

Introduksjon til data mining
Dette er en data mining-metode som brukes til å plassere dataelementer i lignende grupper. Cluster er prosedyren for å dele dataobjekter i underklasser. Clustering kvalitet avhenger av metoden som vi brukte. Clustering kalles også datasegmentering ettersom store datagrupper er delt etter deres likhet.
Hva er gruppering i data mining?
Clustering er gruppering av spesifikke objekter basert på deres egenskaper og likheter. Når det gjelder data mining, deler denne metodikken dataene som er best egnet til ønsket analyse ved hjelp av en spesiell sammenføyningsalgoritme. Denne analysen gjør at et objekt ikke skal være del eller strengt tatt en del av en klynge, som kalles den harde partisjoneringen av denne typen. Glatte partisjoner antyder imidlertid at hvert objekt i samme grad tilhører en klynge. Mer spesifikke inndelinger kan opprettes som objekter av flere klynger, en enkelt klynge kan tvinges til å delta eller til og med hierarkiske trær kan konstrueres i gruppeforhold. Dette filsystemet kan settes på plass på forskjellige måter basert på forskjellige modeller. Disse distinkte algoritmene gjelder for hver modell, og skiller både egenskapene og resultatene. En god grupperingsalgoritme er i stand til å identifisere klyngen uavhengig av klyngeformen. Det er tre grunnleggende trinn i gruppering algoritmen som er vist som nedenfor
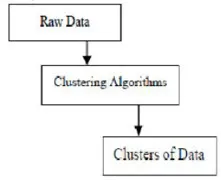
Clustering algoritmer i data mining
Avhengig av klyngemodeller som nylig er beskrevet, kan mange klynger brukes til å dele opp informasjon i et sett med data. Det skal sies at hver metode har sine egne fordeler og ulemper. Valg av en algoritme avhenger av egenskapene og arten av datasettet.
Clustering Methods for Data Mining kan vises som nedenfor
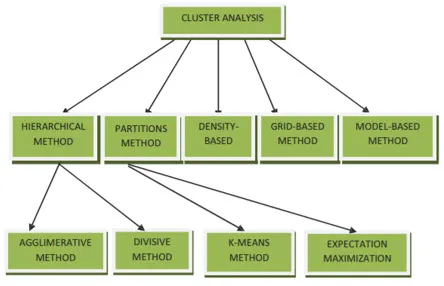
- Partisjonsbasert metode
- Tetthetsbasert metode
- Centroid-basert metode
- Hierarkisk metode
- Rutenettbasert metode
- Modellbasert metode
1. Partisjonsbasert metode
Partisjonsalgoritmen deler data inn i mange undergrupper.
La oss anta at partisjonsalgoritmen bygger partisjon av data ettersom k og n er objekter som er til stede i databasen. Derfor blir hver partisjon representert som k ≤ n.
Dette gir en ide om at klassifiseringen av dataene er i k-grupper, som kan vises nedenfor
Figur 1 viser originale punkter i klynger

Figur 2 viser partisjonsklynging etter anvendelse av en algoritme
Dette indikerer at hver gruppe har minst ett objekt, så vel som hvert objekt, må tilhøre nøyaktig en gruppe.
2. Tetthetsbasert metode
Disse algoritmene produserer klynger på et bestemt sted basert på den høye tettheten av datasettdeltakere. Den samler noen rekkevidde for gruppemedlemmer i klynger til et standardnivå for tetthet. Slike prosesser kan utføre mindre når det gjelder å oppdage gruppens overflateområder.
3. Centroid-basert metode
Nesten hver klynge er referert til av en vektor av verdier i denne typen os-grupperingsteknikker. Sammenlignet med andre klynger er hvert objekt en del av klyngen med en minste forskjell i verdi. Antall klynger bør forhåndsdefineres, og dette er det største algoritmeproblemet av denne typen. Denne metodikken er det nærmeste identifikasjonsfaget og brukes mye til optimaliseringsproblemer.
4. Hierarkisk metode
Metoden vil lage en hierarkisk nedbrytning av et gitt sett med dataobjekter. Basert på hvordan den hierarkiske nedbrytningen dannes, kan vi klassifisere hierarkiske metoder. Denne metoden er gitt som følger
- Agglomerativ tilnærming
- Delende tilnærming
Agglomerativ tilnærming er også kjent som Button-up Approach. Her begynner vi med hvert objekt som utgjør en egen gruppe. Det fortsetter å smelte sammen gjenstander eller grupper
Divisive Approach er også kjent som Top-Down Approach. Vi begynner med alle objektene i samme klynge. Denne metoden er stiv, det vil si at den aldri kan angre når en fusjon eller deling er fullført
5. Nettbasert metode
Rutenettbaserte metoder fungerer i objektområdet i stedet for å dele dataene i et rutenett. Rutenett er delt ut basert på dataene. Ved å bruke denne metoden er ikke-numeriske data enkle å administrere. Datarekkefølge påvirker ikke partisjoneringen av nettet. En viktig fordel med en nettbasert modell det gir raskere utføringshastighet.
Fordelene med hierarkisk klynging er som følger
- Det er aktuelt for alle attributtype.
- Det gir fleksibilitet relatert til granularitetsnivået.
6. Modellbasert metode
Denne metoden bruker en antatt modell basert på sannsynlighetsfordeling. Ved å gruppere tetthetsfunksjonen, lokaliserer denne metoden klyngene. Det gjenspeiler datapunktenes romlige fordeling.
Anvendelse av klynger i Data Mining
Clustering kan hjelpe på mange felt som biologi, planter og dyr klassifisert etter deres egenskaper så vel som i markedsføring. Clustering vil bidra til å identifisere kunder til en viss kundepost med lignende oppførsel. I mange applikasjoner, for eksempel markedsundersøkelser, mønstergjenkjenning, data og bildebehandling, brukes klyngeanalysen i stort antall. Clustering kan også hjelpe annonsører i deres kundegrunnlag å finne forskjellige grupper. Og kundegruppene deres kan defineres ved å kjøpe mønstre. I biologi brukes den til bestemmelse av taksonomier for planter og dyr, for kategorisering av gener med lignende funksjonalitet og for innsikt i bestandsarmerende strukturer. I en jordobservasjonsdatabase gjør klynger det også lettere å finne områder med lignende bruk i landet. Det hjelper til med å identifisere grupper av hus og leiligheter etter type, verdi og destinasjon av hus. Klynge av dokumenter på nettet er også nyttig for å oppdage informasjon. Klyngeanalysen er et verktøy for å få innsikt i distribusjonen av data for å observere egenskapene til hver klynge som en data mining-funksjon.
Konklusjon
Clustering er viktig i data mining og dens analyse. I denne artikkelen har vi sett hvordan clustering kan gjøres ved å bruke forskjellige grupperingsalgoritmer så vel som bruken av det i det virkelige liv.
Anbefalt artikkel
Dette har vært en guide til What is Clustering in Data Mining. Her diskuterte vi begrepene, definisjonen, funksjonene, anvendelsen av Clustering i Data Mining. Du kan også gå gjennom andre foreslåtte artikler for å lære mer -
- Hva er databehandling?
- Hvordan bli en dataanalytiker?
- Hva er SQL-injeksjon?
- Definisjon av hva er SQL Server?
- Oversikt over Data Mining Architecture
- Clustering in Machine Learning
- Hierarkisk Clustering Algorithm
- Hierarkisk klynging | Agglomerative & Divisive Clustering