

Forskjellen mellom MapReduce og Spark
Map Reduce er et rammeverk med åpen kildekode for å skrive data til HDFS og behandle strukturerte og ustrukturerte data som finnes i HDFS. Map Reduce er begrenset til batchbehandling og på andre kan Spark utføre alle typer behandlinger. SPARK er en uavhengig prosesseringsmotor for sanntidsbehandling som kan installeres på et hvilket som helst distribuert filsystem som Hadoop. SPARK gir en ytelse som er 10 ganger raskere enn Map Reduce på disken og 100 ganger raskere enn Map Reduce på et nettverk i minnet.
Need For SPARK
- Iterativ analyse: Kartredusering er ikke så effektiv som en SPARK for å løse problemer som krever iterativ analyse som det må gå til disk for hver iterasjon.
- Interaktiv Analytics: Kart-redusering brukes ofte til å kjøre ad-hoc-spørsmål som den trenger for å komme til på minnet som igjen ikke er så effektivt som SPARK fordi sistnevnte refererer til i minnet som er raskere.
- Ikke egnet for OLTP: Siden det fungerer på det batchorienterte rammeverket, er det ikke egnet for et stort antall av den korte transaksjonen.
- Ikke egnet for graf: Apache Graph-biblioteket behandler grafen som tilfører Map Reduce mer kompleksitet.
- Ikke egnet for trivielle operasjoner: For operasjoner som et filter og blir med må vi kanskje skrive om jobbene, noe som blir mer komplisert på grunn av nøkkelverdimønsteret.
Sammenligning mellom hodet og hodet mellom MapReduce vs Spark (Infographics)
Nedenfor er topp 15 forskjellen mellom MapReduce og Spark

Viktige forskjeller mellom MapReduce vs Spark
Nedenfor er listen over punkter, som beskriver de viktigste forskjellene mellom MapReduce og Spark:
- Gnist er egnet for sanntid når den behandler ved å bruke i minnet, mens MapReduce er begrenset til batchbehandling.
- Spark har RDD (Resilient Distribuerte Datasett) som gir oss operatører på høyt nivå, men i Map reduksjon må vi kode hver eneste operasjon som gjør det relativt vanskelig.
- Spark kan behandle grafer og støtter maskinens læringsverktøy.
- Nedenfor er forskjellen mellom MapReduce vs Spark økosystem.
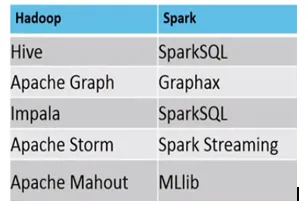
Eksempel, der MapReduce vs Spark er egnet, er som følger
Gnist: Registrering av kredittkortsvindel
MapReduce: Lagelse av regelmessige rapporter som krever beslutninger.
MapReduce vs Spark Comparision Table
| Grunnlag for sammenligning | Kart reduksjon | Gnist |
| Work | Et open-source rammeverk for å skrive data til HDFS og behandle strukturerte og ustrukturerte data som finnes i HDFS. | Et open source-rammeverk for raskere og generell databehandling |
| Hastighet | Kart-reduser behandle dataene (leser og skriv) fra disken slik at sippet går sakte sammenlignet med Spark. | Gnist er minst 10 ganger raskere på disken og 100 ganger raskere i minnet som Map Reduce. |
| Vanskelighet | Vi må kode / håndtere hver prosess. | Med tilgjengeligheten til RDD (Resilient Distribuerte datasett), er det enkelt å programmere. |
| Real-Time | Ikke egnet for OLTP-transaksjoner bare for batchmodus | Den kan håndtere sanntidsbehandlingen. Bruker SPARK Streaming. |
| Ventetid | Beregningsramme på høyt nivå | Beregningsramme for lavt nivå på latens. |
| Feiltoleranse | Master-demoner sjekker hjerterytmen til slavedemoner og i tilfelle slavedemoner mislykkes, masterdemoner planlegger alle de verserende og pågående operasjoner til en annen slave. | RDD's gir feiltoleranse for SPARK. De viser til datasettet som finnes i ekstern lagring som (HDFS, HBase) og fungerer parallelt. |
| planlegger | I Map Reduce bruker vi en ekstern planlegger som Oozie. | Ettersom SPARK arbeider med dataminne i minnet, fungerer det som sin egen planlegger. |
| Koste | Map Reduce er relativt billigere enn SPARK. | Som det fungerer i minnet, så det krever mye RAM, noe som gjør det relativt kostbart. |
| Plattform utviklet på | Map Reduce er utviklet ved hjelp av Java. | SPARK er utviklet ved bruk av Scala. |
| Støttet språk | Map Reduce støtter i utgangspunktet C, C ++, Ruby, Groovy, Perl, Python. | Spark støtter Scala, Java, Python, R, SQL. |
| SQL-støtte | Map Reduce kjører spørsmål ved hjelp av Hive Query Language. | Spark har sitt eget spørrespråk kjent som Spark SQL. |
| skalerbarhet | I Map Reduce kan vi legge til et antall noder. Den største Hadoop Cluster har 14000 noder. | I Spark kan vi også legge til et antall noder. Den største gnistklyngen har 8000 noder. |
| Maskinlæring | Map Reduce støtter Apache Mahout-verktøy for maskinlæring. | Spark støtter MLlib-verktøy for maskinlæring. |
| caching | Kartreduksjon kan ikke buffer i minnedata, så de går ikke så raskt i forhold til Spark. | Spark lagrer data i minnet for ytterligere iterasjoner, så det er veldig raskt sammenlignet med Map Reduce. |
| Sikkerhet | Map Reduce støtter flere sikkerhetsprosjekter og funksjoner i forhold til Spark | Gnistsikkerhet er ennå ikke modnet som Map Reduce |
Konklusjon - MapReduce vs Spark
I henhold til ovennevnte forskjell mellom MapReduce og Spark, er det ganske tydelig at SPARK er en mye mer avansert datamaskin sammenlignet med Map Reduce. Spark er kompatibel med alle typer filformater og er også ganske raskere enn Map Reduce. Gnisten i tillegg har også grafbehandling og maskinlæring.
På den ene siden er Map Reduce begrenset til batchbehandling, og på den andre er Spark i stand til å utføre alle typer behandlinger (batch, interaktiv, iterativ, streaming, graf). På grunn av stor kompatibilitet er Spark favoritten til Data Scientist, og dermed erstatter det Map Reduce og vokser raskt. Men fortsatt må vi lagre dataene i HDFS, og vi kan også en eller annen gang trenge HBase. Så vi trenger å kjøre både Spark og Hadoop for å bli best mulig.
Anbefalte artikler:
Dette har vært en guide til MapReduce vs Spark, deres betydning, sammenligning mellom hodet og hodet, viktige forskjeller, sammenligningstabell og konklusjon. Du kan også se på følgende artikler for å lære mer -
- 7 viktige ting om Apache Spark (guide)
- Hadoop vs Apache Spark - Interessante ting du trenger å vite
- Apache Hadoop vs Apache Spark | Topp 10 sammenligninger du må vite!
- Hvordan MapReduce fungerer?
- Sammenflytning av teknologi og forretningsanalyse