

Forskjeller mellom til Sqoop og Flume
Sqoop er et produkt fra Apache-programvare. Sqoop henter ut nyttig informasjon fra Hadoop og overføres deretter til de eksterne datalagrene. Ved hjelp av Sqoop kan vi importere data fra en RDBMS eller mainframe til HDFS. Flume er også fra Apache-programvare. Den samler og flytter rekursive data som blir generert. Apache Flume er ikke bare begrenset til loggdatasamling, men datakilder kan tilpasses, og dermed kan Flume brukes til å transportere enorme datamengder. Den beste måten å samle inn, samle og flytte store datamengder mellom Hadoop Distribuert File System og RDBMS er ved å bruke verktøy som Sqoop eller Flume.
La oss diskutere disse to ofte brukte verktøyene for ovennevnte formål.
Hva er Sqoop
For å bruke Sqoop, må en bruker spesifisere verktøyet brukeren vil bruke og argumentene som kontrollerer det bestemte verktøyet. Du kan også eksportere dataene tilbake til en RDBMS ved å bruke Sqoop. Eksportfunksjonaliteten til Sqoop brukes til å hente ut nyttig informasjon fra Hadoop og eksportere dem til de eksterne strukturerte datalagrene. Det fungerer med forskjellige databaser som Teradata, MySQL, Oracle, HSQLDB.
- Sqoop Architecture: -
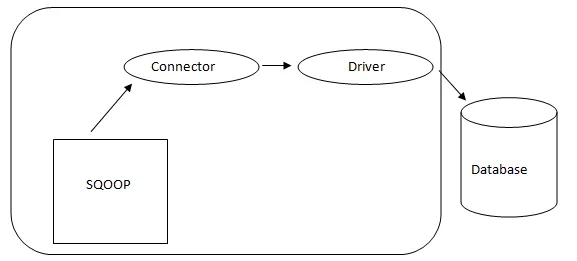
Arkitektur av Sqoop
Koblingen i en Sqoop er en plugin for en bestemt databasekilde, så det er grunnleggende at det er et stykke Sqoop-etablering. Til tross for at drivere er databasespesifikke brikker og distribueres av forskjellige databaseleverandører, kommer Sqoop selv sammen med forskjellige typer kontakter som brukes til utbredt database- og informasjonslagersystem. Dermed sendes Sqoop med et blandet utvalg av kontakter også ut av esken. Sqoop gir en pluggbar komponent for et ideelt nettverk og eksternt system. Sqoop API gir en nyttig struktur for montering av nye kontakter, og derfor kan alle databasekontakter slippes i Sqoop-installasjonen for å gi tilkobling til forskjellige datasystemer.
Hva er Flume
Apache Flume er ikke bare begrenset til loggdatasamling, men datakilder kan tilpasses, og dermed kan Flume brukes til å transportere enorme mengder data, inkludert, men ikke begrenset til, e-postmeldinger, sosiale medier genererte data, nettverkstrafikkdata og ganske mye datakilde mulig.
Flume-arkitektur: - Flume-arkitektur er basert på mange kjernekonsepter:
- Flume Event- det er representert som en enhet for flytende data, som har en byte nyttelast og sett med strenger med valgfrie strengoverskrifter. Flume anser en hendelse som bare en generisk byte.
- Flume Agent- Det er en JVM-prosess som er vert for komponentene som kanaler, vask og kilder. Det har potensial til å motta, lagre og videresende hendelsene fra en ekstern kilde til neste nivå.
- Flume Flow - det er tidspunktet hendelsen blir generert.
- Flume Client - det refererer til grensesnittet der klienten opererer på opprinnelsesstedet for hendelsen og leverer det til Flume-agenten.
- Kilde - En kilde er en som forbruker hendelser med et spesifikt format og leverer det via en spesifikk mekanisme.
- Channel - Det er en passiv butikk der det arrangeres arrangementer til vasken fjerner den for videre transport.
- Sink - Den fjerner hendelsen fra en kanal og legger den på et eksternt depot som HDFS. Den støtter for øyeblikket å lage tekst- og sekvensfiler og støtter komprimering i begge filtyper.
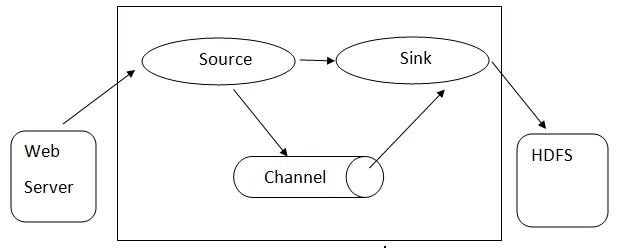
Arkitektur av Flume
Head to Head Sammenligning mellom Sqoop vs Flume (Infographics)
Nedenfor er topp 7-sammenligningen mellom Sqoop vs Flume

Viktige forskjeller mellom Sqoop vs Flume
Vi vet nå at det er mange forskjeller mellom Sqoop vs Flume, her er de viktigste forskjellene mellom dem gitt nedenfor -
1. Sqoop er designet for å utveksle masseinformasjon mellom Hadoop og Relational Database.
Mens Flume brukes til å samle inn data fra forskjellige kilder som genererer data angående en spesiell brukssak og deretter overføre denne store datamengden fra distribuerte ressurser til et enkelt sentralisert depot.
2. Sqoop inkluderer også et sett med kommandoer som lar deg inspisere databasen du jobber med. Dermed kan vi betrakte Sqoop som en samling relaterte verktøy.
Mens samlingen av datoen Flume skalerer dataene horisontalt og flere Flume-midler kan settes i verk for å samle datoen og samle dem. Deretter blir datalogger flyttet til et sentralisert datalager, dvs. Hadoop Distribuert filsystem (HDFS).
3. Nøkkelfaktoren for å bruke Flume er at dataene må genereres kontinuerlig og strømming. Tilsvarende er Sqoop den best egnede i situasjoner når dataene dine lever i databasesystemer som MySQL, Oracle, Teradata, PostgreSQL
Sqoop vs Flume (sammenligningstabell)
| Grunnlag for sammenligning | SQOOP | Flume |
|
Grunnleggende natur | Sqoop fungerer bra med alle RDBMS som har JDBC (Java Database Connectivity) som Oracle, MySQL, Teradata, etc. | Flume fungerer bra for Streaming datakilde som kontinuerlig genererer for eksempel logger, JMS, katalog, krasjrapporter, etc. |
| Dataflyt | Sqoop spesielt brukt for parallell dataoverføring. Av denne grunn kan utskriften være i flere filer | Flume brukes til å samle og samle data på grunn av sin distribuerte natur. |
| Drevne hendelser | Sqoop er ikke drevet av hendelser. | Flume er helt hendelsesdrevet. |
| Arkitektur | Sqoop følger koblingsbasert arkitektur, som betyr kontakter, vet hvordan du kobler til en annen datakilde. | Flume følger agentbasert arkitektur, der koden som er skrevet i den er kjent som en agent som er ansvarlig for å hente data. |
| Hvor skal du bruke | Brukes primært til å kopiere data raskere og deretter bruke dem til å generere analytiske utfall. | Brukes vanligvis til å trekke data når bedrifter ønsker å analysere mønstre, årsaker eller sentimentanalyse ved hjelp av logger og sosiale medier. |
| Opptreden | Det reduserer overdreven lagrings- og prosesseringsbelastning ved å overføre dem til andre systemer og har rask ytelse. | Flume er feiltolerant, robust og har en holdbar pålitelighetsmekanisme for failover og utvinning. |
| Slipphistorie | Den første versjonen av Apache Sqoop ble lansert i mars 2012. Den nåværende stabile utgivelsen er 1.4.7 | Den første stabile versjonen 1.2.0 av Apache Flume ble lansert i juni 2012. Den nåværende stabile utgivelsen er Apache Flume versjon 1.8.0. |
Konklusjon - Sqoop vs Flume
Som du lærte over Sqoop og Flume, er det hovedsakelig to datainntrekkverktøy som er Big Data-verdenen. Hvis du trenger å innta tekstlige loggdata i Hadoop / HDFS, er Flume det riktige valget for å gjøre det. Hvis dataene dine ikke blir generert regelmessig, vil Flume fortsatt fungere, men det vil være en overkill for den situasjonen. Tilsvarende er Sqoop ikke den beste passformen for hendelsesstyrt datahåndtering.
Anbefalte artikler
Dette har vært en guide til forskjeller mellom Sqoop vs Flume, deres betydning, sammenligning av hode til hode, nøkkelforskjeller, sammenligningstabell og konklusjon. denne artikkelen består av alle nyttige forskjeller mellom Sqoop og Flume. Du kan også se på følgende artikler for å lære mer
- Hadoop vs Teradata-Nyttige forskjeller å lære
- 5 Den viktigste forskjellen mellom Apache Kafka vs Flume
- Big Data vs Apache Hadoop - Topp 4 sammenligning du må lære
- 5 Den viktigste forskjellen mellom Apache Kafka vs Flume
- Viktig tekst gruvedrift vs naturlig språkbehandling - Topp 5 sammenligninger