

Introduksjon til Apache Flume
Apache Flume er Data Ingestion Framework som skriver hendelsesbaserte data til Hadoop Distribuerte filsystem. Det er et kjent faktum at Hadoop behandler Big data, det oppstår spørsmål hvordan dataene som genereres fra forskjellige webservere blir overført til Hadoop File System? Svaret er Apache Flume. Flume er designet for inntak av høyt volum til Hadoop av hendelsesbaserte data.
Tenk på et scenario der antall webservere genererer loggfiler og disse loggfilene må overføres til Hadoop-filsystemet. Flume samler filene som hendelser og tar dem inn i Hadoop. Selv om Flume brukes til å overføre til Hadoop, er det ingen stiv regel om at destinasjonen må være Hadoop. Flume er i stand til å skrive til andre rammer som Hbase eller Solr.
Flume Arkitektur
Generelt er Apache Flume-arkitekturen sammensatt av følgende komponenter:
- Flume Source
- Flume Channel
- Flume Vask
- Flume Agent
- Flume-arrangement
La oss ta en kort titt på hver Flume-komponent
1. Flume Source
En Flume Source er til stede på datageneratorer som Face book eller Twitter. Kilde samler inn data fra generatoren og overfører disse dataene til Flume Channel i form av Flume Events. Flume støtter forskjellige typer kilder, for eksempel Avro Flume Source - kobles til Avro-porten og mottar hendelser fra Avro ekstern klient, Thrift Flume Source-kobles til Thrift-porten og mottar hendelser fra eksterne Thrift-klientstrømmer, Spooling Directory Source og Kafka Flume Source.
2. Flume Channel
En mellomlager som bufferer hendelsene som er sendt av Flume Source til de blir konsumert av Sink, kalles Flume Channel. Channel fungerer som en mellombro mellom Source og Sink. Flume-kanaler har transaksjonell karakter.
Flume gir støtte for filkanalen og minnekanalen. Filkanalen er holdbar av natur som betyr at når dataene er skrevet til kanal vil de ikke gå tapt, selv om agenten starter på nytt. I Memory lagres kanalhendelser i minnet, så det er ikke holdbart, men veldig raskt av natur.
3. Flume Vask
En Flume Sink er til stede på dataregister som HDFS, HBase. Flume sink forbruker hendelser fra Channel og lagrer dem til destinasjonsbutikker som HDFS. Det er ingen regel slik at vasken skal levere hendelser til Store, i stedet kan vi konfigurere den på en slik måte at vasken kan levere hendelser til en annen agent. Flume støtter forskjellige vasker som HDFS Sink, Hive Sink, Thrift Sink, Avro Sink.
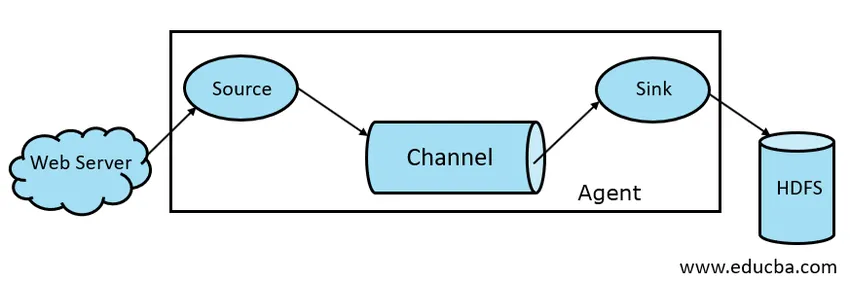
Fig 1.1 Basic Flume Architecture
4. Flume Agent
En Flume-agent er en langvarig Java-prosess som kjører på Source - Channel - Sink Combination. Flume kan ha mer enn ett middel. Vi kan betrakte Flume som en samling av tilkoblede Flume-midler som er distribuert i naturen.
5. Flume-hendelse
En hendelse er den dataenheten som transporteres i Flume . Generell representasjon av Data Object i Flume kalles Event. Arrangementet består av en nyttelast av en byte-gruppe med valgfrie overskrifter.
Working of Flume
En Flume-agent er en java-prosess som består av Source - Channel - Sink i sin enkleste form. Kilde samler inn data fra datagenerator i form av Hendelser og leverer dem til Channel. En kilde kan levere til flere kanaler i henhold til krav. Fan out er prosessen der en enkelt kilde vil skrive til flere kanaler slik at de kan levere til flere vasker.
En hendelse er den grunnleggende dataenheten som overføres i Flume. Channel buffer dataene til den blir inntatt av Sink. Sink samler inn dataene fra Channel og leverer dem til sentralisert datalagring som HDFS eller Sink kan videresende at hendelser til et annet Flume-agent i henhold til krav.
Flume støtter transaksjoner. For å oppnå pålitelighet bruker Flume separate transaksjoner fra kilde til kanal og fra kanal til vask. Hvis hendelser ikke blir levert, blir transaksjonen rullet tilbake og senere levert på nytt.
For å forstå bruken av Flume, la oss ta et eksempel på Flume-konfigurasjon der kilden er spooling-katalog og sink er Hdfs. I dette eksemplet er Flume-middel i den enkleste formen, dvs. enkel kilde - kanal - synketopologi som er konfigurert ved hjelp av en javaegenskapsfil.
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /tmp/spooldir
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /tmp/flume
agent1.channels.channel1.type = file
I konfigurasjonseksemplet ovenfor er agent basen som vi definerer andre egenskaper med. source1 og sink1 og channel1 er navnene på henholdsvis kilde, vask og kanal, og deres typer og beliggenhet er også nevnt tilsvarende.
Fordeler med Apache Flume
- Flume er skalerbar, pålitelig og feiltolerant. Disse egenskapene blir diskutert i detalj nedenfor
- Skalerbar - Flume er skalerbar horisontalt, dvs. at vi kan legge til nye noder i henhold til kravet vårt
- Pålitelig - Apache Flume har støtte for transaksjoner og sikrer at ingen data går tapt i prosessen med dataoverføring. Det har forskjellige transaksjoner fra kilde til kanal og fra kanal til kilde.
- Flume kan tilpasses og gir støtte for forskjellige kilder og vasker som Kafka, Avro, spooling directory, Thrift etc
- I Flume kan enkeltkilde overføre data til flere kanaler, og disse kanalene vil på sin side overføre dataene til flere synker, og dermed kan én kilde overføre data til flere synker. Denne mekanismen kalles Fan out. Flume støtter også for vifte ute.
- Flume gir en jevn flyt av dataoverføring, dvs. hvis datahastigheten øker og datahastigheten også øker.
- Selv om Flume generelt skriver data til sentralisert lagring som HDFS eller Hbase, kan vi konfigurere Flume etter vårt krav slik at Sink kan skrive data til en annen agent. Dette viser Flume fleksibilitet
- Apache Flume er åpen kildekode i naturen.
Konklusjon
I denne Flume-artikkelen blir komponenter av Flume og bearbeiding av Flume diskutert i detalj. Flume er en fleksibel, pålitelig og skalerbar plattform for overføring av data til en sentralisert butikk som HDFS. Evnen til å integrere med forskjellige applikasjoner som Kafka, Hdfs, Thrift gjør det til et levedyktig alternativ for inntak av data.
Anbefalte artikler
Dette har vært en guide til Apache Flume. Her diskuterer vi arkitektur, arbeid og fordeler med Apache Flume. Du kan også se på følgende artikler for å lære mer -
- Hva er Apache Flink?
- Forskjellen mellom Apache Kafka vs Flume
- Big Data Architecture
- Hadoop Tools
- Lær de forskjellige JavaScript-hendelsene