg med enorm vekst og aksept av mange kunder og kunder på grunn av den høye tilgjengeligheten og mindre driftskostnader sammenlignet med Hadoop gjør det mer og mer populært. Men til nå har de fleste av de eksisterende Fortune 1000-selskapene brukt Hadoop-plattformer i sine arkitekturer for å administrere kundedataene.
I de fleste tilfeller har RedShift vært det beste valget å vurdere for forretningsmessige formål av enhver klient eller kunde for å håndtere de store og sensitive dataene fra finansinstitusjoner eller offentlig informasjon med større dataintegritet og sikkerhet.
Bortsett fra dette har Hadoop sine egne fordeler ved å være åpen kildekode-prosjekt og hadde vært tilgjengelig i mange år også føre til at eksisterende systemer ble erstattet som en kostnadsforløpende prosess. Produktet bør endelig velges basert på krav og fleksibilitet i stedet for priser eller popularitet basert på de drevne forretningsbehovene.
Anbefalt artikkel:
Dette har vært en guide til Hadoop vs Redshift, deres betydning, sammenligning mellom hodet og hodet, nøkkelforskjeller, sammenligningstabell og konklusjon. Du kan også se på følgende artikler for å lære mer -
- Hadoop vs Hive - Finn ut de beste forskjellene
- HADOOP vs RDBMS | Vet de 12 nyttige forskjellene
- Apache Hadoop vs Apache Spark | Topp 10 sammenligninger du må vite!
- Big Data vs Data Science - Hvordan er de forskjellige?
- Guide on Hadoop vs Spark
- Topp 4 Cloud Hosting-leverandører med funksjoner