

Introduksjon til Delta i Spark SQL
Som vi vet blir sammenføyningene i SQL brukt til å kombinere data eller rader fra to eller flere tabeller basert på et felles felt mellom dem. I dette emnet skal vi lære om Bli medlem i Spark SQL Delta i Spark SQL.
I Spark SQL er Dataframe eller Dataset en tabellstruktur i minnet som har rader og kolonner som er fordelt over flere noder. Som vanlige SQL-tabeller, kan vi også utføre sammenkoblingsoperasjoner på Dataframe eller Datasett som er til stede i Spark SQL basert på et felles felt mellom dem.
Det er forskjellige typer Join-operasjoner som er tilgjengelige i SQL. Avhengig av sak om bruk av virksomheten, velger vi å delta i operasjonen. I den følgende delen skal vi demonstrere hver type sammenføyning med eksempel.
Typer Delta i Spark SQL
Følgende er de forskjellige typer sammenføyninger som er tilgjengelige i Spark SQL:
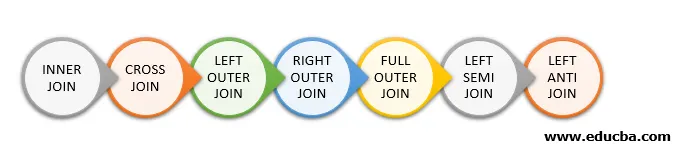
- INNERLEDNING
- CROSS JOIN
- VENSTRE YTRE BLI MED
- HØYRE YTRE BLI MED
- FULL YTRE BLI MED
- VENSTRE SEMI BLI MED
- VENSTRE ANTI BLI MED
Eksempel på oppretting av data
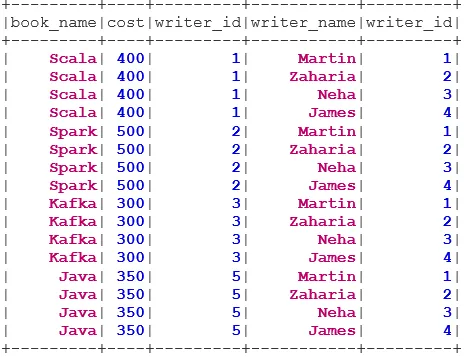
Vi vil bruke følgende data for å demonstrere de forskjellige typer sammenføyninger:
Book datasett:
case class Book(book_name: String, cost: Int, writer_id:Int)
val bookDS = Seq(
Book("Scala", 400, 1),
Book("Spark", 500, 2),
Book("Kafka", 300, 3),
Book("Java", 350, 5)
).toDS()
bookDS.show()

Writer Datasett:
case class Writer(writer_name: String, writer_id:Int)
val writerDS = Seq(
Writer("Martin", 1),
Writer("Zaharia " 2),
Writer("Neha", 3),
Writer("James", 4)
).toDS()
writerDS.show()

Typer skjøter
Nedenfor er nevnt 7 forskjellige typer sammenføyninger:
1. INNERLEDNING
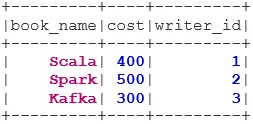
INNER JOIN returnerer datasettet som har radene som har samsvarende verdier i begge datasettene, dvs. at verdien til fellesfeltet vil være den samme.
val BookWriterInner = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "inner")
BookWriterInner.show()

2. KRYSSELEDNING
CROSS JOIN returnerer datasettet som er antall rader i det første datasettet multiplisert med antall rader i det andre datasettet. Slikt resultat kalles det kartesiske produktet.
Forutsetning: For å bruke en kryssforbindelse, må spark.sql.crossJoin.enabled være satt til true. Ellers vil unntaket bli kastet.
spark.conf.set("spark.sql.crossJoin.enabled", true)
val BookWriterCross = bookDS.join(writerDS)
BookWriterCross.show()
3. VENSTRE YTRE JOIN
LEFT OUTER JOIN returnerer datasettet som har alle rader fra det venstre datasettet, og de matchede rader fra høyre datasett.
val BookWriterLeft = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftouter")
BookWriterLeft.show()

4. HØYRE YTRE JOIN
RIGHT OUTER JOIN returnerer datasettet som har alle rader fra høyre datasett, og de matchede rader fra venstre datasett.
val BookWriterRight = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "rightouter")
BookWriterRight.show()

5. FULL YTTERLEDNING
FULL OUTER JOIN returnerer datasettet som har alle rader når det er en match i enten det venstre eller høyre datasettet.
val BookWriterFull = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "fullouter")
BookWriterFull.show()

6. VENSTRE SEMI BLI MED
VENSTRE SEMI JOIN returnerer datasettet som har alle rader fra venstre datasett med korrespondanse i høyre datasett. I motsetning til LEFT OUTER JOIN, inneholder det returnerte datasettet i LEFT SEMI JOIN bare kolonnene fra det venstre datasettet.
val BookWriterLeftSemi = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftsemi")
BookWriterLeftSemi.show()
7. VENSTRE ANTI BLI MEDLEM
ANTI SEMI JOIN returnerer datasettet som har alle radene fra det venstre datasettet som ikke har samsvaret i det rette datasettet. Den inneholder også bare kolonnene fra det venstre datasettet.
val BookWriterLeftAnti = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftanti")
BookWriterLeftAnti.show()

Konklusjon - Bli med på Spark SQL
Å bli med i data er en av de vanligste og viktigste operasjonene for å oppfylle saken vår om forretningsbruk. Spark SQL støtter alle grunnleggende typer sammenføyninger. Når vi blir med, må vi også vurdere ytelse, da de kan kreve store nettverksoverføringer eller til og med lage datasett utover vår evne til å håndtere. For forbedring av ytelsen bruker Spark SQL-optimalisator til å bestille eller filtere ned. Gnist begrenser også farlig join i. e KRYSSELEDNING. For å bruke en kryssforbindelse, må spark.sql.crossJoin.enabled være satt eksplisitt.
Anbefalte artikler
Dette er en guide for å delta i Spark SQL. Her diskuterer vi de forskjellige typer sammenføyninger som er tilgjengelige i Spark SQL med eksemplet. Du kan også se på den følgende artikkelen.
- Typer sammenføyninger i SQL
- Tabell i SQL
- SQL Sett inn spørring
- Transaksjoner i SQL
- PHP-filtre | Hvordan validerer brukerinndata ved hjelp av forskjellige filtre?