
Forskjellen mellom Hive og HBase
Apache Hive og HBase er Hadoop-baserte big data-teknologier. De pleide begge å spørre data. Hive og HBase kjører på toppen av Hadoop, og de har forskjellig funksjonalitet. Hive er kartredusert SQL-dialekt mens HBase kun støtter MapReduce. HBase lagrer data i form av nøkkel / verdi eller kolonnefamiliepar, mens Hive ikke lagrer data.
Forskjeller fra hodet til hodet mellom Hive vs HBase (Infographics)
Nedenfor er topp 8 forskjellen mellom Hive vs HBase
Viktige forskjeller mellom Hive vs HBase
- Hbase er en ACID-kompatibel, mens Hive ikke er det.
- Hive støtter partisjonering og filterkriterier basert på datoformatet, mens HBase støtter automatisk partisjonering.
- Hive støtter ikke oppdateringsuttalelser mens HBase støtter dem.
- Hbase er raskere sammenlignet med Hive når du henter data.
- Hive brukes til å behandle strukturerte data, mens HBase siden den er skjemafri, kan behandle alle typer data.
- Hbase er svært (horisontalt) skalerbar sammenlignet med Hive.
- Hive analyserer dataene på HDFS med støtte fra SQL Queries, og deretter konverterer de dette til et kart og reduserer jobber, mens det i Hbase siden det er streaming i sanntid, utfører sine operasjoner direkte i databasen ved å partisjonere til tabeller og kolonnefamilier.
- når du kommer til spørring av datakule bruker et skall kjent som Hive shell for å utstede kommandoene mens HBase siden det er database vil vi bruke en kommando til å behandle dataene i HBase.
- For å gå til Hive-skallet vil vi bruke kommando-bikuben. Etter å ha gitt dette vil det se ut som bikube>. I HBase gir vi ganske enkelt som Bruk HBase.
Hive vs HBase-sammenligningstabell
| Grunnlag for sammenligning | Hive | Hbase |
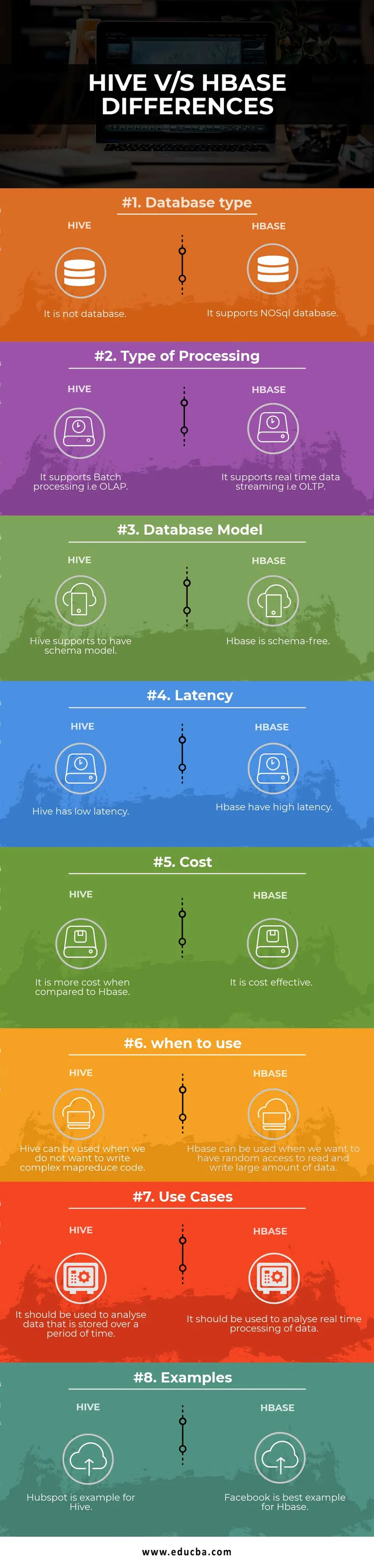
| Databasetype | Det er ikke en database | Den støtter NoSQL-database |
| Type behandling | Den støtter batchbehandling dvs. OLAP | Den støtter datastrømming i sanntid dvs. OLTP |
| Databasemodell | Hive støtter å ha skjemamodell | Hbase er skjemafri |
| Ventetid | Hive har lav latens | Hbase har høy latens |
| Koste | Det er mer kostbart sammenlignet med HBase | Det er kostnadseffektivt |
| når du skal bruke den | Hive kan brukes når vi ikke vil skrive kompleks MapReduce-kode | HBase kan brukes når vi vil ha tilfeldig tilgang til å lese og skrive en stor datamengde |
| Bruk saker | Den skal brukes til å analysere data som er lagret over en periode | Det skal brukes til å analysere sanntidsbehandling av data. |
| eksempler | Hubspot er et eksempel for Hive | Facebook er det beste eksemplet for Hbase |
Forskjeller i koding mellom Hive vs HBase
La oss nå diskutere de grunnleggende forskjellene mellom Hive og HBase i koding.
| Grunnlag for sammenligning | Hive | Hbase |
| For å opprette en database | SKAP DATABASE (HVIS IKKE EKSISTERER) DATABASE-NAVN; | Siden Hbase er en database trenger vi ikke lage en spesifikk database |
| Slik slipper du en database | DROP DATABASE (HVIS EKSISTER) DATABASE-NAME (RESTRICT ELLER CASCADE); | NA |
| Slik lager du en tabell | OPPRETT (MIDLERTIDIG ELLER EKSTERN) BORD (HVIS IKKE EKSISTERER) TABLENAVN ((kolonne-navn data_type (Kommentar kolonne-kommentar), ….)) (Kommentar tabell_kommentar) (ROW FORMAT radformat) (Lagret som filformat) | SKAPE '', '' |
| Å endre et bord | ALTER TABELL navn RENAME TO new-name
ALTER TABELL navn DROP (COLUMN) kolonnenavn ALTER TABELL Navn LEGG TIL KOLUMMER (col-spec (, col-spec ..)) ALTER TABELL navn ENDRE kolonne-navn new-name new-type ALTER TABELnavn Byt ut COLUMNS (col-spec (, col-spec ..)) | ALTER 'TABLE-NAME', NAME => 'COLUMN-NAME', VERSIONS => |
| Deaktivering av et bord | NA | deaktiver 'TABLE-NAME' -> for å deaktivere spesifisert tabellnavn
deaktivere_all 'r *' -> for å deaktivere alle tabellene som samsvarer med det vanlige uttrykket |
| Aktivering av et bord | NA | aktiver "TABLE-NAME" |
| Å slippe et bord | DROP TABELL HVIS EKSISTERER tabellnavn | Hvis vi vil slippe et bord, må vi først deaktivere det
deaktiver 'tabellnavn' slipp 'tabellnavn' På samme måte kan vi bruke disable_all og drop_all for å slette tabellene som samsvarer med det spesifiserte regulære uttrykket. |
| For å liste opp databaser | vise databaser; | NA |
| For å liste tabeller i databasen | vise tabeller; | liste |
| For å beskrive skjema for en tabell | beskrive tabellenavn; | beskriv "tabellenavn" |
Integrering av Hive vs HBase
- Installer og konfigurer Hive.
- Installer og konfigurer HBase.
- For integrering av både Hive og HBase bruker vi STORAGE HANDLERS i Hive.
- Storage Handlers er en kombinasjon av SERDE, InputFormat, OutputFormat som godtar enhver ekstern enhet som en tabell i Hive.
- Så denne funksjonen hjelper en bruker til å gi ut SQL-spørringer, enten i tabellen som finnes i Hadoop eller i NOSQL-basert database som HBase, MongoDB, Cassandra, Amazon DynamoDB.
- Nå skal vi se på ett eksempel for å koble Hive med HBase ved bruk av HiveStorageHandler:
- Først må vi lage Hbase-tabellen ved å bruke kommandoen.
opprett 'Student', 'personalinfo', 'avd.info'
-> Personalinfo og avd. Info oppretter to forskjellige kolonnefamilier i Studenttabellen.
- Vi må sette inn noen data i studenttabellen. For eksempel, som nevnt nedenfor.
sette 'student', 'sid01 ′, ' personalinfo: navn ', ' ram '
sette 'student', 'sid01 ′, ' personalinfo: mailid ', ' postbeskyttet '
sett 'student', 'sid01 ′, ' deptinfo: deptname ', ' Java '
sette 'Student', 'sid01 ′, ' deptinfo: joinyear ', ' 1994 ′
-> På samme måte kan vi lage data for sid02, sid03 …
- Nå må vi lage Hive-tabell som peker til HBase-tabellen.
- For hver kolonne i Hbase vil vi opprette en bestemt tabell for den kolonnen i Hive. I dette tilfellet vil vi lage 2 tabeller i Hive
create external table student_hbase(sid String, name String, mailid String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler with serdeproperties("hbase.columns.mapping"=":key, personalinfo:name, personalinfo:mailid")
tblproperties("hbase.table.name"="student");
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
-> Tilsvarende må vi lage informasjon om tabellen for informasjon om avdeling i bikuben.
- Nå kan vi skrive SQL-spørring i en bikube som nevnt nedenfor.
select * from student_hbase;
På denne måten kan vi integrere Hive med HBase.
Konklusjon - Hive vs HBase
Som diskutert er de begge forskjellige teknologier som gir forskjellige funksjoner der Hive fungerer ved å bruke SQL-språk, og det kan også kalles som HQL og HBase bruker nøkkelverdipar for å analysere dataene. Hive og HBase fungerer bedre hvis de kombineres fordi Hive har lav latens og kan behandle en enorm datamengde, men ikke kan opprettholde oppdaterte data, og HBase støtter ikke analyse av data, men støtter oppdateringer på radnivå på en stor mengde av data.
Anbefalt artikkel
Dette har vært en guide til Hive vs HBase, deres betydning, sammenligning mellom hodet og hodet, nøkkelforskjeller, sammenligningstabell og konklusjon. Du kan også se på følgende artikler for å lære mer -
- Apache Pig vs Apache Hive - Topp 12 nyttige forskjeller
- Finn ut de 7 beste forskjellene mellom Hadoop vs HBase
- Topp 12 sammenligning av Apache Hive vs Apache HBase (Infographics)
- Hadoop vs Hive - Finn ut de beste forskjellene